 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedVeca: Federated Vectorized Averaging on Non-IID Data with Adaptive Bi-directional Global Objective
Sep 28, 2022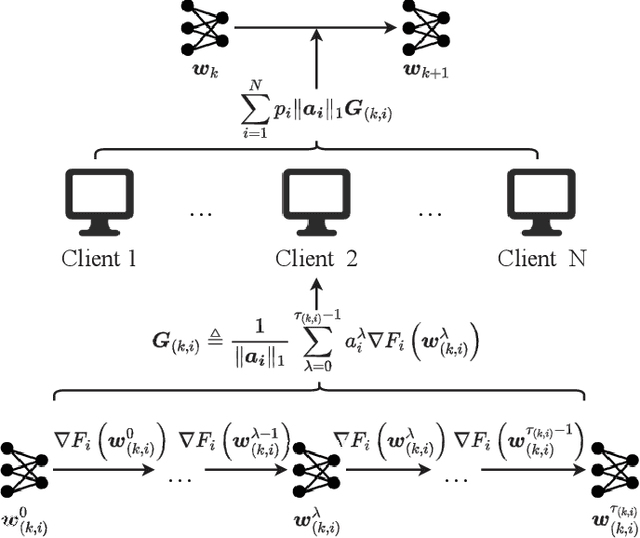
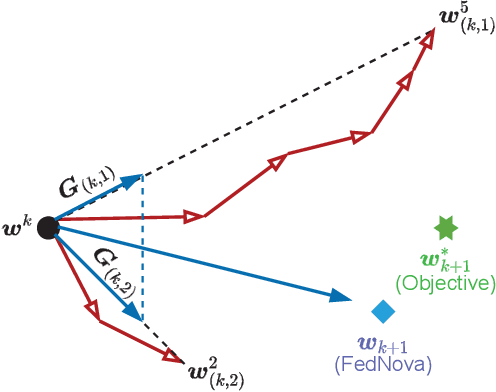
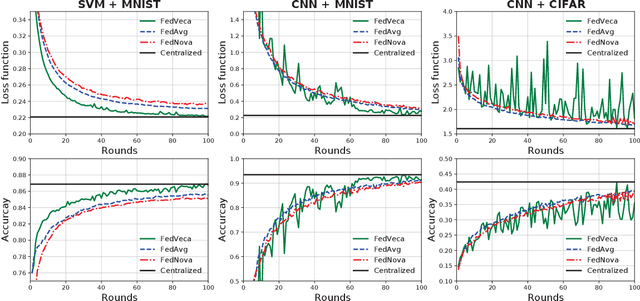
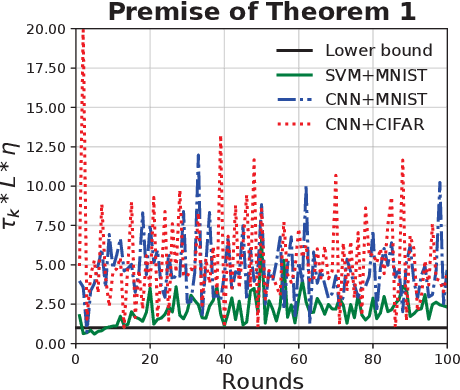
Federated Learning (FL) is a distributed machine learning framework to alleviate the data silos, where decentralized clients collaboratively learn a global model without sharing their private data. However, the clients' Non-Independent and Identically Distributed (Non-IID) data negatively affect the trained model, and clients with different numbers of local updates may cause significant gaps to the local gradients in each communication round. In this paper, we propose a Federated Vectorized Averaging (FedVeca) method to address the above problem on Non-IID data. Specifically, we set a novel objective for the global model which is related to the local gradients. The local gradient is defined as a bi-directional vector with step size and direction, where the step size is the number of local updates and the direction is divided into positive and negative according to our definition. In FedVeca, the direction is influenced by the step size, thus we average the bi-directional vectors to reduce the effect of different step sizes. Then, we theoretically analyze the relationship between the step sizes and the global objective, and obtain upper bounds on the step sizes per communication round. Based on the upper bounds, we design an algorithm for the server and the client to adaptively adjusts the step sizes that make the objective close to the optimum. Finally, we conduct experiments on different datasets, models and scenarios by building a prototype system, and the experimental results demonstrate the effectiveness and efficiency of the FedVeca method.
ViWi: A Deep Learning Dataset Framework for Vision-Aided Wireless Communications
Nov 14, 2019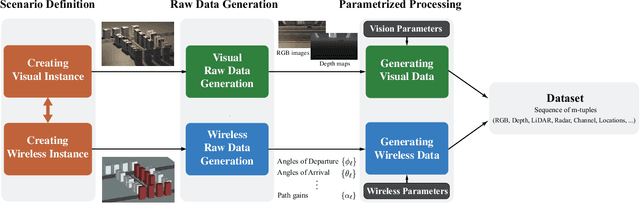
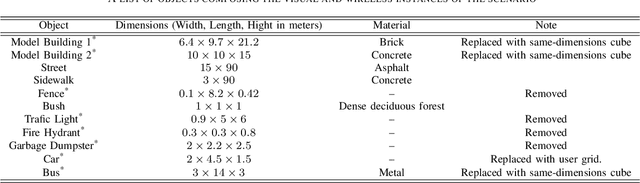
The growing role that artificial intelligence and specifically machine learning is playing in shaping the future of wireless communications has opened up many new and intriguing research directions. This paper motivates the research in the novel direction of \textit{vision-aided wireless communications}, which aims at leveraging visual sensory information in tackling wireless communication problems. Like any new research direction driven by machine learning, obtaining a development dataset poses the first and most important challenge to vision-aided wireless communications. This paper addresses this issue by introducing the Vision-Wireless (ViWi) dataset framework. It is developed to be a parametric, systematic, and scalable data generation framework. It utilizes advanced 3D-modeling and ray-tracing softwares to generate high-fidelity synthetic wireless and vision data samples for the same scenes. The result is a framework that does not only offer a way to generate training and testing datasets but helps provide a common ground on which the quality of different machine learning-powered solutions could be assessed.