 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentIF-OneDay: A Task-level Instruction-Following Benchmark for General AI Agents in Daily Scenarios
Jan 28, 2026The capacity of AI agents to effectively handle tasks of increasing duration and complexity continues to grow, demonstrating exceptional performance in coding, deep research, and complex problem-solving evaluations. However, in daily scenarios, the perception of these advanced AI capabilities among general users remains limited. We argue that current evaluations prioritize increasing task difficulty without sufficiently addressing the diversity of agentic tasks necessary to cover the daily work, life, and learning activities of a broad demographic. To address this, we propose AgentIF-OneDay, aimed at determining whether general users can utilize natural language instructions and AI agents to complete a diverse array of daily tasks. These tasks require not only solving problems through dialogue but also understanding various attachment types and delivering tangible file-based results. The benchmark is structured around three user-centric categories: Open Workflow Execution, which assesses adherence to explicit and complex workflows; Latent Instruction, which requires agents to infer implicit instructions from attachments; and Iterative Refinement, which involves modifying or expanding upon ongoing work. We employ instance-level rubrics and a refined evaluation pipeline that aligns LLM-based verification with human judgment, achieving an 80.1% agreement rate using Gemini-3-Pro. AgentIF-OneDay comprises 104 tasks covering 767 scoring points. We benchmarked four leading general AI agents and found that agent products built based on APIs and ChatGPT agents based on agent RL remain in the first tier simultaneously. Leading LLM APIs and open-source models have internalized agentic capabilities, enabling AI application teams to develop cutting-edge Agent products.
AION: Aerial Indoor Object-Goal Navigation Using Dual-Policy Reinforcement Learning
Jan 22, 2026Object-Goal Navigation (ObjectNav) requires an agent to autonomously explore an unknown environment and navigate toward target objects specified by a semantic label. While prior work has primarily studied zero-shot ObjectNav under 2D locomotion, extending it to aerial platforms with 3D locomotion capability remains underexplored. Aerial robots offer superior maneuverability and search efficiency, but they also introduce new challenges in spatial perception, dynamic control, and safety assurance. In this paper, we propose AION for vision-based aerial ObjectNav without relying on external localization or global maps. AION is an end-to-end dual-policy reinforcement learning (RL) framework that decouples exploration and goal-reaching behaviors into two specialized policies. We evaluate AION on the AI2-THOR benchmark and further assess its real-time performance in IsaacSim using high-fidelity drone models. Experimental results show that AION achieves superior performance across comprehensive evaluation metrics in exploration, navigation efficiency, and safety. The video can be found at https://youtu.be/TgsUm6bb7zg.
GNNs as Predictors of Agentic Workflow Performances
Mar 14, 2025Agentic workflows invoked by Large Language Models (LLMs) have achieved remarkable success in handling complex tasks. However, optimizing such workflows is costly and inefficient in real-world applications due to extensive invocations of LLMs. To fill this gap, this position paper formulates agentic workflows as computational graphs and advocates Graph Neural Networks (GNNs) as efficient predictors of agentic workflow performances, avoiding repeated LLM invocations for evaluation. To empirically ground this position, we construct FLORA-Bench, a unified platform for benchmarking GNNs for predicting agentic workflow performances. With extensive experiments, we arrive at the following conclusion: GNNs are simple yet effective predictors. This conclusion supports new applications of GNNs and a novel direction towards automating agentic workflow optimization. All codes, models, and data are available at https://github.com/youngsoul0731/Flora-Bench.
Self-Evolving Multi-Agent Collaboration Networks for Software Development
Oct 22, 2024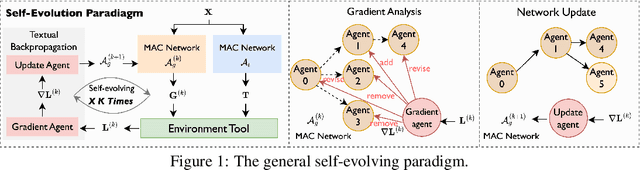


LLM-driven multi-agent collaboration (MAC) systems have demonstrated impressive capabilities in automatic software development at the function level. However, their heavy reliance on human design limits their adaptability to the diverse demands of real-world software development. To address this limitation, we introduce EvoMAC, a novel self-evolving paradigm for MAC networks. Inspired by traditional neural network training, EvoMAC obtains text-based environmental feedback by verifying the MAC network's output against a target proxy and leverages a novel textual backpropagation to update the network. To extend coding capabilities beyond function-level tasks to more challenging software-level development, we further propose rSDE-Bench, a requirement-oriented software development benchmark, which features complex and diverse software requirements along with automatic evaluation of requirement correctness. Our experiments show that: i) The automatic requirement-aware evaluation in rSDE-Bench closely aligns with human evaluations, validating its reliability as a software-level coding benchmark. ii) EvoMAC outperforms previous SOTA methods on both the software-level rSDE-Bench and the function-level HumanEval benchmarks, reflecting its superior coding capabilities. The benchmark can be downloaded at https://yuzhu-cai.github.io/rSDE-Bench/.