 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedAdOb: Privacy-Preserving Federated Deep Learning with Adaptive Obfuscation
Jun 03, 2024Federated learning (FL) has emerged as a collaborative approach that allows multiple clients to jointly learn a machine learning model without sharing their private data. The concern about privacy leakage, albeit demonstrated under specific conditions, has triggered numerous follow-up research in designing powerful attacking methods and effective defending mechanisms aiming to thwart these attacking methods. Nevertheless, privacy-preserving mechanisms employed in these defending methods invariably lead to compromised model performances due to a fixed obfuscation applied to private data or gradients. In this article, we, therefore, propose a novel adaptive obfuscation mechanism, coined FedAdOb, to protect private data without yielding original model performances. Technically, FedAdOb utilizes passport-based adaptive obfuscation to ensure data privacy in both horizontal and vertical federated learning settings. The privacy-preserving capabilities of FedAdOb, specifically with regard to private features and labels, are theoretically proven through Theorems 1 and 2. Furthermore, extensive experimental evaluations conducted on various datasets and network architectures demonstrate the effectiveness of FedAdOb by manifesting its superior trade-off between privacy preservation and model performance, surpassing existing methods.
FedPass: Privacy-Preserving Vertical Federated Deep Learning with Adaptive Obfuscation
Jan 31, 2023



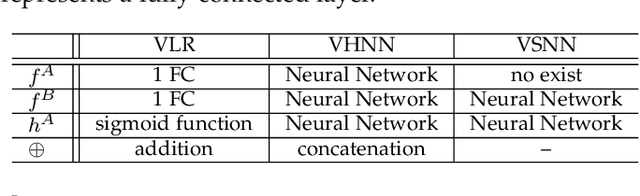
Vertical federated learning (VFL) allows an active party with labeled feature to leverage auxiliary features from the passive parties to improve model performance. Concerns about the private feature and label leakage in both the training and inference phases of VFL have drawn wide research attention. In this paper, we propose a general privacy-preserving vertical federated deep learning framework called FedPass, which leverages adaptive obfuscation to protect the feature and label simultaneously. Strong privacy-preserving capabilities about private features and labels are theoretically proved (in Theorems 1 and 2). Extensive experimental result s with different datasets and network architectures also justify the superiority of FedPass against existing methods in light of its near-optimal trade-off between privacy and model performance.
A Framework for Evaluating Privacy-Utility Trade-off in Vertical Federated Learning
Sep 09, 2022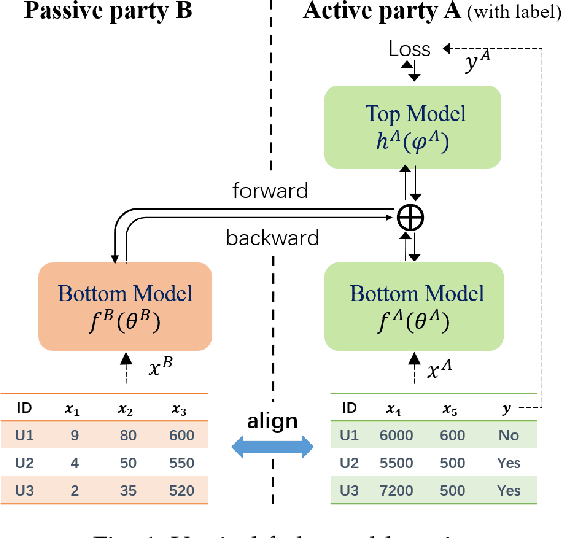

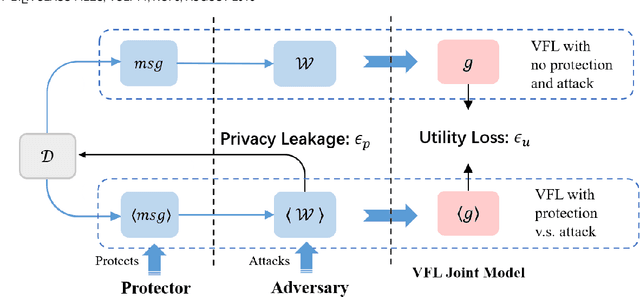
Federated learning (FL) has emerged as a practical solution to tackle data silo issues without compromising user privacy. One of its variants, vertical federated learning (VFL), has recently gained increasing attention as the VFL matches the enterprises' demands of leveraging more valuable features to build better machine learning models while preserving user privacy. Current works in VFL concentrate on developing a specific protection or attack mechanism for a particular VFL algorithm. In this work, we propose an evaluation framework that formulates the privacy-utility evaluation problem. We then use this framework as a guide to comprehensively evaluate a broad range of protection mechanisms against most of the state-of-the-art privacy attacks for three widely-deployed VFL algorithms. These evaluations may help FL practitioners select appropriate protection mechanisms given specific requirements. Our evaluation results demonstrate that: the model inversion and most of the label inference attacks can be thwarted by existing protection mechanisms; the model completion (MC) attack is difficult to be prevented, which calls for more advanced MC-targeted protection mechanisms. Based on our evaluation results, we offer concrete advice on improving the privacy-preserving capability of VFL systems.
A Hybrid Self-Supervised Learning Framework for Vertical Federated Learning
Aug 18, 2022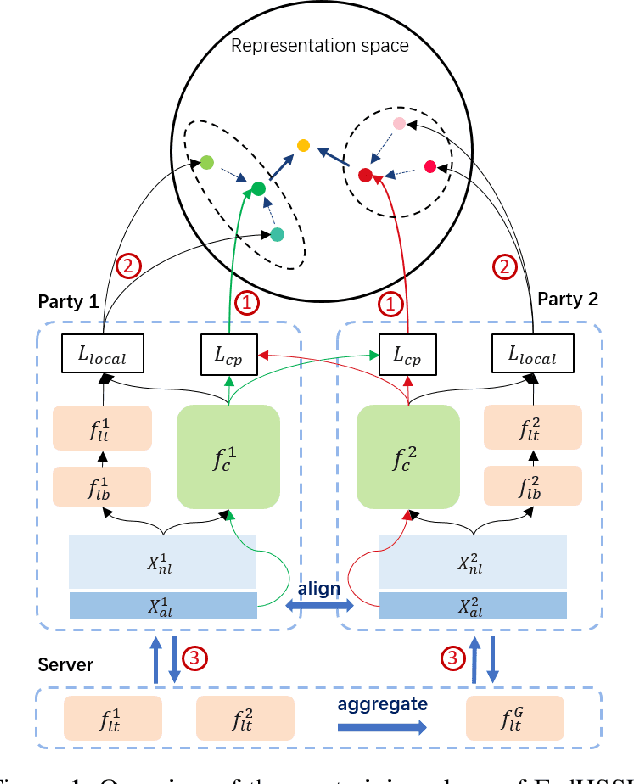


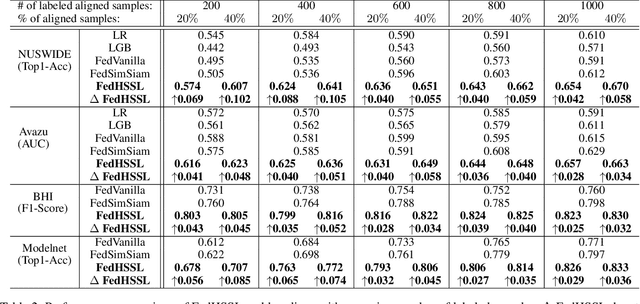
Federated learning (FL) enables independent parties to collaboratively build machine learning (ML) models while protecting data privacy. Vertical federated learning (VFL), a variant of FL, has recently drawn increasing attention as the VFL matches the enterprises' demands of leveraging more valuable features to achieve better model performance without jeopardizing data privacy. However, conventional VFL may run into data deficiency as it is only able to exploit aligned samples (belonging to different parties) with labels, leaving often the majority of unaligned and unlabeled samples unused. The data deficiency hampers the effort of the federation. In this work, we propose a Federated Hybrid Self-Supervised Learning framework, coined FedHSSL, to utilize all available data (including unaligned and unlabeled samples) of participants to train the joint VFL model. The core idea of FedHSSL is to utilize cross-party views (i.e., dispersed features) of samples aligned among parties and local views (i.e., augmentations) of samples within each party to improve the representation learning capability of the joint VFL model through SSL (e.g., SimSiam). FedHSSL further exploits generic features shared among parties to boost the performance of the joint model through partial model aggregation. We empirically demonstrate that our FedHSSL achieves significant performance gains compared with baseline methods, especially when the number of labeled samples is small. We provide an in-depth analysis of FedHSSL regarding privacy leakage, which is rarely discussed in existing self-supervised VFL works. We investigate the protection mechanism for FedHSSL. The results show our protection can thwart the state-of-the-art label inference attack.
FedCG: Leverage Conditional GAN for Protecting Privacy and Maintaining Competitive Performance in Federated Learning
Nov 16, 2021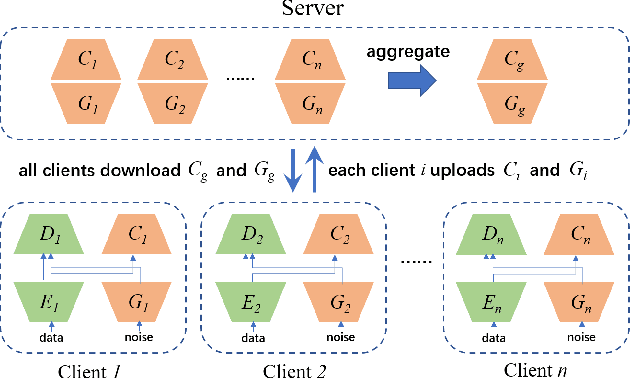
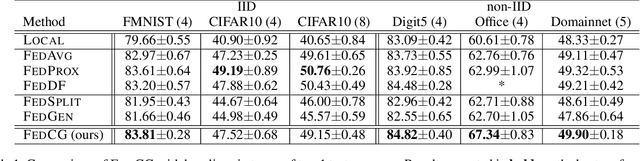
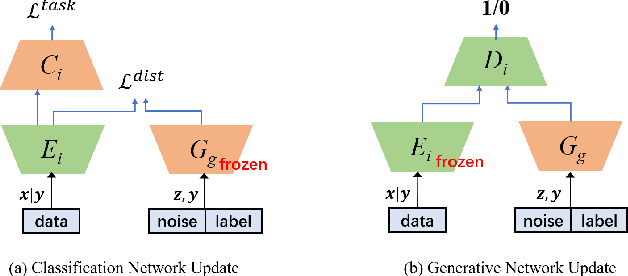

Federated learning (FL) aims to protect data privacy by enabling clients to collaboratively build machine learning models without sharing their private data. However, recent works demonstrate that FL is vulnerable to gradient-based data recovery attacks. Varieties of privacy-preserving technologies have been leveraged to further enhance the privacy of FL. Nonetheless, they either are computational or communication expensive (e.g., homomorphic encryption) or suffer from precision loss (e.g., differential privacy). In this work, we propose \textsc{FedCG}, a novel \underline{fed}erated learning method that leverages \underline{c}onditional \underline{g}enerative adversarial networks to achieve high-level privacy protection while still maintaining competitive model performance. More specifically, \textsc{FedCG} decomposes each client's local network into a private extractor and a public classifier and keeps the extractor local to protect privacy. Instead of exposing extractors which is the culprit of privacy leakage, \textsc{FedCG} shares clients' generators with the server for aggregating common knowledge aiming to enhance the performance of clients' local networks. Extensive experiments demonstrate that \textsc{FedCG} can achieve competitive model performance compared with baseline FL methods, and numerical privacy analysis shows that \textsc{FedCG} has high-level privacy-preserving capability.
Self-supervised Cross-silo Federated Neural Architecture Search
Feb 18, 2021
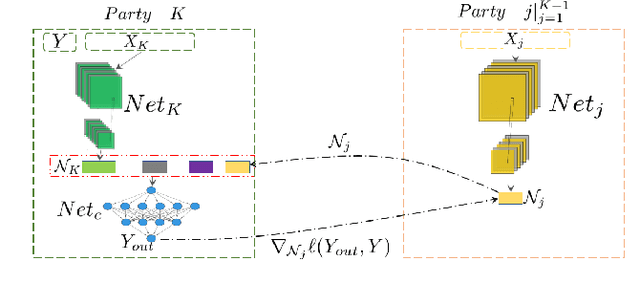
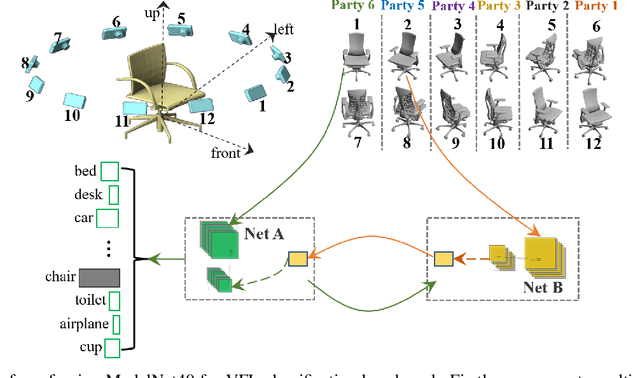
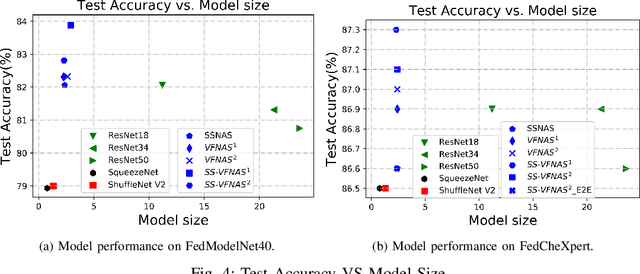
Federated Learning (FL) provides both model performance and data privacy for machine learning tasks where samples or features are distributed among different parties. In the training process of FL, no party has a global view of data distributions or model architectures of other parties. Thus the manually-designed architectures may not be optimal. In the past, Neural Architecture Search (NAS) has been applied to FL to address this critical issue. However, existing Federated NAS approaches require prohibitive communication and computation effort, as well as the availability of high-quality labels. In this work, we present Self-supervised Vertical Federated Neural Architecture Search (SS-VFNAS) for automating FL where participants hold feature-partitioned data, a common cross-silo scenario called Vertical Federated Learning (VFL). In the proposed framework, each party first conducts NAS using self-supervised approach to find a local optimal architecture with its own data. Then, parties collaboratively improve the local optimal architecture in a VFL framework with supervision. We demonstrate experimentally that our approach has superior performance, communication efficiency and privacy compared to Federated NAS and is capable of generating high-performance and highly-transferable heterogeneous architectures even with insufficient overlapping samples, providing automation for those parties without deep learning expertise.
Real-World Image Datasets for Federated Learning
Oct 14, 2019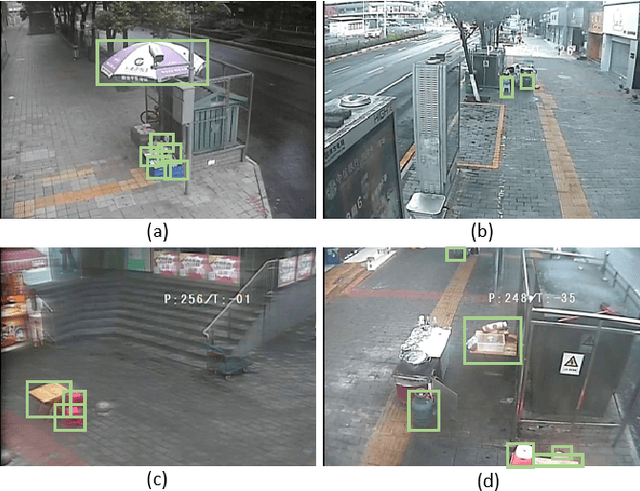
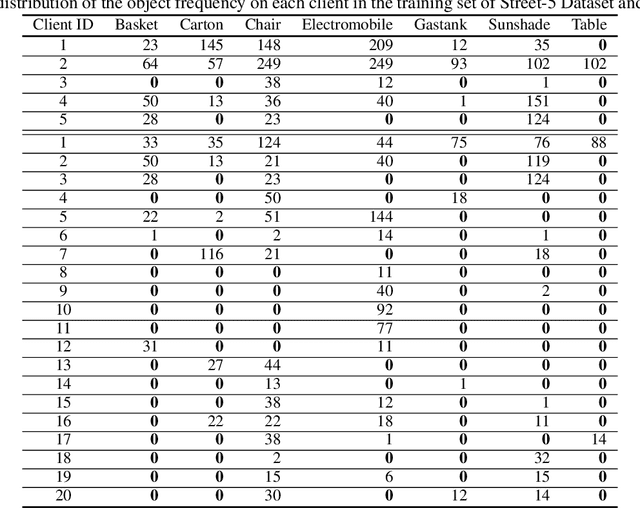
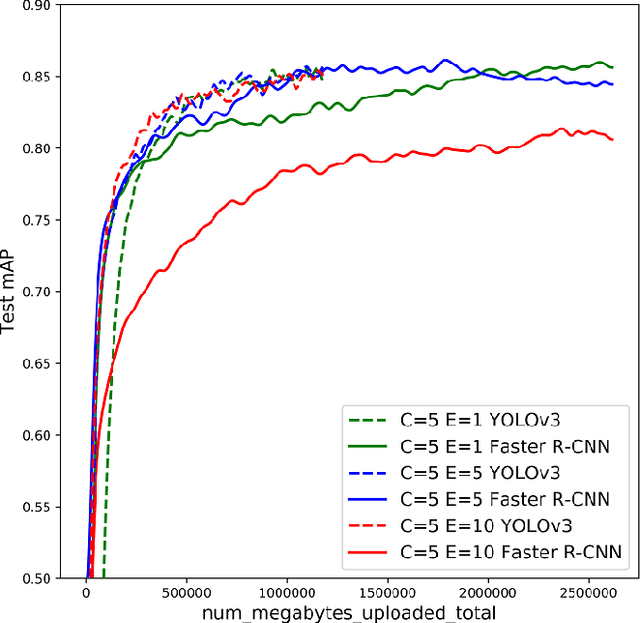
Federated learning is a new machine learning paradigm which allows data parties to build machine learning models collaboratively while keeping their data secure and private. While research efforts on federated learning have been growing tremendously in the past two years, most existing works still depend on pre-existing public datasets and artificial partitions to simulate data federations due to the lack of high-quality labeled data generated from real-world edge applications. Consequently, advances on benchmark and model evaluations for federated learning have been lagging behind. In this paper, we introduce a real-world image dataset. The dataset contains more than 900 images generated from 26 street cameras and 7 object categories annotated with detailed bounding box. The data distribution is non-IID and unbalanced, reflecting the characteristic real-world federated learning scenarios. Based on this dataset, we implemented two mainstream object detection algorithms (YOLO and Faster R-CNN) and provided an extensive benchmark on model performance, efficiency, and communication in a federated learning setting. Both the dataset and algorithms are made publicly available.