 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen More Thinking Hurts: Overthinking in LLM Test-Time Compute Scaling
Apr 12, 2026Scaling test-time compute through extended chains of thought has become a dominant paradigm for improving large language model reasoning. However, existing research implicitly assumes that longer thinking always yields better results. This assumption remains largely unexamined. We systematically investigate how the marginal utility of additional reasoning tokens changes as compute budgets increase. We find that marginal returns diminish substantially at higher budgets and that models exhibit ``overthinking'', where extended reasoning is associated with abandoning previously correct answers. Furthermore, we show that optimal thinking length varies across problem difficulty, suggesting that uniform compute allocation is suboptimal. Our cost-aware evaluation framework reveals that stopping at moderate budgets can reduce computation significantly while maintaining comparable accuracy.
H2Tune: Federated Foundation Model Fine-Tuning with Hybrid Heterogeneity
Jul 30, 2025Different from existing federated fine-tuning (FFT) methods for foundation models, hybrid heterogeneous federated fine-tuning (HHFFT) is an under-explored scenario where clients exhibit double heterogeneity in model architectures and downstream tasks. This hybrid heterogeneity introduces two significant challenges: 1) heterogeneous matrix aggregation, where clients adopt different large-scale foundation models based on their task requirements and resource limitations, leading to dimensional mismatches during LoRA parameter aggregation; and 2) multi-task knowledge interference, where local shared parameters, trained with both task-shared and task-specific knowledge, cannot ensure only task-shared knowledge is transferred between clients. To address these challenges, we propose H2Tune, a federated foundation model fine-tuning with hybrid heterogeneity. Our framework H2Tune consists of three key components: (i) sparsified triple matrix decomposition to align hidden dimensions across clients through constructing rank-consistent middle matrices, with adaptive sparsification based on client resources; (ii) relation-guided matrix layer alignment to handle heterogeneous layer structures and representation capabilities; and (iii) alternating task-knowledge disentanglement mechanism to decouple shared and specific knowledge of local model parameters through alternating optimization. Theoretical analysis proves a convergence rate of O(1/\sqrt{T}). Extensive experiments show our method achieves up to 15.4% accuracy improvement compared to state-of-the-art baselines. Our code is available at https://anonymous.4open.science/r/H2Tune-1407.
INFERENCEDYNAMICS: Efficient Routing Across LLMs through Structured Capability and Knowledge Profiling
May 22, 2025


Large Language Model (LLM) routing is a pivotal technique for navigating a diverse landscape of LLMs, aiming to select the best-performing LLMs tailored to the domains of user queries, while managing computational resources. However, current routing approaches often face limitations in scalability when dealing with a large pool of specialized LLMs, or in their adaptability to extending model scope and evolving capability domains. To overcome those challenges, we propose InferenceDynamics, a flexible and scalable multi-dimensional routing framework by modeling the capability and knowledge of models. We operate it on our comprehensive dataset RouteMix, and demonstrate its effectiveness and generalizability in group-level routing using modern benchmarks including MMLU-Pro, GPQA, BigGenBench, and LiveBench, showcasing its ability to identify and leverage top-performing models for given tasks, leading to superior outcomes with efficient resource utilization. The broader adoption of Inference Dynamics can empower users to harness the full specialized potential of the LLM ecosystem, and our code will be made publicly available to encourage further research.
Towards Multi-Agent Reasoning Systems for Collaborative Expertise Delegation: An Exploratory Design Study
May 12, 2025Designing effective collaboration structure for multi-agent LLM systems to enhance collective reasoning is crucial yet remains under-explored. In this paper, we systematically investigate how collaborative reasoning performance is affected by three key design dimensions: (1) Expertise-Domain Alignment, (2) Collaboration Paradigm (structured workflow vs. diversity-driven integration), and (3) System Scale. Our findings reveal that expertise alignment benefits are highly domain-contingent, proving most effective for contextual reasoning tasks. Furthermore, collaboration focused on integrating diverse knowledge consistently outperforms rigid task decomposition. Finally, we empirically explore the impact of scaling the multi-agent system with expertise specialization and study the computational trade off, highlighting the need for more efficient communication protocol design. This work provides concrete guidelines for configuring specialized multi-agent system and identifies critical architectural trade-offs and bottlenecks for scalable multi-agent reasoning. The code will be made available upon acceptance.
Text-to-TrajVis: Enabling Trajectory Data Visualizations from Natural Language Questions
Apr 23, 2025This paper introduces the Text-to-TrajVis task, which aims to transform natural language questions into trajectory data visualizations, facilitating the development of natural language interfaces for trajectory visualization systems. As this is a novel task, there is currently no relevant dataset available in the community. To address this gap, we first devised a new visualization language called Trajectory Visualization Language (TVL) to facilitate querying trajectory data and generating visualizations. Building on this foundation, we further proposed a dataset construction method that integrates Large Language Models (LLMs) with human efforts to create high-quality data. Specifically, we first generate TVLs using a comprehensive and systematic process, and then label each TVL with corresponding natural language questions using LLMs. This process results in the creation of the first large-scale Text-to-TrajVis dataset, named TrajVL, which contains 18,140 (question, TVL) pairs. Based on this dataset, we systematically evaluated the performance of multiple LLMs (GPT, Qwen, Llama, etc.) on this task. The experimental results demonstrate that this task is both feasible and highly challenging and merits further exploration within the research community.
Radar Code Design for the Joint Optimization of Detection Performance and Measurement Accuracy in Track Maintenance
Apr 22, 2025



This paper deals with the design of slow-time coded waveforms which jointly optimize the detection probability and the measurements accuracy for track maintenance in the presence of colored Gaussian interference. The output signal-to-interference-plus-noise ratio (SINR) and Cram\'er Rao bounds (CRBs) on time delay and Doppler shift are used as figures of merit to accomplish reliable detection as well as accurate measurements. The transmitted code is subject to radar power budget requirements and a similarity constraint. To tackle the resulting non-convex multi-objective optimization problem, a polynomial-time algorithm that integrates scalarization and tensor-based relaxation methods is developed. The corresponding relaxed multi-linear problems are solved by means of the maximum block improvement (MBI) framework, where the optimal solution at each iteration is obtained in closed form. Numeral results demonstrate the trade-off between the detection and the estimation performance, along with the acceptable Doppler robustness achieved by the proposed algorithm.
PPC-GPT: Federated Task-Specific Compression of Large Language Models via Pruning and Chain-of-Thought Distillation
Feb 21, 2025



Compressing Large Language Models (LLMs) into task-specific Small Language Models (SLMs) encounters two significant challenges: safeguarding domain-specific knowledge privacy and managing limited resources. To tackle these challenges, we propose PPC-GPT, a innovative privacy-preserving federated framework specifically designed for compressing LLMs into task-specific SLMs via pruning and Chain-of-Thought (COT) distillation. PPC-GPT works on a server-client federated architecture, where the client sends differentially private (DP) perturbed task-specific data to the server's LLM. The LLM then generates synthetic data along with their corresponding rationales. This synthetic data is subsequently used for both LLM pruning and retraining processes. Additionally, we harness COT knowledge distillation, leveraging the synthetic data to further improve the retraining of structurally-pruned SLMs. Our experimental results demonstrate the effectiveness of PPC-GPT across various text generation tasks. By compressing LLMs into task-specific SLMs, PPC-GPT not only achieves competitive performance but also prioritizes data privacy protection.
FedCoLLM: A Parameter-Efficient Federated Co-tuning Framework for Large and Small Language Models
Nov 18, 2024


By adapting Large Language Models (LLMs) to domain-specific tasks or enriching them with domain-specific knowledge, we can fully harness the capabilities of LLMs. Nonetheless, a gap persists in achieving simultaneous mutual enhancement between the server's LLM and the downstream clients' Small Language Models (SLMs). To address this, we propose FedCoLLM, a novel and parameter-efficient federated framework designed for co-tuning LLMs and SLMs. This approach is aimed at adaptively transferring server-side LLMs knowledge to clients' SLMs while simultaneously enriching the LLMs with domain insights from the clients. To accomplish this, FedCoLLM utilizes lightweight adapters in conjunction with SLMs, facilitating knowledge exchange between server and clients in a manner that respects data privacy while also minimizing computational and communication overhead. Our evaluation of FedCoLLM, utilizing various public LLMs and SLMs across a range of NLP text generation tasks, reveals that the performance of clients' SLMs experiences notable improvements with the assistance of the LLMs. Simultaneously, the LLMs enhanced via FedCoLLM achieves comparable performance to that obtained through direct fine-tuning on clients' data.
PDSS: A Privacy-Preserving Framework for Step-by-Step Distillation of Large Language Models
Jun 18, 2024



In the context of real-world applications, leveraging large language models (LLMs) for domain-specific tasks often faces two major challenges: domain-specific knowledge privacy and constrained resources. To address these issues, we propose PDSS, a privacy-preserving framework for step-by-step distillation of LLMs. PDSS works on a server-client architecture, wherein client transmits perturbed prompts to the server's LLM for rationale generation. The generated rationales are then decoded by the client and used to enrich the training of task-specific small language model(SLM) within a multi-task learning paradigm. PDSS introduces two privacy protection strategies: the Exponential Mechanism Strategy and the Encoder-Decoder Strategy, balancing prompt privacy and rationale usability. Experiments demonstrate the effectiveness of PDSS in various text generation tasks, enabling the training of task-specific SLM with enhanced performance while prioritizing data privacy protection.
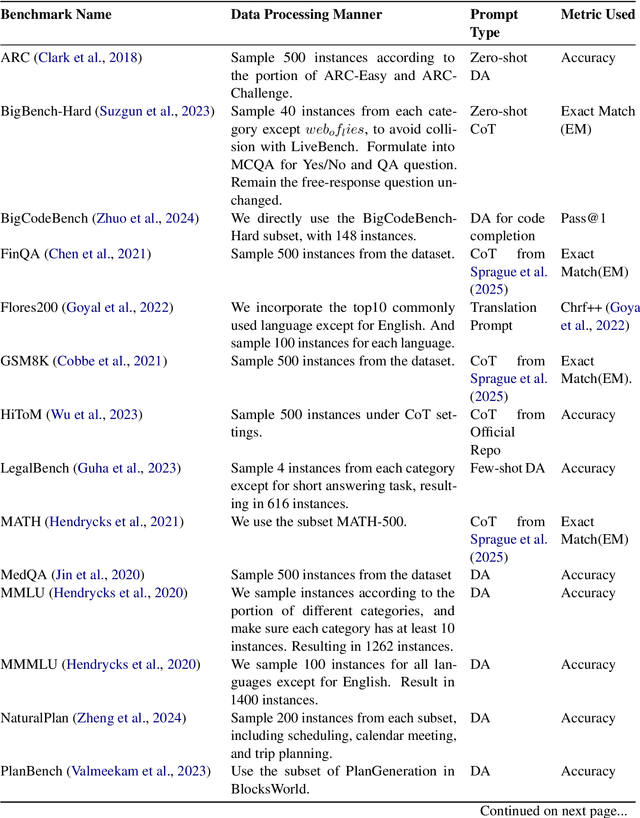
FedMKT: Federated Mutual Knowledge Transfer for Large and Small Language Models
Jun 04, 2024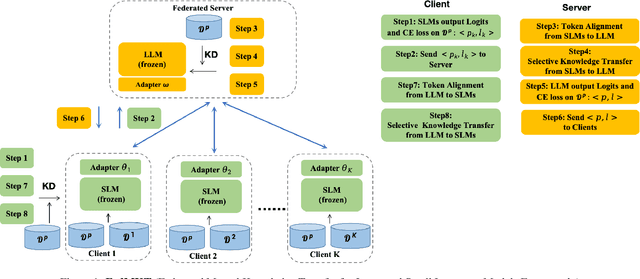
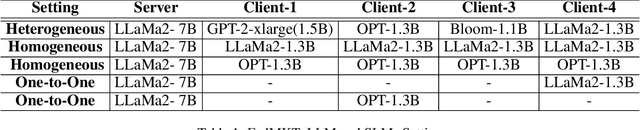

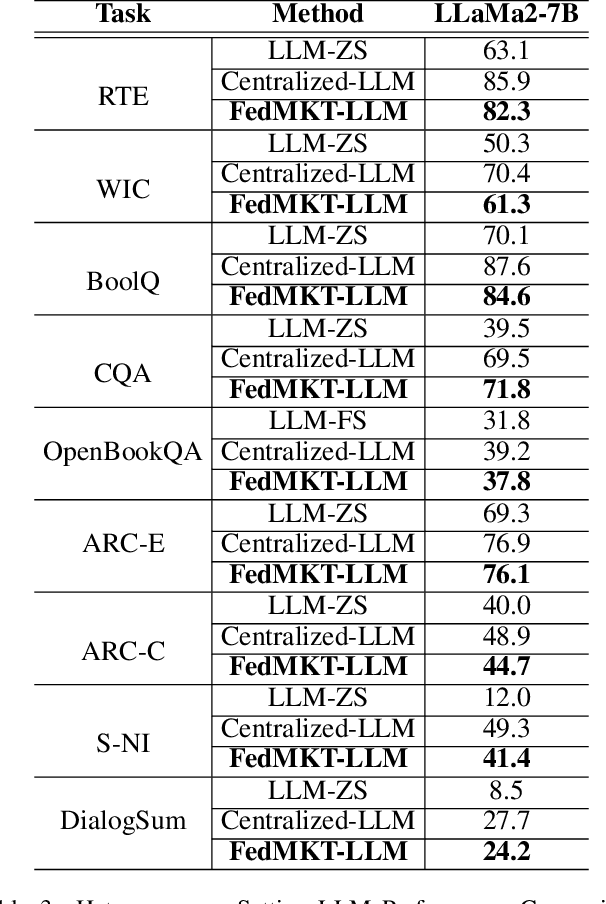
Recent research in federated large language models (LLMs) has primarily focused on enabling clients to fine-tune their locally deployed homogeneous LLMs collaboratively or on transferring knowledge from server-based LLMs to small language models (SLMs) at downstream clients. However, a significant gap remains in the simultaneous mutual enhancement of both the server's LLM and clients' SLMs. To bridge this gap, we propose FedMKT, a parameter-efficient federated mutual knowledge transfer framework for large and small language models. This framework is designed to adaptively transfer knowledge from the server's LLM to clients' SLMs while concurrently enriching the LLM with clients' unique domain insights. We facilitate token alignment using minimum edit distance (MinED) and then selective mutual knowledge transfer between client-side SLMs and a server-side LLM, aiming to collectively enhance their performance. Through extensive experiments across three distinct scenarios, heterogeneous, homogeneous, and one-to-one, we evaluate the effectiveness of FedMKT using various public LLMs and SLMs on a range of NLP text generation tasks. Empirical results demonstrate significant performance improvements in clients' SLMs with the aid of the LLM. Furthermore, the LLM optimized by FedMKT achieves a performance comparable to that achieved through direct fine-tuning based on clients' data, highlighting the effectiveness and adaptability of FedMKT.