 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Large Multimodal Models for Ophthalmic Visual Question Answering with OphthalWeChat
May 26, 2025Purpose: To develop a bilingual multimodal visual question answering (VQA) benchmark for evaluating VLMs in ophthalmology. Methods: Ophthalmic image posts and associated captions published between January 1, 2016, and December 31, 2024, were collected from WeChat Official Accounts. Based on these captions, bilingual question-answer (QA) pairs in Chinese and English were generated using GPT-4o-mini. QA pairs were categorized into six subsets by question type and language: binary (Binary_CN, Binary_EN), single-choice (Single-choice_CN, Single-choice_EN), and open-ended (Open-ended_CN, Open-ended_EN). The benchmark was used to evaluate the performance of three VLMs: GPT-4o, Gemini 2.0 Flash, and Qwen2.5-VL-72B-Instruct. Results: The final OphthalWeChat dataset included 3,469 images and 30,120 QA pairs across 9 ophthalmic subspecialties, 548 conditions, 29 imaging modalities, and 68 modality combinations. Gemini 2.0 Flash achieved the highest overall accuracy (0.548), outperforming GPT-4o (0.522, P < 0.001) and Qwen2.5-VL-72B-Instruct (0.514, P < 0.001). It also led in both Chinese (0.546) and English subsets (0.550). Subset-specific performance showed Gemini 2.0 Flash excelled in Binary_CN (0.687), Single-choice_CN (0.666), and Single-choice_EN (0.646), while GPT-4o ranked highest in Binary_EN (0.717), Open-ended_CN (BLEU-1: 0.301; BERTScore: 0.382), and Open-ended_EN (BLEU-1: 0.183; BERTScore: 0.240). Conclusions: This study presents the first bilingual VQA benchmark for ophthalmology, distinguished by its real-world context and inclusion of multiple examinations per patient. The dataset reflects authentic clinical decision-making scenarios and enables quantitative evaluation of VLMs, supporting the development of accurate, specialized, and trustworthy AI systems for eye care.
Towards Harnessing the Collaborative Power of Large and Small Models for Domain Tasks
Apr 24, 2025Large language models (LLMs) have demonstrated remarkable capabilities, but they require vast amounts of data and computational resources. In contrast, smaller models (SMs), while less powerful, can be more efficient and tailored to specific domains. In this position paper, we argue that taking a collaborative approach, where large and small models work synergistically, can accelerate the adaptation of LLMs to private domains and unlock new potential in AI. We explore various strategies for model collaboration and identify potential challenges and opportunities. Building upon this, we advocate for industry-driven research that prioritizes multi-objective benchmarks on real-world private datasets and applications.
Doubly-Bounded Queue for Constrained Online Learning: Keeping Pace with Dynamics of Both Loss and Constraint
Dec 14, 2024



We consider online convex optimization with time-varying constraints and conduct performance analysis using two stringent metrics: dynamic regret with respect to the online solution benchmark, and hard constraint violation that does not allow any compensated violation over time. We propose an efficient algorithm called Constrained Online Learning with Doubly-bounded Queue (COLDQ), which introduces a novel virtual queue that is both lower and upper bounded, allowing tight control of the constraint violation without the need for the Slater condition. We prove via a new Lyapunov drift analysis that COLDQ achieves $O(T^\frac{1+V_x}{2})$ dynamic regret and $O(T^{V_g})$ hard constraint violation, where $V_x$ and $V_g$ capture the dynamics of the loss and constraint functions. For the first time, the two bounds smoothly approach to the best-known $O(T^\frac{1}{2})$ regret and $O(1)$ violation, as the dynamics of the losses and constraints diminish. For strongly convex loss functions, COLDQ matches the best-known $O(\log{T})$ static regret while maintaining the $O(T^{V_g})$ hard constraint violation. We further introduce an expert-tracking variation of COLDQ, which achieves the same performance bounds without any prior knowledge of the system dynamics. Simulation results demonstrate that COLDQ outperforms the state-of-the-art approaches.
Survey on Knowledge Distillation for Large Language Models: Methods, Evaluation, and Application
Jul 02, 2024



Large Language Models (LLMs) have showcased exceptional capabilities in various domains, attracting significant interest from both academia and industry. Despite their impressive performance, the substantial size and computational demands of LLMs pose considerable challenges for practical deployment, particularly in environments with limited resources. The endeavor to compress language models while maintaining their accuracy has become a focal point of research. Among the various methods, knowledge distillation has emerged as an effective technique to enhance inference speed without greatly compromising performance. This paper presents a thorough survey from three aspects: method, evaluation, and application, exploring knowledge distillation techniques tailored specifically for LLMs. Specifically, we divide the methods into white-box KD and black-box KD to better illustrate their differences. Furthermore, we also explored the evaluation tasks and distillation effects between different distillation methods, and proposed directions for future research. Through in-depth understanding of the latest advancements and practical applications, this survey provides valuable resources for researchers, paving the way for sustained progress in this field.
A Novel Optimized Asynchronous Federated Learning Framework
Nov 18, 2021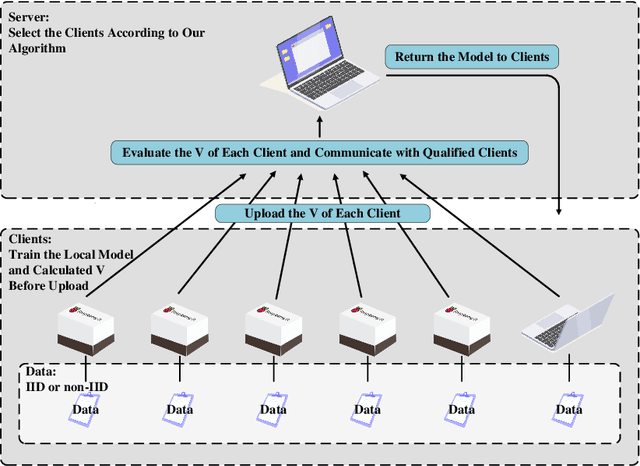
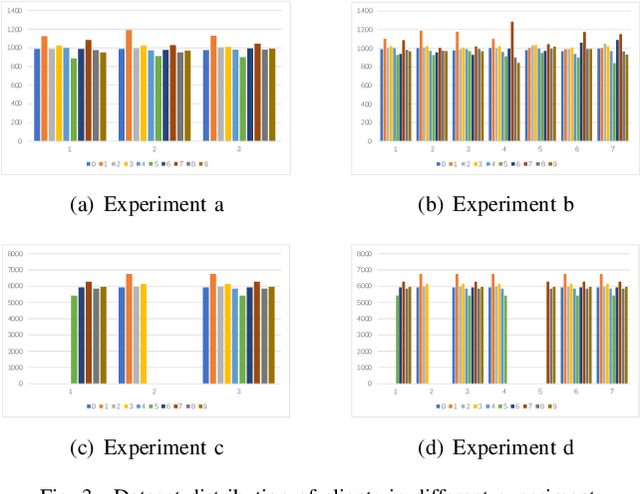
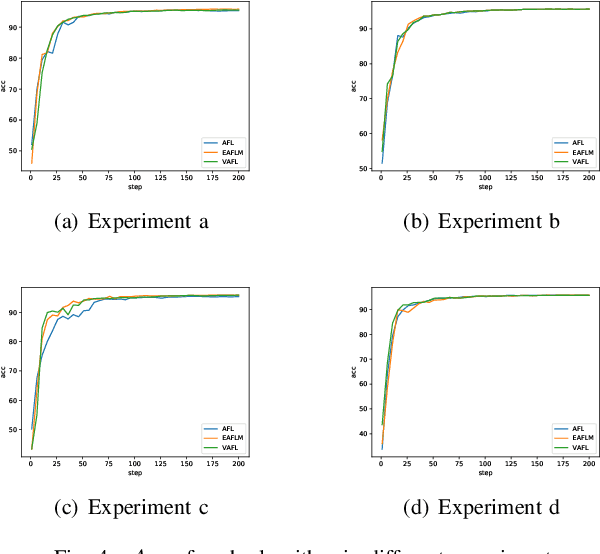
Federated Learning (FL) since proposed has been applied in many fields, such as credit assessment, medical, etc. Because of the difference in the network or computing resource, the clients may not update their gradients at the same time that may take a lot of time to wait or idle. That's why Asynchronous Federated Learning (AFL) method is needed. The main bottleneck in AFL is communication. How to find a balance between the model performance and the communication cost is a challenge in AFL. This paper proposed a novel AFL framework VAFL. And we verified the performance of the algorithm through sufficient experiments. The experiments show that VAFL can reduce the communication times about 51.02\% with 48.23\% average communication compression rate and allow the model to be converged faster. The code is available at \url{https://github.com/RobAI-Lab/VAFL}
A Real-time Contribution Measurement Method for Participants in Federated Learning
Sep 08, 2020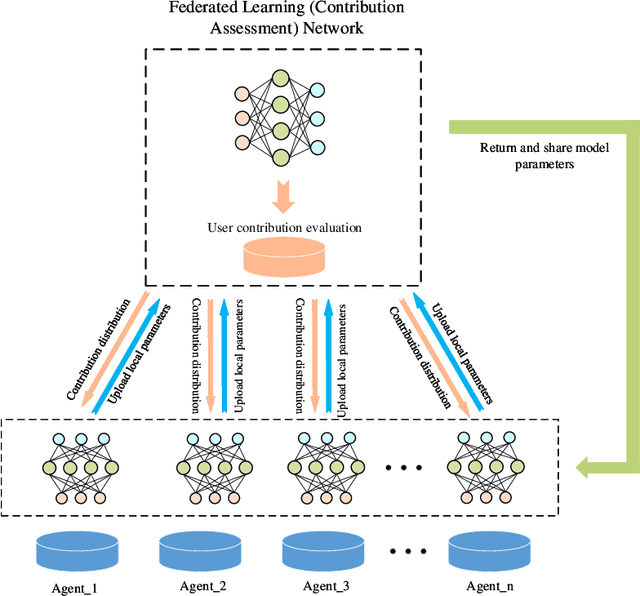
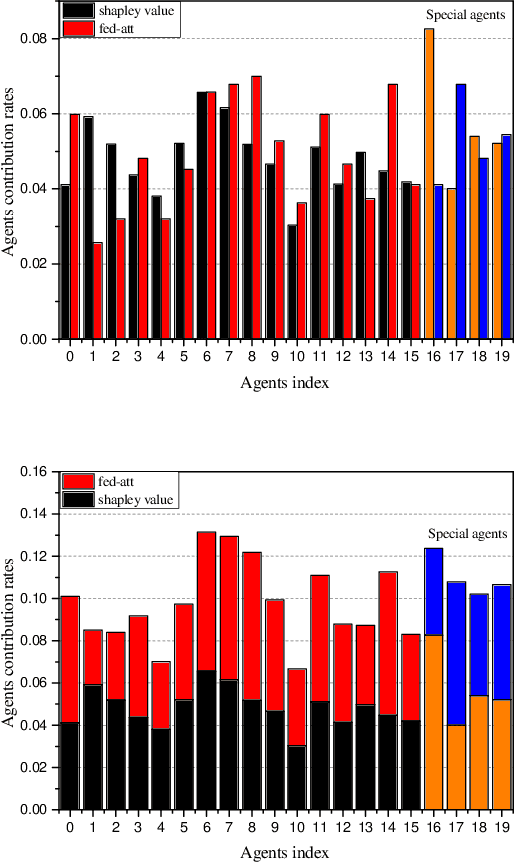
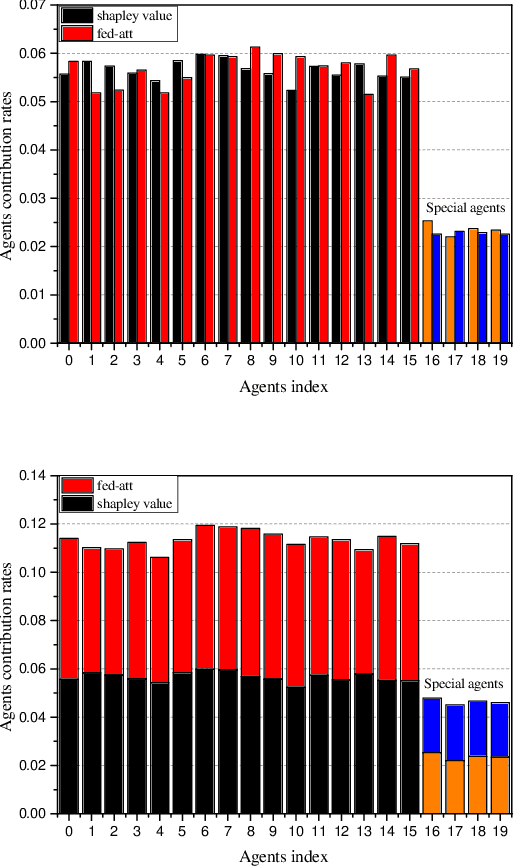
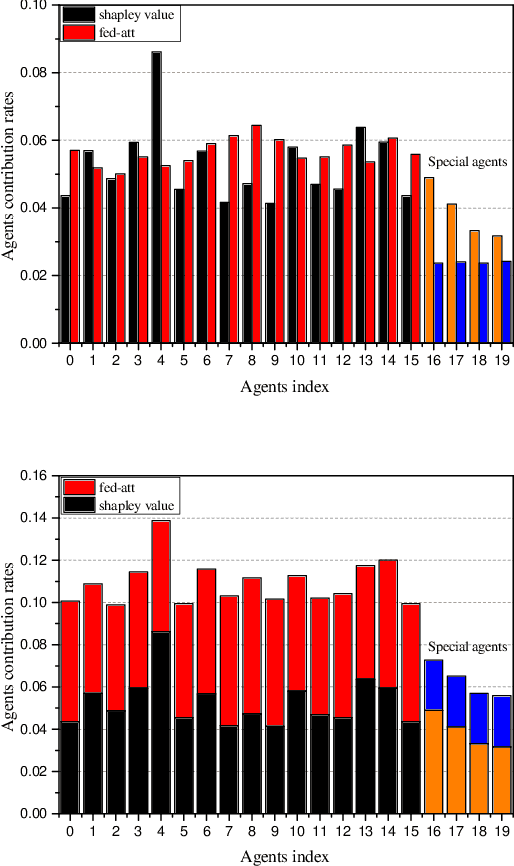
In recent years, individuals, business organizations or the country have paid more and more attention to their data privacy. At the same time, with the rise of federated learning, federated learning is involved in more and more fields. However, there is no good evaluation standard for each agent participating in federated learning. This paper proposes an online evaluation method for federated learning and compares it with the results obtained by Shapley Value in game theory. The method proposed in this paper is more sensitive to data quality and quantity.
Experiments of Federated Learning for COVID-19 Chest X-ray Images
Jul 05, 2020

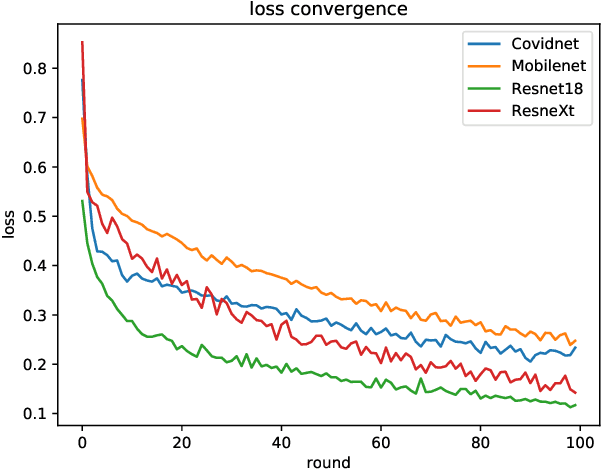
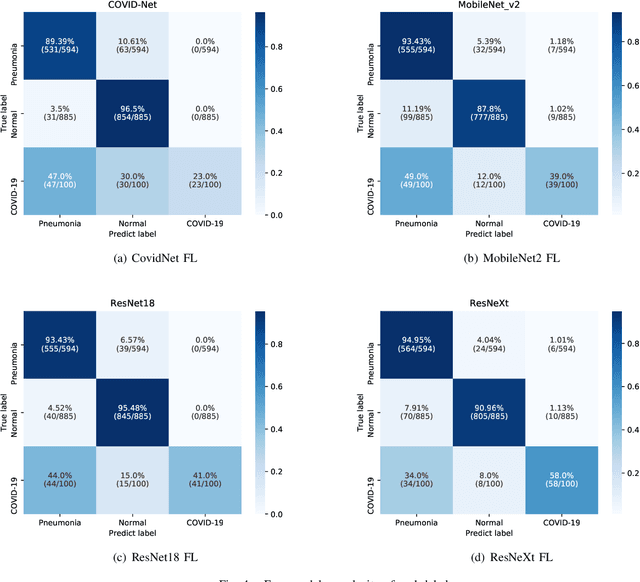
AI plays an important role in COVID-19 identification. Computer vision and deep learning techniques can assist in determining COVID-19 infection with Chest X-ray Images. However, for the protection and respect of the privacy of patients, the hospital's specific medical-related data did not allow leakage and sharing without permission. Collecting such training data was a major challenge. To a certain extent, this has caused a lack of sufficient data samples when performing deep learning approaches to detect COVID-19. Federated Learning is an available way to address this issue. It can effectively address the issue of data silos and get a shared model without obtaining local data. In the work, we propose the use of federated learning for COVID-19 data training and deploy experiments to verify the effectiveness. And we also compare performances of four popular models (MobileNet, ResNet18, MoblieNet, and COVID-Net) with the federated learning framework and without the framework. This work aims to inspire more researches on federated learning about COVID-19.