 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Boost-Driven Graph-Level Clustering Network
Apr 08, 2025



Graph-level clustering remains a pivotal yet formidable challenge in graph learning. Recently, the integration of deep learning with representation learning has demonstrated notable advancements, yielding performance enhancements to a certain degree. However, existing methods suffer from at least one of the following issues: 1. the original graph structure has noise, and 2. during feature propagation and pooling processes, noise is gradually aggregated into the graph-level embeddings through information propagation. Consequently, these two limitations mask clustering-friendly information, leading to suboptimal graph-level clustering performance. To this end, we propose a novel Dual Boost-Driven Graph-Level Clustering Network (DBGCN) to alternately promote graph-level clustering and filtering out interference information in a unified framework. Specifically, in the pooling step, we evaluate the contribution of features at the global and optimize them using a learnable transformation matrix to obtain high-quality graph-level representation, such that the model's reasoning capability can be improved. Moreover, to enable reliable graph-level clustering, we first identify and suppress information detrimental to clustering by evaluating similarities between graph-level representations, providing more accurate guidance for multi-view fusion. Extensive experiments demonstrated that DBGCN outperforms the state-of-the-art graph-level clustering methods on six benchmark datasets.
Improving Efficiency of DNN-based Relocalization Module for Autonomous Driving with Server-side Computing
Dec 01, 2023In this work, we present a novel framework for camera relocation in autonomous vehicles, leveraging deep neural networks (DNN). While existing literature offers various DNN-based camera relocation methods, their deployment is hindered by their high computational demands during inference. In contrast, our approach addresses this challenge through edge cloud collaboration. Specifically, we strategically offload certain modules of the neural network to the server and evaluate the inference time of data frames under different network segmentation schemes to guide our offloading decisions. Our findings highlight the vital role of server-side offloading in DNN-based camera relocation for autonomous vehicles, and we also discuss the results of data fusion. Finally, we validate the effectiveness of our proposed framework through experimental evaluation.
Revisiting Initializing Then Refining: An Incomplete and Missing Graph Imputation Network
Feb 15, 2023



With the development of various applications, such as social networks and knowledge graphs, graph data has been ubiquitous in the real world. Unfortunately, graphs usually suffer from being absent due to privacy-protecting policies or copyright restrictions during data collection. The absence of graph data can be roughly categorized into attribute-incomplete and attribute-missing circumstances. Specifically, attribute-incomplete indicates that a part of the attribute vectors of all nodes are incomplete, while attribute-missing indicates that the whole attribute vectors of partial nodes are missing. Although many efforts have been devoted, none of them is custom-designed for a common situation where both types of graph data absence exist simultaneously. To fill this gap, we develop a novel network termed Revisiting Initializing Then Refining (RITR), where we complete both attribute-incomplete and attribute-missing samples under the guidance of a novel initializing-then-refining imputation criterion. Specifically, to complete attribute-incomplete samples, we first initialize the incomplete attributes using Gaussian noise before network learning, and then introduce a structure-attribute consistency constraint to refine incomplete values by approximating a structure-attribute correlation matrix to a high-order structural matrix. To complete attribute-missing samples, we first adopt structure embeddings of attribute-missing samples as the embedding initialization, and then refine these initial values by adaptively aggregating the reliable information of attribute-incomplete samples according to a dynamic affinity structure. To the best of our knowledge, this newly designed method is the first unsupervised framework dedicated to handling hybrid-absent graphs. Extensive experiments on four datasets have verified that our methods consistently outperform existing state-of-the-art competitors.
FedVeca: Federated Vectorized Averaging on Non-IID Data with Adaptive Bi-directional Global Objective
Sep 28, 2022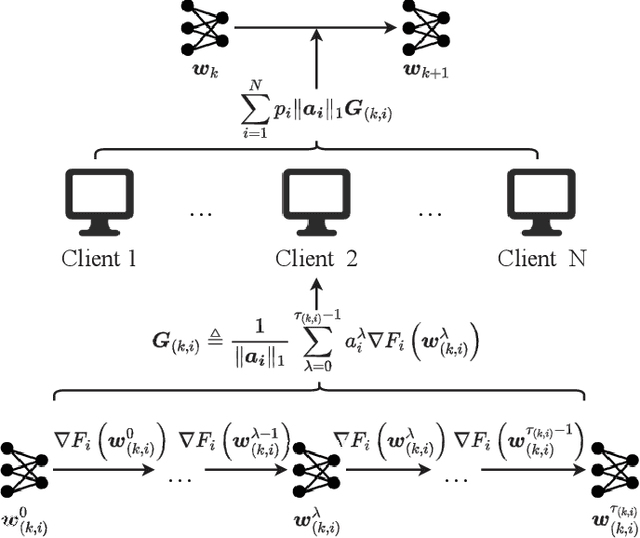
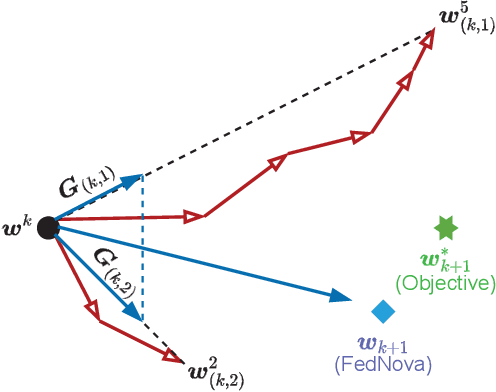
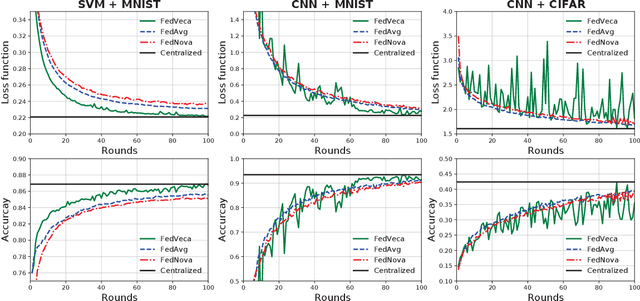
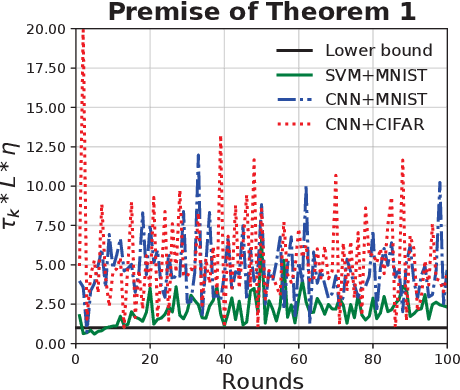
Federated Learning (FL) is a distributed machine learning framework to alleviate the data silos, where decentralized clients collaboratively learn a global model without sharing their private data. However, the clients' Non-Independent and Identically Distributed (Non-IID) data negatively affect the trained model, and clients with different numbers of local updates may cause significant gaps to the local gradients in each communication round. In this paper, we propose a Federated Vectorized Averaging (FedVeca) method to address the above problem on Non-IID data. Specifically, we set a novel objective for the global model which is related to the local gradients. The local gradient is defined as a bi-directional vector with step size and direction, where the step size is the number of local updates and the direction is divided into positive and negative according to our definition. In FedVeca, the direction is influenced by the step size, thus we average the bi-directional vectors to reduce the effect of different step sizes. Then, we theoretically analyze the relationship between the step sizes and the global objective, and obtain upper bounds on the step sizes per communication round. Based on the upper bounds, we design an algorithm for the server and the client to adaptively adjusts the step sizes that make the objective close to the optimum. Finally, we conduct experiments on different datasets, models and scenarios by building a prototype system, and the experimental results demonstrate the effectiveness and efficiency of the FedVeca method.
A Secure and Efficient Multi-Object Grasping Detection Approach for Robotic Arms
Sep 08, 2022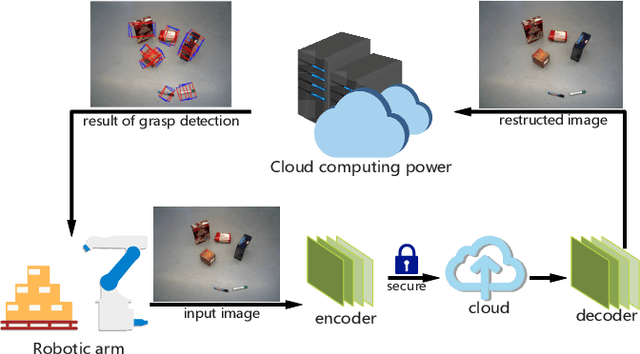



Robotic arms are widely used in automatic industries. However, with wide applications of deep learning in robotic arms, there are new challenges such as the allocation of grasping computing power and the growing demand for security. In this work, we propose a robotic arm grasping approach based on deep learning and edge-cloud collaboration. This approach realizes the arbitrary grasp planning of the robot arm and considers the grasp efficiency and information security. In addition, the encoder and decoder trained by GAN enable the images to be encrypted while compressing, which ensures the security of privacy. The model achieves 92% accuracy on the OCID dataset, the image compression ratio reaches 0.03%, and the structural difference value is higher than 0.91.
A Novel Optimized Asynchronous Federated Learning Framework
Nov 18, 2021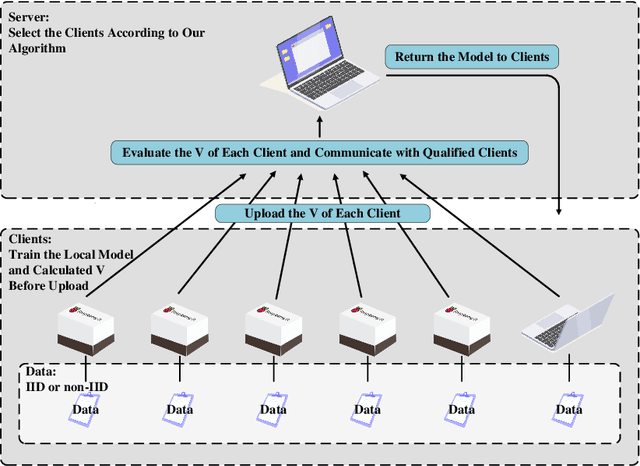
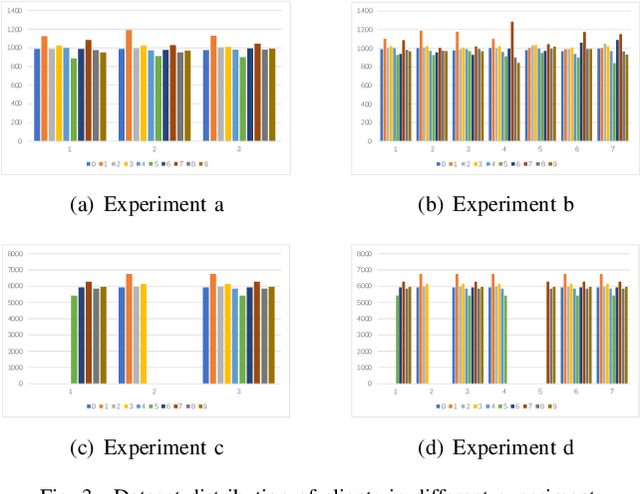
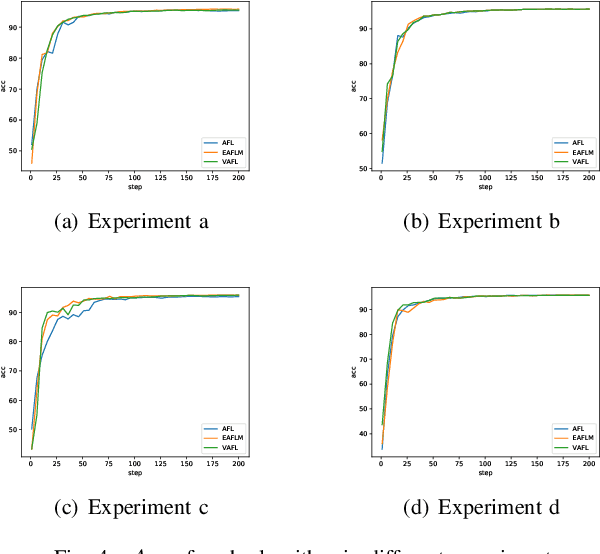
Federated Learning (FL) since proposed has been applied in many fields, such as credit assessment, medical, etc. Because of the difference in the network or computing resource, the clients may not update their gradients at the same time that may take a lot of time to wait or idle. That's why Asynchronous Federated Learning (AFL) method is needed. The main bottleneck in AFL is communication. How to find a balance between the model performance and the communication cost is a challenge in AFL. This paper proposed a novel AFL framework VAFL. And we verified the performance of the algorithm through sufficient experiments. The experiments show that VAFL can reduce the communication times about 51.02\% with 48.23\% average communication compression rate and allow the model to be converged faster. The code is available at \url{https://github.com/RobAI-Lab/VAFL}
Multi-Level Features Contrastive Networks for Unsupervised Domain Adaptation
Sep 14, 2021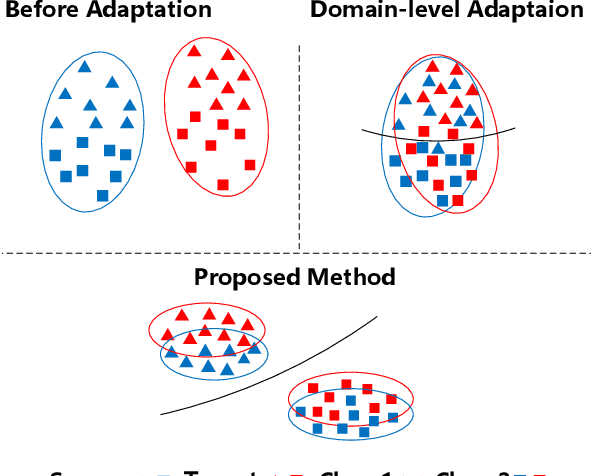
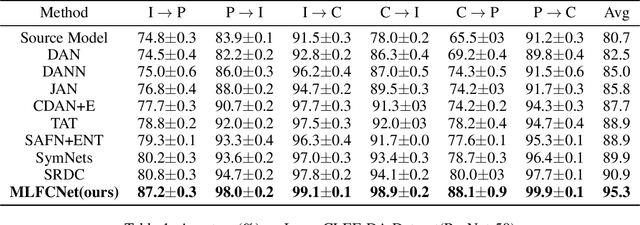

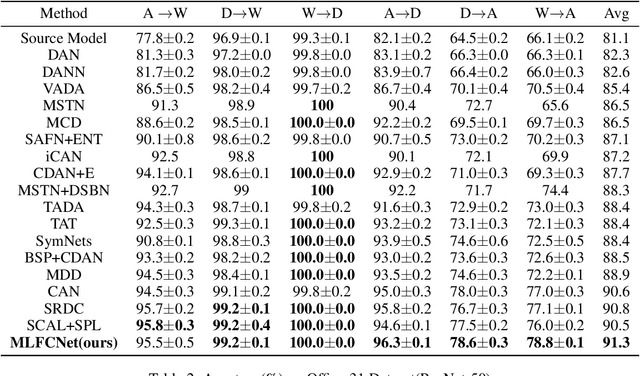
Unsupervised domain adaptation aims to train a model from the labeled source domain to make predictions on the unlabeled target domain when the data distribution of the two domains is different. As a result, it needs to reduce the data distribution difference between the two domains to improve the model's generalization ability. Existing methods tend to align the two domains directly at the domain-level, or perform class-level domain alignment based on deep feature. The former ignores the relationship between the various classes in the two domains, which may cause serious negative transfer, the latter alleviates it by introducing pseudo-labels of the target domain, but it does not consider the importance of performing class-level alignment on shallow feature representations. In this paper, we develop this work on the method of class-level alignment. The proposed method reduces the difference between two domains dramaticlly by aligning multi-level features. In the case that the two domains share the label space, the class-level alignment is implemented by introducing Multi-Level Feature Contrastive Networks (MLFCNet). In practice, since the categories of samples in target domain are unavailable, we iteratively use clustering algorithm to obtain the pseudo-labels, and then minimize Multi-Level Contrastive Discrepancy (MLCD) loss to achieve more accurate class-level alignment. Experiments on three real-world benchmarks ImageCLEF-DA, Office-31 and Office-Home demonstrate that MLFCNet compares favorably against the existing state-of-the-art domain adaptation methods.
Deep Fusion Clustering Network
Dec 15, 2020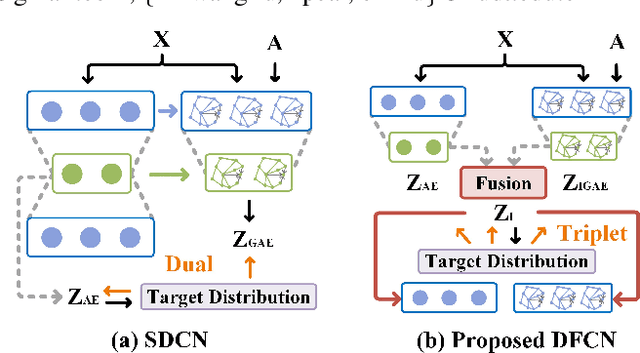
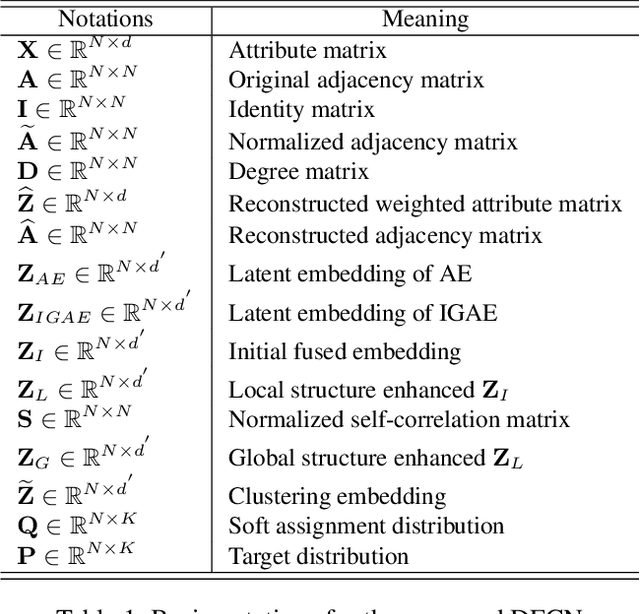
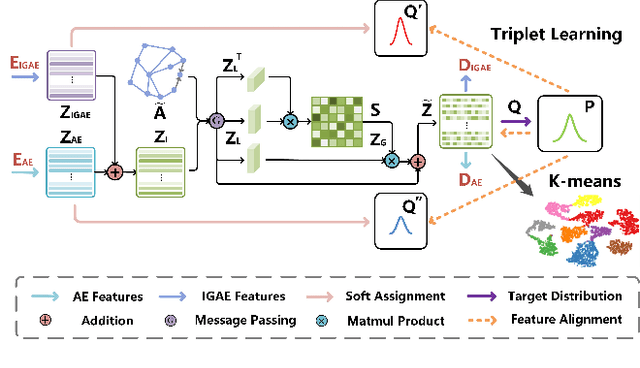

Deep clustering is a fundamental yet challenging task for data analysis. Recently we witness a strong tendency of combining autoencoder and graph neural networks to exploit structure information for clustering performance enhancement. However, we observe that existing literature 1) lacks a dynamic fusion mechanism to selectively integrate and refine the information of graph structure and node attributes for consensus representation learning; 2) fails to extract information from both sides for robust target distribution (i.e., "groundtruth" soft labels) generation. To tackle the above issues, we propose a Deep Fusion Clustering Network (DFCN). Specifically, in our network, an interdependency learning-based Structure and Attribute Information Fusion (SAIF) module is proposed to explicitly merge the representations learned by an autoencoder and a graph autoencoder for consensus representation learning. Also, a reliable target distribution generation measure and a triplet self-supervision strategy, which facilitate cross-modality information exploitation, are designed for network training. Extensive experiments on six benchmark datasets have demonstrated that the proposed DFCN consistently outperforms the state-of-the-art deep clustering methods.
Traffic Flow Combination Forecasting Method Based on Improved LSTM and ARIMA
Jun 25, 2019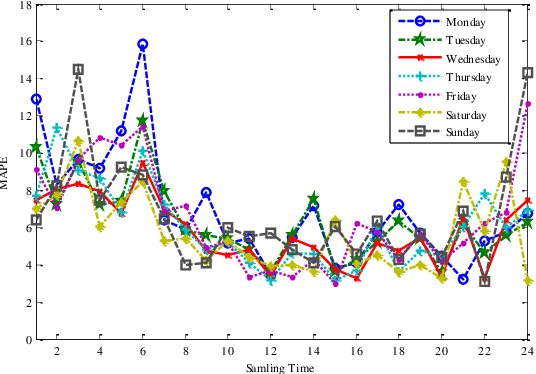

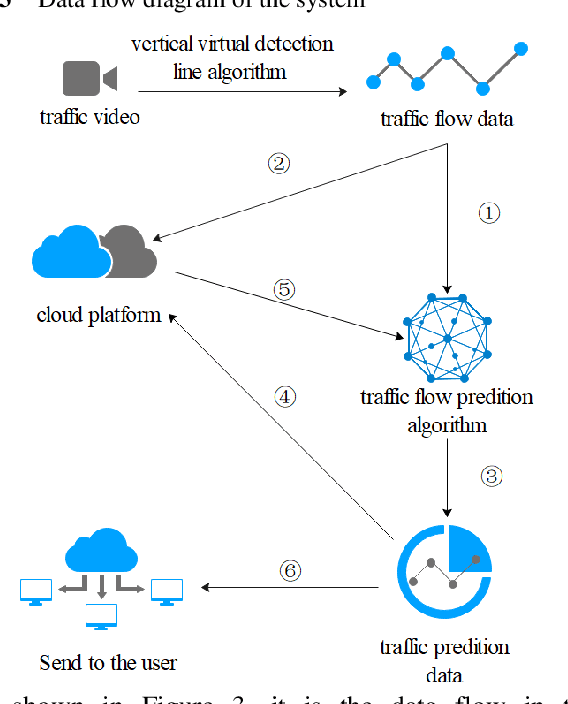
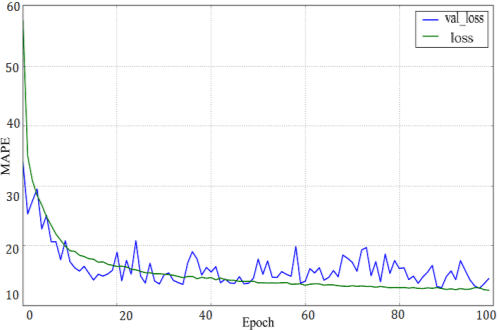
Traffic flow forecasting is hot spot research of intelligent traffic system construction. The existing traffic flow prediction methods have problems such as poor stability, high data requirements, or poor adaptability. In this paper, we define the traffic data time singularity ratio in the dropout module and propose a combination prediction method based on the improved long short-term memory neural network and time series autoregressive integrated moving average model (SDLSTM-ARIMA), which is derived from the Recurrent Neural Networks (RNN) model. It compares the traffic data time singularity with the probability value in the dropout module and combines them at unequal time intervals to achieve an accurate prediction of traffic flow data. Then, we design an adaptive traffic flow embedded system that can adapt to Java, Python and other languages and other interfaces. The experimental results demonstrate that the method based on the SDLSTM - ARIMA model has higher accuracy than the similar method using only autoregressive integrated moving average or autoregressive. Our embedded traffic prediction system integrating computer vision, machine learning and cloud has the advantages such as high accuracy, high reliability and low cost. Therefore, it has a wide application prospect.