 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPC-GPT: Federated Task-Specific Compression of Large Language Models via Pruning and Chain-of-Thought Distillation
Feb 21, 2025



Compressing Large Language Models (LLMs) into task-specific Small Language Models (SLMs) encounters two significant challenges: safeguarding domain-specific knowledge privacy and managing limited resources. To tackle these challenges, we propose PPC-GPT, a innovative privacy-preserving federated framework specifically designed for compressing LLMs into task-specific SLMs via pruning and Chain-of-Thought (COT) distillation. PPC-GPT works on a server-client federated architecture, where the client sends differentially private (DP) perturbed task-specific data to the server's LLM. The LLM then generates synthetic data along with their corresponding rationales. This synthetic data is subsequently used for both LLM pruning and retraining processes. Additionally, we harness COT knowledge distillation, leveraging the synthetic data to further improve the retraining of structurally-pruned SLMs. Our experimental results demonstrate the effectiveness of PPC-GPT across various text generation tasks. By compressing LLMs into task-specific SLMs, PPC-GPT not only achieves competitive performance but also prioritizes data privacy protection.
FedCoLLM: A Parameter-Efficient Federated Co-tuning Framework for Large and Small Language Models
Nov 18, 2024


By adapting Large Language Models (LLMs) to domain-specific tasks or enriching them with domain-specific knowledge, we can fully harness the capabilities of LLMs. Nonetheless, a gap persists in achieving simultaneous mutual enhancement between the server's LLM and the downstream clients' Small Language Models (SLMs). To address this, we propose FedCoLLM, a novel and parameter-efficient federated framework designed for co-tuning LLMs and SLMs. This approach is aimed at adaptively transferring server-side LLMs knowledge to clients' SLMs while simultaneously enriching the LLMs with domain insights from the clients. To accomplish this, FedCoLLM utilizes lightweight adapters in conjunction with SLMs, facilitating knowledge exchange between server and clients in a manner that respects data privacy while also minimizing computational and communication overhead. Our evaluation of FedCoLLM, utilizing various public LLMs and SLMs across a range of NLP text generation tasks, reveals that the performance of clients' SLMs experiences notable improvements with the assistance of the LLMs. Simultaneously, the LLMs enhanced via FedCoLLM achieves comparable performance to that obtained through direct fine-tuning on clients' data.
FedMKT: Federated Mutual Knowledge Transfer for Large and Small Language Models
Jun 04, 2024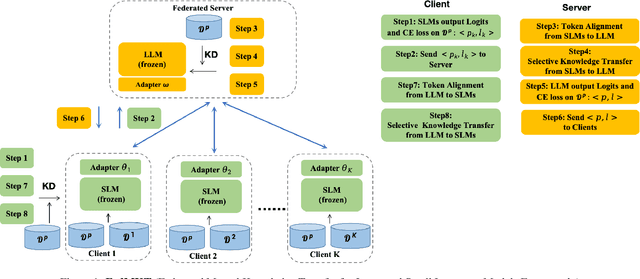
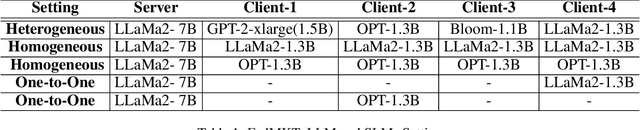

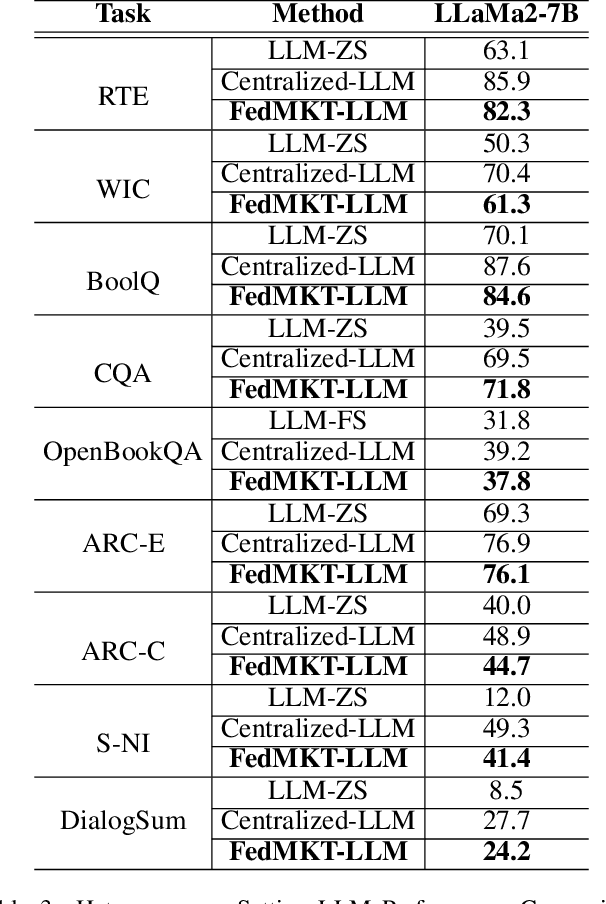
Recent research in federated large language models (LLMs) has primarily focused on enabling clients to fine-tune their locally deployed homogeneous LLMs collaboratively or on transferring knowledge from server-based LLMs to small language models (SLMs) at downstream clients. However, a significant gap remains in the simultaneous mutual enhancement of both the server's LLM and clients' SLMs. To bridge this gap, we propose FedMKT, a parameter-efficient federated mutual knowledge transfer framework for large and small language models. This framework is designed to adaptively transfer knowledge from the server's LLM to clients' SLMs while concurrently enriching the LLM with clients' unique domain insights. We facilitate token alignment using minimum edit distance (MinED) and then selective mutual knowledge transfer between client-side SLMs and a server-side LLM, aiming to collectively enhance their performance. Through extensive experiments across three distinct scenarios, heterogeneous, homogeneous, and one-to-one, we evaluate the effectiveness of FedMKT using various public LLMs and SLMs on a range of NLP text generation tasks. Empirical results demonstrate significant performance improvements in clients' SLMs with the aid of the LLM. Furthermore, the LLM optimized by FedMKT achieves a performance comparable to that achieved through direct fine-tuning based on clients' data, highlighting the effectiveness and adaptability of FedMKT.
FATE-LLM: A Industrial Grade Federated Learning Framework for Large Language Models
Oct 16, 2023



Large Language Models (LLMs), such as ChatGPT, LLaMA, GLM, and PaLM, have exhibited remarkable performances across various tasks in recent years. However, LLMs face two main challenges in real-world applications. One challenge is that training LLMs consumes vast computing resources, preventing LLMs from being adopted by small and medium-sized enterprises with limited computing resources. Another is that training LLM requires a large amount of high-quality data, which are often scattered among enterprises. To address these challenges, we propose FATE-LLM, an industrial-grade federated learning framework for large language models. FATE-LLM (1) facilitates federated learning for large language models (coined FedLLM); (2) promotes efficient training of FedLLM using parameter-efficient fine-tuning methods; (3) protects the intellectual property of LLMs; (4) preserves data privacy during training and inference through privacy-preserving mechanisms. We release the code of FATE-LLM at https://github.com/FederatedAI/FATE-LLM to facilitate the research of FedLLM and enable a broad range of industrial applications.
Privacy-preserving Federated Adversarial Domain Adaption over Feature Groups for Interpretability
Nov 22, 2021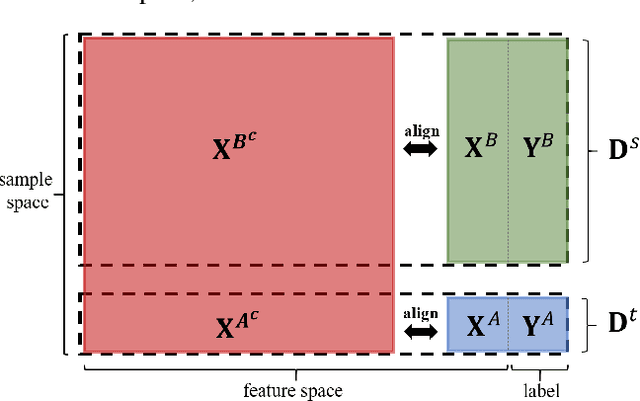
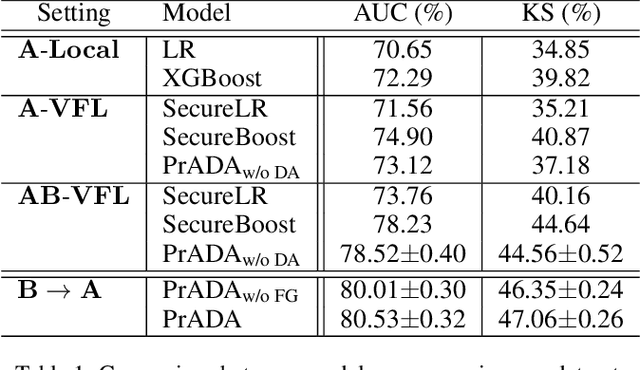
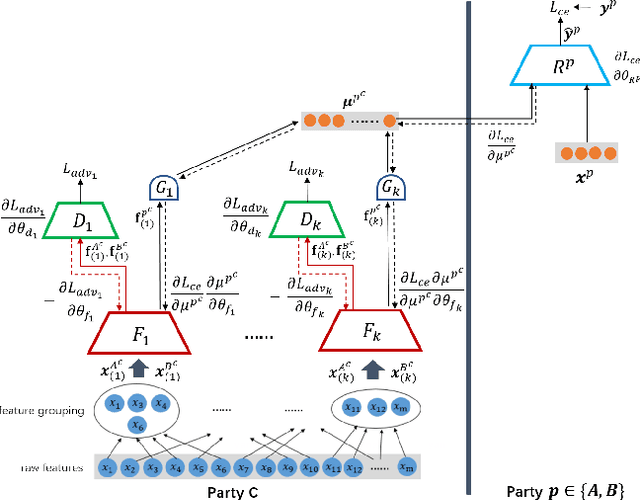
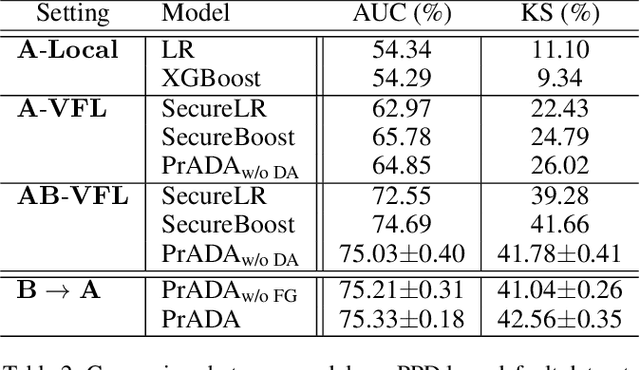
We present a novel privacy-preserving federated adversarial domain adaptation approach ($\textbf{PrADA}$) to address an under-studied but practical cross-silo federated domain adaptation problem, in which the party of the target domain is insufficient in both samples and features. We address the lack-of-feature issue by extending the feature space through vertical federated learning with a feature-rich party and tackle the sample-scarce issue by performing adversarial domain adaptation from the sample-rich source party to the target party. In this work, we focus on financial applications where interpretability is critical. However, existing adversarial domain adaptation methods typically apply a single feature extractor to learn feature representations that are low-interpretable with respect to the target task. To improve interpretability, we exploit domain expertise to split the feature space into multiple groups that each holds relevant features, and we learn a semantically meaningful high-order feature from each feature group. In addition, we apply a feature extractor (along with a domain discriminator) for each feature group to enable a fine-grained domain adaptation. We design a secure protocol that enables performing the PrADA in a secure and efficient manner. We evaluate our approach on two tabular datasets. Experiments demonstrate both the effectiveness and practicality of our approach.
SecureBoost+ : A High Performance Gradient Boosting Tree Framework for Large Scale Vertical Federated Learning
Oct 21, 2021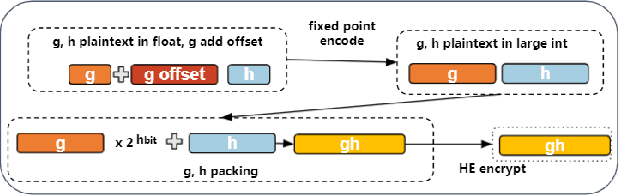
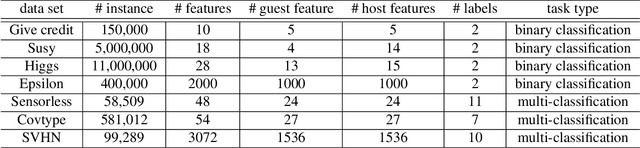
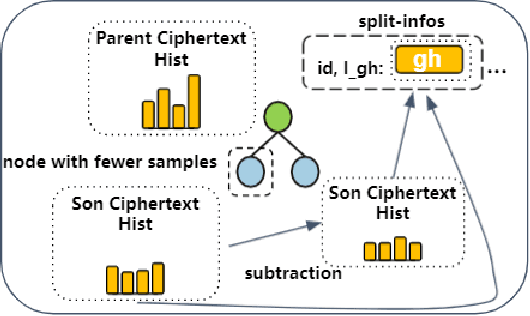
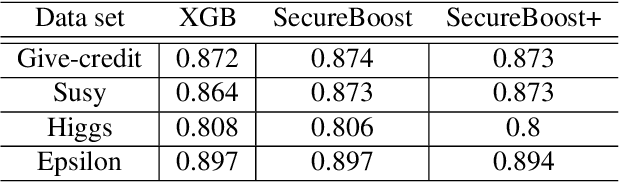
Gradient boosting decision tree (GBDT) is a widely used ensemble algorithm in the industry. Its vertical federated learning version, SecureBoost, is one of the most popular algorithms used in cross-silo privacy-preserving modeling. As the area of privacy computation thrives in recent years, demands for large-scale and high-performance federated learning have grown dramatically in real-world applications. In this paper, to fulfill these requirements, we propose SecureBoost+ that is both novel and improved from the prior work SecureBoost. SecureBoost+ integrates several ciphertext calculation optimizations and engineering optimizations. The experimental results demonstrate that Secureboost+ has significant performance improvements on large and high dimensional data sets compared to SecureBoost. It makes effective and efficient large-scale vertical federated learning possible.