 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Hanabi: Evaluating Multi-Agent Gameplays with Theory-of-Mind and Rationale Inference in Imperfect Information Collaboration Game
Oct 06, 2025



Effective multi-agent collaboration requires agents to infer the rationale behind others' actions, a capability rooted in Theory-of-Mind (ToM). While recent Large Language Models (LLMs) excel at logical inference, their ability to infer rationale in dynamic, collaborative settings remains under-explored. This study introduces LLM-Hanabi, a novel benchmark that uses the cooperative game Hanabi to evaluate the rationale inference and ToM of LLMs. Our framework features an automated evaluation system that measures both game performance and ToM proficiency. Across a range of models, we find a significant positive correlation between ToM and in-game success. Notably, first-order ToM (interpreting others' intent) correlates more strongly with performance than second-order ToM (predicting others' interpretations). These findings highlight that for effective AI collaboration, the ability to accurately interpret a partner's rationale is more critical than higher-order reasoning. We conclude that prioritizing first-order ToM is a promising direction for enhancing the collaborative capabilities of future models.
Structuring the Unstructured: A Systematic Review of Text-to-Structure Generation for Agentic AI with a Universal Evaluation Framework
Aug 17, 2025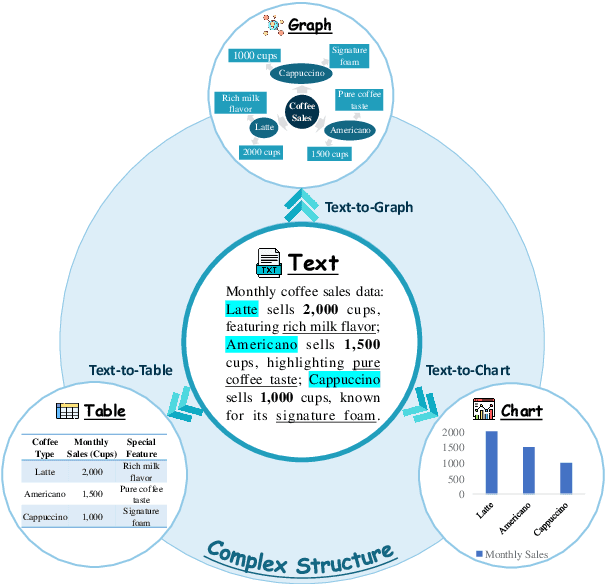
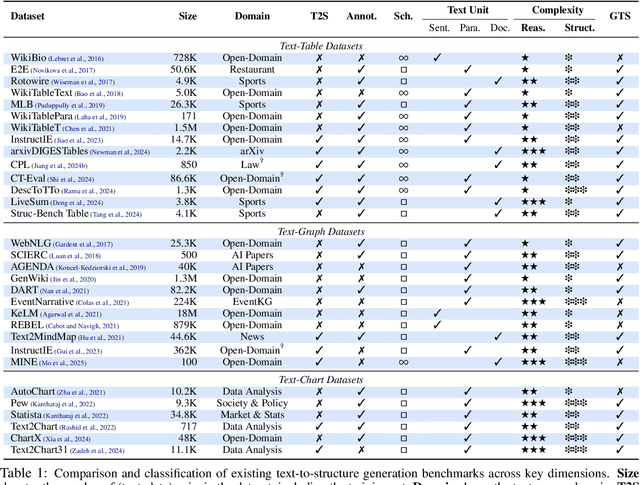

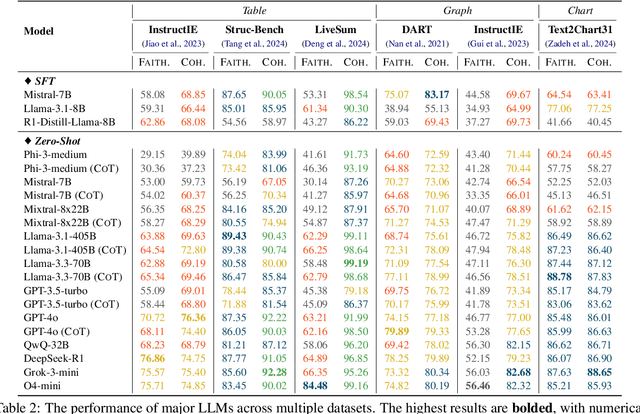
The evolution of AI systems toward agentic operation and context-aware retrieval necessitates transforming unstructured text into structured formats like tables, knowledge graphs, and charts. While such conversions enable critical applications from summarization to data mining, current research lacks a comprehensive synthesis of methodologies, datasets, and metrics. This systematic review examines text-to-structure techniques and the encountered challenges, evaluates current datasets and assessment criteria, and outlines potential directions for future research. We also introduce a universal evaluation framework for structured outputs, establishing text-to-structure as foundational infrastructure for next-generation AI systems.
SessionIntentBench: A Multi-task Inter-session Intention-shift Modeling Benchmark for E-commerce Customer Behavior Understanding
Jul 27, 2025Session history is a common way of recording user interacting behaviors throughout a browsing activity with multiple products. For example, if an user clicks a product webpage and then leaves, it might because there are certain features that don't satisfy the user, which serve as an important indicator of on-the-spot user preferences. However, all prior works fail to capture and model customer intention effectively because insufficient information exploitation and only apparent information like descriptions and titles are used. There is also a lack of data and corresponding benchmark for explicitly modeling intention in E-commerce product purchase sessions. To address these issues, we introduce the concept of an intention tree and propose a dataset curation pipeline. Together, we construct a sibling multimodal benchmark, SessionIntentBench, that evaluates L(V)LMs' capability on understanding inter-session intention shift with four subtasks. With 1,952,177 intention entries, 1,132,145 session intention trajectories, and 13,003,664 available tasks mined using 10,905 sessions, we provide a scalable way to exploit the existing session data for customer intention understanding. We conduct human annotations to collect ground-truth label for a subset of collected data to form an evaluation gold set. Extensive experiments on the annotated data further confirm that current L(V)LMs fail to capture and utilize the intention across the complex session setting. Further analysis show injecting intention enhances LLMs' performances.
From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents
Jun 23, 2025Information retrieval is a cornerstone of modern knowledge acquisition, enabling billions of queries each day across diverse domains. However, traditional keyword-based search engines are increasingly inadequate for handling complex, multi-step information needs. Our position is that Large Language Models (LLMs), endowed with reasoning and agentic capabilities, are ushering in a new paradigm termed Agentic Deep Research. These systems transcend conventional information search techniques by tightly integrating autonomous reasoning, iterative retrieval, and information synthesis into a dynamic feedback loop. We trace the evolution from static web search to interactive, agent-based systems that plan, explore, and learn. We also introduce a test-time scaling law to formalize the impact of computational depth on reasoning and search. Supported by benchmark results and the rise of open-source implementations, we demonstrate that Agentic Deep Research not only significantly outperforms existing approaches, but is also poised to become the dominant paradigm for future information seeking. All the related resources, including industry products, research papers, benchmark datasets, and open-source implementations, are collected for the community in https://github.com/DavidZWZ/Awesome-Deep-Research.
INFERENCEDYNAMICS: Efficient Routing Across LLMs through Structured Capability and Knowledge Profiling
May 22, 2025


Large Language Model (LLM) routing is a pivotal technique for navigating a diverse landscape of LLMs, aiming to select the best-performing LLMs tailored to the domains of user queries, while managing computational resources. However, current routing approaches often face limitations in scalability when dealing with a large pool of specialized LLMs, or in their adaptability to extending model scope and evolving capability domains. To overcome those challenges, we propose InferenceDynamics, a flexible and scalable multi-dimensional routing framework by modeling the capability and knowledge of models. We operate it on our comprehensive dataset RouteMix, and demonstrate its effectiveness and generalizability in group-level routing using modern benchmarks including MMLU-Pro, GPQA, BigGenBench, and LiveBench, showcasing its ability to identify and leverage top-performing models for given tasks, leading to superior outcomes with efficient resource utilization. The broader adoption of Inference Dynamics can empower users to harness the full specialized potential of the LLM ecosystem, and our code will be made publicly available to encourage further research.
ECon: On the Detection and Resolution of Evidence Conflicts
Oct 05, 2024



The rise of large language models (LLMs) has significantly influenced the quality of information in decision-making systems, leading to the prevalence of AI-generated content and challenges in detecting misinformation and managing conflicting information, or "inter-evidence conflicts." This study introduces a method for generating diverse, validated evidence conflicts to simulate real-world misinformation scenarios. We evaluate conflict detection methods, including Natural Language Inference (NLI) models, factual consistency (FC) models, and LLMs, on these conflicts (RQ1) and analyze LLMs' conflict resolution behaviors (RQ2). Our key findings include: (1) NLI and LLM models exhibit high precision in detecting answer conflicts, though weaker models suffer from low recall; (2) FC models struggle with lexically similar answer conflicts, while NLI and LLM models handle these better; and (3) stronger models like GPT-4 show robust performance, especially with nuanced conflicts. For conflict resolution, LLMs often favor one piece of conflicting evidence without justification and rely on internal knowledge if they have prior beliefs.
Persona Knowledge-Aligned Prompt Tuning Method for Online Debate
Oct 05, 2024



Debate is the process of exchanging viewpoints or convincing others on a particular issue. Recent research has provided empirical evidence that the persuasiveness of an argument is determined not only by language usage but also by communicator characteristics. Researchers have paid much attention to aspects of languages, such as linguistic features and discourse structures, but combining argument persuasiveness and impact with the social personae of the audience has not been explored due to the difficulty and complexity. We have observed the impressive simulation and personification capability of ChatGPT, indicating a giant pre-trained language model may function as an individual to provide personae and exert unique influences based on diverse background knowledge. Therefore, we propose a persona knowledge-aligned framework for argument quality assessment tasks from the audience side. This is the first work that leverages the emergence of ChatGPT and injects such audience personae knowledge into smaller language models via prompt tuning. The performance of our pipeline demonstrates significant and consistent improvement compared to competitive architectures.
Evaluating and Enhancing LLMs Agent based on Theory of Mind in Guandan: A Multi-Player Cooperative Game under Imperfect Information
Aug 05, 2024



Large language models (LLMs) have shown success in handling simple games with imperfect information and enabling multi-agent coordination, but their ability to facilitate practical collaboration against other agents in complex, imperfect information environments, especially in a non-English environment, still needs to be explored. This study investigates the applicability of knowledge acquired by open-source and API-based LLMs to sophisticated text-based games requiring agent collaboration under imperfect information, comparing their performance to established baselines using other types of agents. We propose a Theory of Mind (ToM) planning technique that allows LLM agents to adapt their strategy against various adversaries using only game rules, current state, and historical context as input. An external tool was incorporated to mitigate the challenge of dynamic and extensive action spaces in this card game. Our results show that although a performance gap exists between current LLMs and state-of-the-art reinforcement learning (RL) models, LLMs demonstrate ToM capabilities in this game setting. It consistently improves their performance against opposing agents, suggesting their ability to understand the actions of allies and adversaries and establish collaboration with allies. To encourage further research and understanding, we have made our codebase openly accessible.
Backdoor Removal for Generative Large Language Models
May 13, 2024With rapid advances, generative large language models (LLMs) dominate various Natural Language Processing (NLP) tasks from understanding to reasoning. Yet, language models' inherent vulnerabilities may be exacerbated due to increased accessibility and unrestricted model training on massive textual data from the Internet. A malicious adversary may publish poisoned data online and conduct backdoor attacks on the victim LLMs pre-trained on the poisoned data. Backdoored LLMs behave innocuously for normal queries and generate harmful responses when the backdoor trigger is activated. Despite significant efforts paid to LLMs' safety issues, LLMs are still struggling against backdoor attacks. As Anthropic recently revealed, existing safety training strategies, including supervised fine-tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), fail to revoke the backdoors once the LLM is backdoored during the pre-training stage. In this paper, we present Simulate and Eliminate (SANDE) to erase the undesired backdoored mappings for generative LLMs. We initially propose Overwrite Supervised Fine-tuning (OSFT) for effective backdoor removal when the trigger is known. Then, to handle the scenarios where the trigger patterns are unknown, we integrate OSFT into our two-stage framework, SANDE. Unlike previous works that center on the identification of backdoors, our safety-enhanced LLMs are able to behave normally even when the exact triggers are activated. We conduct comprehensive experiments to show that our proposed SANDE is effective against backdoor attacks while bringing minimal harm to LLMs' powerful capability without any additional access to unbackdoored clean models. We will release the reproducible code.
Text-Tuple-Table: Towards Information Integration in Text-to-Table Generation via Global Tuple Extraction
Apr 22, 2024



The task of condensing large chunks of textual information into concise and structured tables has gained attention recently due to the emergence of Large Language Models (LLMs) and their potential benefit for downstream tasks, such as text summarization and text mining. Previous approaches often generate tables that directly replicate information from the text, limiting their applicability in broader contexts, as text-to-table generation in real-life scenarios necessitates information extraction, reasoning, and integration. However, there is a lack of both datasets and methodologies towards this task. In this paper, we introduce LiveSum, a new benchmark dataset created for generating summary tables of competitions based on real-time commentary texts. We evaluate the performances of state-of-the-art LLMs on this task in both fine-tuning and zero-shot settings, and additionally propose a novel pipeline called $T^3$(Text-Tuple-Table) to improve their performances. Extensive experimental results demonstrate that LLMs still struggle with this task even after fine-tuning, while our approach can offer substantial performance gains without explicit training. Further analyses demonstrate that our method exhibits strong generalization abilities, surpassing previous approaches on several other text-to-table datasets. Our code and data can be found at https://github.com/HKUST-KnowComp/LiveSum-TTT.