 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternBootcamp Technical Report: Boosting LLM Reasoning with Verifiable Task Scaling
Aug 12, 2025



Large language models (LLMs) have revolutionized artificial intelligence by enabling complex reasoning capabilities. While recent advancements in reinforcement learning (RL) have primarily focused on domain-specific reasoning tasks (e.g., mathematics or code generation), real-world reasoning scenarios often require models to handle diverse and complex environments that narrow-domain benchmarks cannot fully capture. To address this gap, we present InternBootcamp, an open-source framework comprising 1000+ domain-diverse task environments specifically designed for LLM reasoning research. Our codebase offers two key functionalities: (1) automated generation of unlimited training/testing cases with configurable difficulty levels, and (2) integrated verification modules for objective response evaluation. These features make InternBootcamp fundamental infrastructure for RL-based model optimization, synthetic data generation, and model evaluation. Although manually developing such a framework with enormous task coverage is extremely cumbersome, we accelerate the development procedure through an automated agent workflow supplemented by manual validation protocols, which enables the task scope to expand rapidly. % With these bootcamps, we further establish Bootcamp-EVAL, an automatically generated benchmark for comprehensive performance assessment. Evaluation reveals that frontier models still underperform in many reasoning tasks, while training with InternBootcamp provides an effective way to significantly improve performance, leading to our 32B model that achieves state-of-the-art results on Bootcamp-EVAL and excels on other established benchmarks. In particular, we validate that consistent performance gains come from including more training tasks, namely \textbf{task scaling}, over two orders of magnitude, offering a promising route towards capable reasoning generalist.
FedMABench: Benchmarking Mobile Agents on Decentralized Heterogeneous User Data
Mar 07, 2025Mobile agents have attracted tremendous research participation recently. Traditional approaches to mobile agent training rely on centralized data collection, leading to high cost and limited scalability. Distributed training utilizing federated learning offers an alternative by harnessing real-world user data, providing scalability and reducing costs. However, pivotal challenges, including the absence of standardized benchmarks, hinder progress in this field. To tackle the challenges, we introduce FedMABench, the first benchmark for federated training and evaluation of mobile agents, specifically designed for heterogeneous scenarios. FedMABench features 6 datasets with 30+ subsets, 8 federated algorithms, 10+ base models, and over 800 apps across 5 categories, providing a comprehensive framework for evaluating mobile agents across diverse environments. Through extensive experiments, we uncover several key insights: federated algorithms consistently outperform local training; the distribution of specific apps plays a crucial role in heterogeneity; and, even apps from distinct categories can exhibit correlations during training. FedMABench is publicly available at: https://github.com/wwh0411/FedMABench with the datasets at: https://huggingface.co/datasets/wwh0411/FedMABench.
FedMobileAgent: Training Mobile Agents Using Decentralized Self-Sourced Data from Diverse Users
Feb 05, 2025



The advancement of mobile agents has opened new opportunities for automating tasks on mobile devices. Training these agents requires large-scale high-quality data, which is costly using human labor. Given the vast number of mobile phone users worldwide, if automated data collection from them is feasible, the resulting data volume and the subsequently trained mobile agents could reach unprecedented levels. Nevertheless, two major challenges arise: (1) extracting high-level and low-level user instructions without involving human and (2) utilizing distributed data from diverse users while preserving privacy. To tackle these challenges, we propose FedMobileAgent, a collaborative framework that trains mobile agents using self-sourced data from diverse users. Specifically, it includes two techniques. First, we propose Auto-Annotation, which enables the automatic collection of high-quality datasets during users' routine phone usage with minimal cost. Second, we introduce adapted aggregation to improve federated training of mobile agents on non-IID user data, by incorporating both episode- and step-level distributions. In distributed settings, FedMobileAgent achieves performance comparable to centralized human-annotated models at less than 0.02\% of the cost, highlighting its potential for real-world applications.
Self-Evolving Multi-Agent Collaboration Networks for Software Development
Oct 22, 2024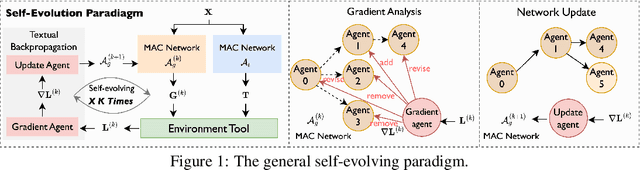


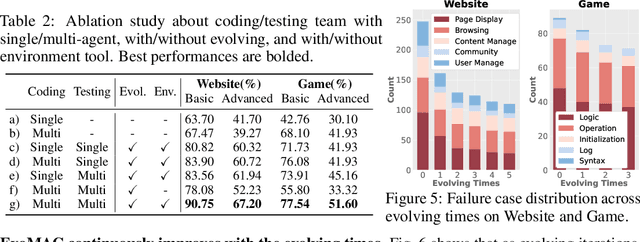
LLM-driven multi-agent collaboration (MAC) systems have demonstrated impressive capabilities in automatic software development at the function level. However, their heavy reliance on human design limits their adaptability to the diverse demands of real-world software development. To address this limitation, we introduce EvoMAC, a novel self-evolving paradigm for MAC networks. Inspired by traditional neural network training, EvoMAC obtains text-based environmental feedback by verifying the MAC network's output against a target proxy and leverages a novel textual backpropagation to update the network. To extend coding capabilities beyond function-level tasks to more challenging software-level development, we further propose rSDE-Bench, a requirement-oriented software development benchmark, which features complex and diverse software requirements along with automatic evaluation of requirement correctness. Our experiments show that: i) The automatic requirement-aware evaluation in rSDE-Bench closely aligns with human evaluations, validating its reliability as a software-level coding benchmark. ii) EvoMAC outperforms previous SOTA methods on both the software-level rSDE-Bench and the function-level HumanEval benchmarks, reflecting its superior coding capabilities. The benchmark can be downloaded at https://yuzhu-cai.github.io/rSDE-Bench/.