 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSDWC: Federated Synergistic Dual-Representation Weak Causal Learning for OOD
Nov 12, 2025
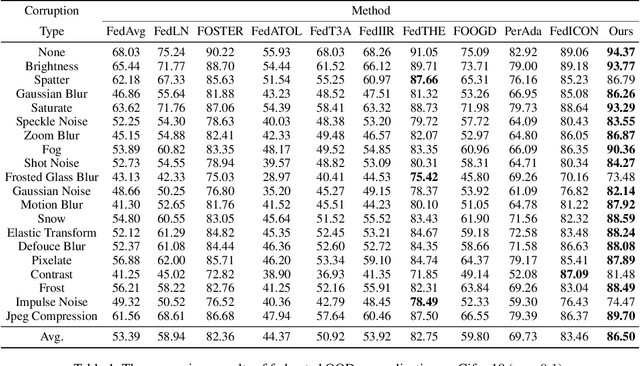
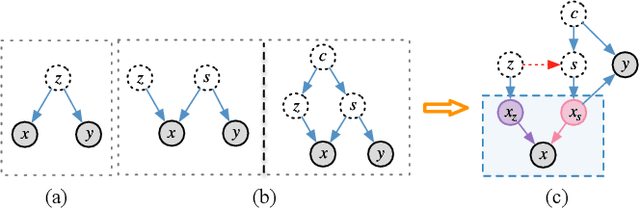
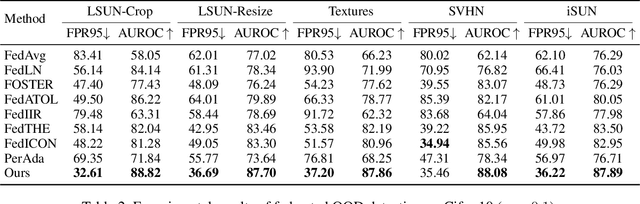
Amid growing demands for data privacy and advances in computational infrastructure, federated learning (FL) has emerged as a prominent distributed learning paradigm. Nevertheless, differences in data distribution (such as covariate and semantic shifts) severely affect its reliability in real-world deployments. To address this issue, we propose FedSDWC, a causal inference method that integrates both invariant and variant features. FedSDWC infers causal semantic representations by modeling the weak causal influence between invariant and variant features, effectively overcoming the limitations of existing invariant learning methods in accurately capturing invariant features and directly constructing causal representations. This approach significantly enhances FL's ability to generalize and detect OOD data. Theoretically, we derive FedSDWC's generalization error bound under specific conditions and, for the first time, establish its relationship with client prior distributions. Moreover, extensive experiments conducted on multiple benchmark datasets validate the superior performance of FedSDWC in handling covariate and semantic shifts. For example, FedSDWC outperforms FedICON, the next best baseline, by an average of 3.04% on CIFAR-10 and 8.11% on CIFAR-100.
Reconstructing Close Human Interactions from Multiple Views
Jan 29, 2024



This paper addresses the challenging task of reconstructing the poses of multiple individuals engaged in close interactions, captured by multiple calibrated cameras. The difficulty arises from the noisy or false 2D keypoint detections due to inter-person occlusion, the heavy ambiguity in associating keypoints to individuals due to the close interactions, and the scarcity of training data as collecting and annotating motion data in crowded scenes is resource-intensive. We introduce a novel system to address these challenges. Our system integrates a learning-based pose estimation component and its corresponding training and inference strategies. The pose estimation component takes multi-view 2D keypoint heatmaps as input and reconstructs the pose of each individual using a 3D conditional volumetric network. As the network doesn't need images as input, we can leverage known camera parameters from test scenes and a large quantity of existing motion capture data to synthesize massive training data that mimics the real data distribution in test scenes. Extensive experiments demonstrate that our approach significantly surpasses previous approaches in terms of pose accuracy and is generalizable across various camera setups and population sizes. The code is available on our project page: https://github.com/zju3dv/CloseMoCap.
* SIGGRAPH Asia 2023
A Communication Theory Perspective on Prompting Engineering Methods for Large Language Models
Oct 24, 2023



The springing up of Large Language Models (LLMs) has shifted the community from single-task-orientated natural language processing (NLP) research to a holistic end-to-end multi-task learning paradigm. Along this line of research endeavors in the area, LLM-based prompting methods have attracted much attention, partially due to the technological advantages brought by prompt engineering (PE) as well as the underlying NLP principles disclosed by various prompting methods. Traditional supervised learning usually requires training a model based on labeled data and then making predictions. In contrast, PE methods directly use the powerful capabilities of existing LLMs (i.e., GPT-3 and GPT-4) via composing appropriate prompts, especially under few-shot or zero-shot scenarios. Facing the abundance of studies related to the prompting and the ever-evolving nature of this field, this article aims to (i) illustrate a novel perspective to review existing PE methods, within the well-established communication theory framework; (ii) facilitate a better/deeper understanding of developing trends of existing PE methods used in four typical tasks; (iii) shed light on promising research directions for future PE methods.