 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Transit Obfuscation Problem
Feb 13, 2024



Concealing an intermediate point on a route or visible from a route is an important goal in some transportation and surveillance scenarios. This paper studies the Transit Obfuscation Problem, the problem of traveling from some start location to an end location while "covering" a specific transit point that needs to be concealed from adversaries. We propose the notion of transit anonymity, a quantitative guarantee of the anonymity of a specific transit point, even with a powerful adversary with full knowledge of the path planning algorithm. We propose and evaluate planning/search algorithms that satisfy this anonymity criterion.
AIJack: Security and Privacy Risk Simulator for Machine Learning
Dec 29, 2023
This paper introduces AIJack, an open-source library designed to assess security and privacy risks associated with the training and deployment of machine learning models. Amid the growing interest in big data and AI, advancements in machine learning research and business are accelerating. However, recent studies reveal potential threats, such as the theft of training data and the manipulation of models by malicious attackers. Therefore, a comprehensive understanding of machine learning's security and privacy vulnerabilities is crucial for the safe integration of machine learning into real-world products. AIJack aims to address this need by providing a library with various attack and defense methods through a unified API. The library is publicly available on GitHub (https://github.com/Koukyosyumei/AIJack).
VFLAIR: A Research Library and Benchmark for Vertical Federated Learning
Oct 15, 2023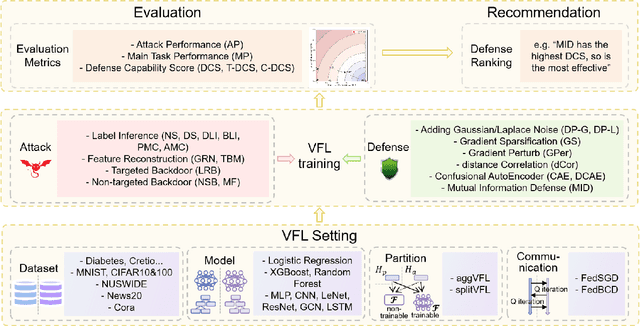


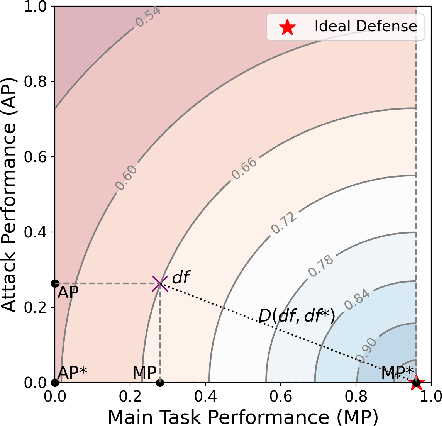
Vertical Federated Learning (VFL) has emerged as a collaborative training paradigm that allows participants with different features of the same group of users to accomplish cooperative training without exposing their raw data or model parameters. VFL has gained significant attention for its research potential and real-world applications in recent years, but still faces substantial challenges, such as in defending various kinds of data inference and backdoor attacks. Moreover, most of existing VFL projects are industry-facing and not easily used for keeping track of the current research progress. To address this need, we present an extensible and lightweight VFL framework VFLAIR (available at https://github.com/FLAIR-THU/VFLAIR), which supports VFL training with a variety of models, datasets and protocols, along with standardized modules for comprehensive evaluations of attacks and defense strategies. We also benchmark 11 attacks and 8 defenses performance under different communication and model partition settings and draw concrete insights and recommendations on the choice of defense strategies for different practical VFL deployment scenario.
Eliminating Label Leakage in Tree-Based Vertical Federated Learning
Jul 19, 2023



Vertical federated learning (VFL) enables multiple parties with disjoint features of a common user set to train a machine learning model without sharing their private data. Tree-based models have become prevalent in VFL due to their interpretability and efficiency. However, the vulnerability of tree-based VFL has not been sufficiently investigated. In this study, we first introduce a novel label inference attack, ID2Graph, which utilizes the sets of record-IDs assigned to each node (i.e., instance space) to deduce private training labels. The ID2Graph attack generates a graph structure from training samples, extracts communities from the graph, and clusters the local dataset using community information. To counteract label leakage from the instance space, we propose an effective defense mechanism, ID-LMID, which prevents label leakage by focusing on mutual information regularization. Comprehensive experiments conducted on various datasets reveal that the ID2Graph attack presents significant risks to tree-based models such as Random Forest and XGBoost. Further evaluations on these benchmarks demonstrate that ID-LMID effectively mitigates label leakage in such instances.
Breaching FedMD: Image Recovery via Paired-Logits Inversion Attack
Apr 22, 2023Federated Learning with Model Distillation (FedMD) is a nascent collaborative learning paradigm, where only output logits of public datasets are transmitted as distilled knowledge, instead of passing on private model parameters that are susceptible to gradient inversion attacks, a known privacy risk in federated learning. In this paper, we found that even though sharing output logits of public datasets is safer than directly sharing gradients, there still exists a substantial risk of data exposure caused by carefully designed malicious attacks. Our study shows that a malicious server can inject a PLI (Paired-Logits Inversion) attack against FedMD and its variants by training an inversion neural network that exploits the confidence gap between the server and client models. Experiments on multiple facial recognition datasets validate that under FedMD-like schemes, by using paired server-client logits of public datasets only, the malicious server is able to reconstruct private images on all tested benchmarks with a high success rate.