 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDSS: A Privacy-Preserving Framework for Step-by-Step Distillation of Large Language Models
Jun 18, 2024



In the context of real-world applications, leveraging large language models (LLMs) for domain-specific tasks often faces two major challenges: domain-specific knowledge privacy and constrained resources. To address these issues, we propose PDSS, a privacy-preserving framework for step-by-step distillation of LLMs. PDSS works on a server-client architecture, wherein client transmits perturbed prompts to the server's LLM for rationale generation. The generated rationales are then decoded by the client and used to enrich the training of task-specific small language model(SLM) within a multi-task learning paradigm. PDSS introduces two privacy protection strategies: the Exponential Mechanism Strategy and the Encoder-Decoder Strategy, balancing prompt privacy and rationale usability. Experiments demonstrate the effectiveness of PDSS in various text generation tasks, enabling the training of task-specific SLM with enhanced performance while prioritizing data privacy protection.
FATE-LLM: A Industrial Grade Federated Learning Framework for Large Language Models
Oct 16, 2023



Large Language Models (LLMs), such as ChatGPT, LLaMA, GLM, and PaLM, have exhibited remarkable performances across various tasks in recent years. However, LLMs face two main challenges in real-world applications. One challenge is that training LLMs consumes vast computing resources, preventing LLMs from being adopted by small and medium-sized enterprises with limited computing resources. Another is that training LLM requires a large amount of high-quality data, which are often scattered among enterprises. To address these challenges, we propose FATE-LLM, an industrial-grade federated learning framework for large language models. FATE-LLM (1) facilitates federated learning for large language models (coined FedLLM); (2) promotes efficient training of FedLLM using parameter-efficient fine-tuning methods; (3) protects the intellectual property of LLMs; (4) preserves data privacy during training and inference through privacy-preserving mechanisms. We release the code of FATE-LLM at https://github.com/FederatedAI/FATE-LLM to facilitate the research of FedLLM and enable a broad range of industrial applications.
Rethinking Benchmarks for Cross-modal Image-text Retrieval
Apr 21, 2023



Image-text retrieval, as a fundamental and important branch of information retrieval, has attracted extensive research attentions. The main challenge of this task is cross-modal semantic understanding and matching. Some recent works focus more on fine-grained cross-modal semantic matching. With the prevalence of large scale multimodal pretraining models, several state-of-the-art models (e.g. X-VLM) have achieved near-perfect performance on widely-used image-text retrieval benchmarks, i.e. MSCOCO-Test-5K and Flickr30K-Test-1K. In this paper, we review the two common benchmarks and observe that they are insufficient to assess the true capability of models on fine-grained cross-modal semantic matching. The reason is that a large amount of images and texts in the benchmarks are coarse-grained. Based on the observation, we renovate the coarse-grained images and texts in the old benchmarks and establish the improved benchmarks called MSCOCO-FG and Flickr30K-FG. Specifically, on the image side, we enlarge the original image pool by adopting more similar images. On the text side, we propose a novel semi-automatic renovation approach to refine coarse-grained sentences into finer-grained ones with little human effort. Furthermore, we evaluate representative image-text retrieval models on our new benchmarks to demonstrate the effectiveness of our method. We also analyze the capability of models on fine-grained semantic comprehension through extensive experiments. The results show that even the state-of-the-art models have much room for improvement in fine-grained semantic understanding, especially in distinguishing attributes of close objects in images. Our code and improved benchmark datasets are publicly available at: https://github.com/cwj1412/MSCOCO-Flikcr30K_FG, which we hope will inspire further in-depth research on cross-modal retrieval.
CapEnrich: Enriching Caption Semantics for Web Images via Cross-modal Pre-trained Knowledge
Nov 17, 2022



Automatically generating textual descriptions for massive unlabeled images on the web can greatly benefit realistic web applications, e.g. multimodal retrieval and recommendation. However, existing models suffer from the problem of generating ``over-generic'' descriptions, such as their tendency to generate repetitive sentences with common concepts for different images. These generic descriptions fail to provide sufficient textual semantics for ever-changing web images. Inspired by the recent success of Vision-Language Pre-training (VLP) models that learn diverse image-text concept alignment during pretraining, we explore leveraging their cross-modal pre-trained knowledge to automatically enrich the textual semantics of image descriptions. With no need for additional human annotations, we propose a plug-and-play framework, i.e CapEnrich, to complement the generic image descriptions with more semantic details. Specifically, we first propose an automatic data-building strategy to get desired training sentences, based on which we then adopt prompting strategies, i.e. learnable and template prompts, to incentivize VLP models to generate more textual details. For learnable templates, we fix the whole VLP model and only tune the prompt vectors, which leads to two advantages: 1) the pre-training knowledge of VLP models can be reserved as much as possible to describe diverse visual concepts; 2) only lightweight trainable parameters are required, so it is friendly to low data resources. Extensive experiments show that our method significantly improves the descriptiveness and diversity of generated sentences for web images. Our code will be released.
SecureBoost+ : A High Performance Gradient Boosting Tree Framework for Large Scale Vertical Federated Learning
Oct 21, 2021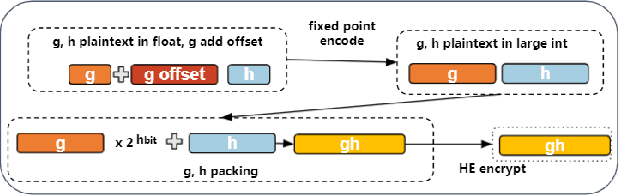
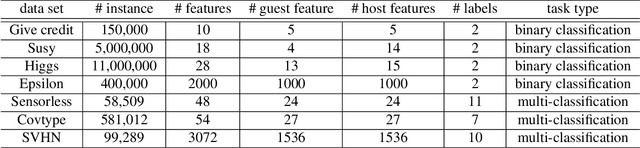
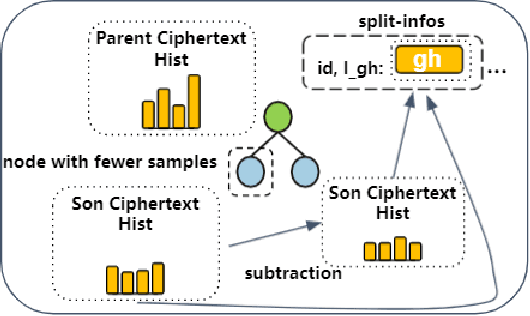
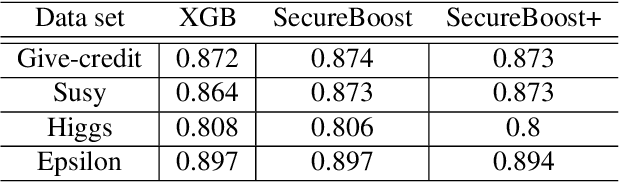
Gradient boosting decision tree (GBDT) is a widely used ensemble algorithm in the industry. Its vertical federated learning version, SecureBoost, is one of the most popular algorithms used in cross-silo privacy-preserving modeling. As the area of privacy computation thrives in recent years, demands for large-scale and high-performance federated learning have grown dramatically in real-world applications. In this paper, to fulfill these requirements, we propose SecureBoost+ that is both novel and improved from the prior work SecureBoost. SecureBoost+ integrates several ciphertext calculation optimizations and engineering optimizations. The experimental results demonstrate that Secureboost+ has significant performance improvements on large and high dimensional data sets compared to SecureBoost. It makes effective and efficient large-scale vertical federated learning possible.