 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Deep Graph Clustering: Taxonomy, Challenge, and Application
Nov 24, 2022



Graph clustering, which aims to divide the nodes in the graph into several distinct clusters, is a fundamental and challenging task. In recent years, deep graph clustering methods have been increasingly proposed and achieved promising performance. However, the corresponding survey paper is scarce and it is imminent to make a summary in this field. From this motivation, this paper makes the first comprehensive survey of deep graph clustering. Firstly, the detailed definition of deep graph clustering and the important baseline methods are introduced. Besides, the taxonomy of deep graph clustering methods is proposed based on four different criteria including graph type, network architecture, learning paradigm, and clustering method. In addition, through the careful analysis of the existing works, the challenges and opportunities from five perspectives are summarized. At last, the applications of deep graph clustering in four domains are presented. It is worth mentioning that a collection of state-of-the-art deep graph clustering methods including papers, codes, and datasets is available on GitHub. We hope this work will serve as a quick guide and help researchers to overcome challenges in this vibrant field.
Deep Distribution-preserving Incomplete Clustering with Optimal Transport
Mar 21, 2021

Clustering is a fundamental task in the computer vision and machine learning community. Although various methods have been proposed, the performance of existing approaches drops dramatically when handling incomplete high-dimensional data (which is common in real world applications). To solve the problem, we propose a novel deep incomplete clustering method, named Deep Distribution-preserving Incomplete Clustering with Optimal Transport (DDIC-OT). To avoid insufficient sample utilization in existing methods limited by few fully-observed samples, we propose to measure distribution distance with the optimal transport for reconstruction evaluation instead of traditional pixel-wise loss function. Moreover, the clustering loss of the latent feature is introduced to regularize the embedding with more discrimination capability. As a consequence, the network becomes more robust against missing features and the unified framework which combines clustering and sample imputation enables the two procedures to negotiate to better serve for each other. Extensive experiments demonstrate that the proposed network achieves superior and stable clustering performance improvement against existing state-of-the-art incomplete clustering methods over different missing ratios.
Deep Fusion Clustering Network
Dec 15, 2020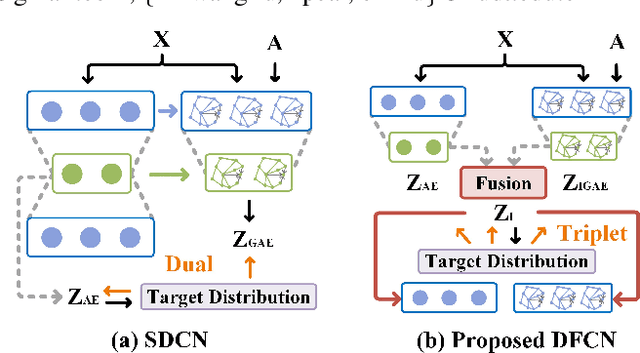
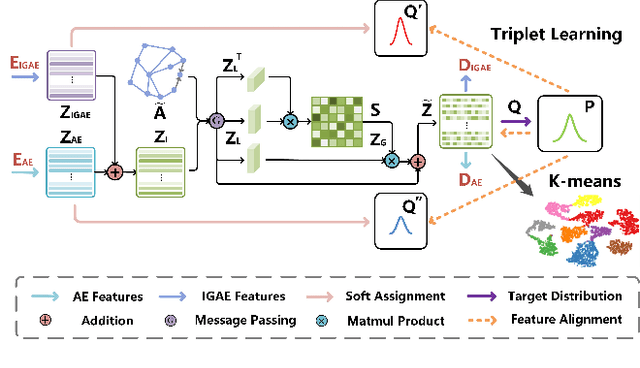

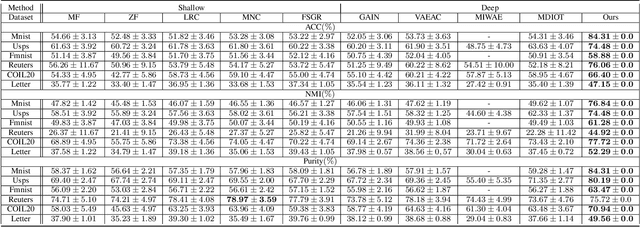
Deep clustering is a fundamental yet challenging task for data analysis. Recently we witness a strong tendency of combining autoencoder and graph neural networks to exploit structure information for clustering performance enhancement. However, we observe that existing literature 1) lacks a dynamic fusion mechanism to selectively integrate and refine the information of graph structure and node attributes for consensus representation learning; 2) fails to extract information from both sides for robust target distribution (i.e., "groundtruth" soft labels) generation. To tackle the above issues, we propose a Deep Fusion Clustering Network (DFCN). Specifically, in our network, an interdependency learning-based Structure and Attribute Information Fusion (SAIF) module is proposed to explicitly merge the representations learned by an autoencoder and a graph autoencoder for consensus representation learning. Also, a reliable target distribution generation measure and a triplet self-supervision strategy, which facilitate cross-modality information exploitation, are designed for network training. Extensive experiments on six benchmark datasets have demonstrated that the proposed DFCN consistently outperforms the state-of-the-art deep clustering methods.