 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic DLM+: Improving Diffusion Language Models through Bias-variance Trade-off in Transition Kernel Design
Jun 13, 2026Diffusion Language Models (DLMs) have demonstrated strong scaling capacity as alternatives to autoregressive language models. However, their performance is highly sensitive to the choice of transition kernels, and poorly designed kernels can lead to issues like training instability, slow convergence, and biased sampling. In this paper, we study this sensitivity through a principled analysis of generalization error and identify three critical factors: asymptotic bias (difficulty in approximating the posterior distribution), exposure bias (error propagation during sampling), and optimization variance induced by kernel dispersion. We further compare different transition kernels: masking diffusion yields sparse and easier posterior-approximation targets, while uniform diffusion provides stronger sampling-side repair but induces harder approximation. Motivated by this trade-off, we revisit a previously overlooked variant, semantic DLM (SemDLM), where the transition kernel corrupts tokens to neighborhoods that are semantically similar. Our theory suggests that SemDLM can serve as a plausible middle ground by reducing the posterior approximation difficulty of uniform diffusion while retaining repair ability. However, we find that SemDLM suffers from a semantic basin problem, where sampling repeatedly stays within a semantic region and produces low-diversity text. To address this, we propose SemDLM+, which adds a global transition and a semantic-frequency penalty during sampling. Experiments on LM1B and OpenWebText show that SemDLM+ improves training dynamics and achieves competitive language modeling and generation quality with satisfactory diversity.
On the Importance of Task Complexity in Evaluating LLM-Based Multi-Agent Systems
Oct 05, 2025Large language model multi-agent systems (LLM-MAS) offer a promising paradigm for harnessing collective intelligence to achieve more advanced forms of AI behaviour. While recent studies suggest that LLM-MAS can outperform LLM single-agent systems (LLM-SAS) on certain tasks, the lack of systematic experimental designs limits the strength and generality of these conclusions. We argue that a principled understanding of task complexity, such as the degree of sequential reasoning required and the breadth of capabilities involved, is essential for assessing the effectiveness of LLM-MAS in task solving. To this end, we propose a theoretical framework characterising tasks along two dimensions: depth, representing reasoning length, and width, representing capability diversity. We theoretically examine a representative class of LLM-MAS, namely the multi-agent debate system, and empirically evaluate its performance in both discriminative and generative tasks with varying depth and width. Theoretical and empirical results show that the benefit of LLM-MAS over LLM-SAS increases with both task depth and width, and the effect is more pronounced with respect to depth. This clarifies when LLM-MAS are beneficial and provides a principled foundation for designing future LLM-MAS methods and benchmarks.
MASLab: A Unified and Comprehensive Codebase for LLM-based Multi-Agent Systems
May 22, 2025LLM-based multi-agent systems (MAS) have demonstrated significant potential in enhancing single LLMs to address complex and diverse tasks in practical applications. Despite considerable advancements, the field lacks a unified codebase that consolidates existing methods, resulting in redundant re-implementation efforts, unfair comparisons, and high entry barriers for researchers. To address these challenges, we introduce MASLab, a unified, comprehensive, and research-friendly codebase for LLM-based MAS. (1) MASLab integrates over 20 established methods across multiple domains, each rigorously validated by comparing step-by-step outputs with its official implementation. (2) MASLab provides a unified environment with various benchmarks for fair comparisons among methods, ensuring consistent inputs and standardized evaluation protocols. (3) MASLab implements methods within a shared streamlined structure, lowering the barriers for understanding and extension. Building on MASLab, we conduct extensive experiments covering 10+ benchmarks and 8 models, offering researchers a clear and comprehensive view of the current landscape of MAS methods. MASLab will continue to evolve, tracking the latest developments in the field, and invite contributions from the broader open-source community.
ViMo: A Generative Visual GUI World Model for App Agent
Apr 15, 2025App agents, which autonomously operate mobile Apps through Graphical User Interfaces (GUIs), have gained significant interest in real-world applications. Yet, they often struggle with long-horizon planning, failing to find the optimal actions for complex tasks with longer steps. To address this, world models are used to predict the next GUI observation based on user actions, enabling more effective agent planning. However, existing world models primarily focus on generating only textual descriptions, lacking essential visual details. To fill this gap, we propose ViMo, the first visual world model designed to generate future App observations as images. For the challenge of generating text in image patches, where even minor pixel errors can distort readability, we decompose GUI generation into graphic and text content generation. We propose a novel data representation, the Symbolic Text Representation~(STR) to overlay text content with symbolic placeholders while preserving graphics. With this design, ViMo employs a STR Predictor to predict future GUIs' graphics and a GUI-text Predictor for generating the corresponding text. Moreover, we deploy ViMo to enhance agent-focused tasks by predicting the outcome of different action options. Experiments show ViMo's ability to generate visually plausible and functionally effective GUIs that enable App agents to make more informed decisions.
GNNs as Predictors of Agentic Workflow Performances
Mar 14, 2025Agentic workflows invoked by Large Language Models (LLMs) have achieved remarkable success in handling complex tasks. However, optimizing such workflows is costly and inefficient in real-world applications due to extensive invocations of LLMs. To fill this gap, this position paper formulates agentic workflows as computational graphs and advocates Graph Neural Networks (GNNs) as efficient predictors of agentic workflow performances, avoiding repeated LLM invocations for evaluation. To empirically ground this position, we construct FLORA-Bench, a unified platform for benchmarking GNNs for predicting agentic workflow performances. With extensive experiments, we arrive at the following conclusion: GNNs are simple yet effective predictors. This conclusion supports new applications of GNNs and a novel direction towards automating agentic workflow optimization. All codes, models, and data are available at https://github.com/youngsoul0731/Flora-Bench.
Heterogeneous Graph Structure Learning through the Lens of Data-generating Processes
Mar 11, 2025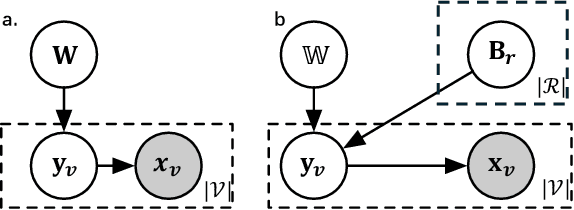



Inferring the graph structure from observed data is a key task in graph machine learning to capture the intrinsic relationship between data entities. While significant advancements have been made in learning the structure of homogeneous graphs, many real-world graphs exhibit heterogeneous patterns where nodes and edges have multiple types. This paper fills this gap by introducing the first approach for heterogeneous graph structure learning (HGSL). To this end, we first propose a novel statistical model for the data-generating process (DGP) of heterogeneous graph data, namely hidden Markov networks for heterogeneous graphs (H2MN). Then we formalize HGSL as a maximum a-posterior estimation problem parameterized by such DGP and derive an alternating optimization method to obtain a solution together with a theoretical justification of the optimization conditions. Finally, we conduct extensive experiments on both synthetic and real-world datasets to demonstrate that our proposed method excels in learning structure on heterogeneous graphs in terms of edge type identification and edge weight recovery.
Motion Graph Unleashed: A Novel Approach to Video Prediction
Oct 29, 2024We introduce motion graph, a novel approach to the video prediction problem, which predicts future video frames from limited past data. The motion graph transforms patches of video frames into interconnected graph nodes, to comprehensively describe the spatial-temporal relationships among them. This representation overcomes the limitations of existing motion representations such as image differences, optical flow, and motion matrix that either fall short in capturing complex motion patterns or suffer from excessive memory consumption. We further present a video prediction pipeline empowered by motion graph, exhibiting substantial performance improvements and cost reductions. Experiments on various datasets, including UCF Sports, KITTI and Cityscapes, highlight the strong representative ability of motion graph. Especially on UCF Sports, our method matches and outperforms the SOTA methods with a significant reduction in model size by 78% and a substantial decrease in GPU memory utilization by 47%.
Synthesizing Post-Training Data for LLMs through Multi-Agent Simulation
Oct 18, 2024Post-training is essential for enabling large language models (LLMs) to follow human instructions. Inspired by the recent success of using LLMs to simulate human society, we leverage multi-agent simulation to automatically generate diverse text-based scenarios, capturing a wide range of real-world human needs. We propose MATRIX, a multi-agent simulator that creates realistic and scalable scenarios. Leveraging these outputs, we introduce a novel scenario-driven instruction generator MATRIX-Gen for controllable and highly realistic data synthesis. Extensive experiments demonstrate that our framework effectively generates both general and domain-specific data. Notably, on AlpacaEval 2 and Arena-Hard benchmarks, Llama-3-8B-Base, post-trained on datasets synthesized by MATRIX-Gen with just 20K instruction-response pairs, outperforms Meta's Llama-3-8B-Instruct model, which was trained on over 10M pairs; see our project at https://github.com/ShuoTang123/MATRIX-Gen.
Hypergraph Node Classification With Graph Neural Networks
Feb 08, 2024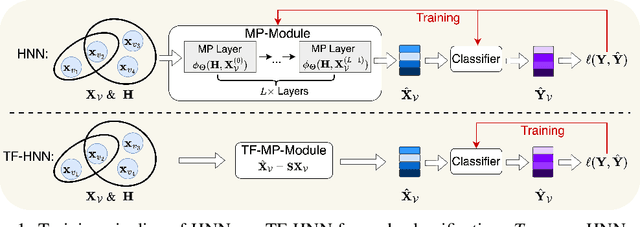

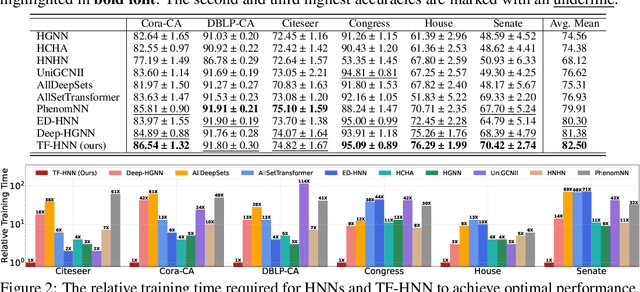
Hypergraphs, with hyperedges connecting more than two nodes, are key for modelling higher-order interactions in real-world data. The success of graph neural networks (GNNs) reveals the capability of neural networks to process data with pairwise interactions. This inspires the usage of neural networks for data with higher-order interactions, thereby leading to the development of hypergraph neural networks (HyperGNNs). GNNs and HyperGNNs are typically considered distinct since they are designed for data on different geometric topologies. However, in this paper, we theoretically demonstrate that, in the context of node classification, most HyperGNNs can be approximated using a GNN with a weighted clique expansion of the hypergraph. This leads to WCE-GNN, a simple and efficient framework comprising a GNN and a weighted clique expansion (WCE), for hypergraph node classification. Experiments on nine real-world hypergraph node classification benchmarks showcase that WCE-GNN demonstrates not only higher classification accuracy compared to state-of-the-art HyperGNNs, but also superior memory and runtime efficiency.
Hypergraph Transformer for Semi-Supervised Classification
Dec 18, 2023


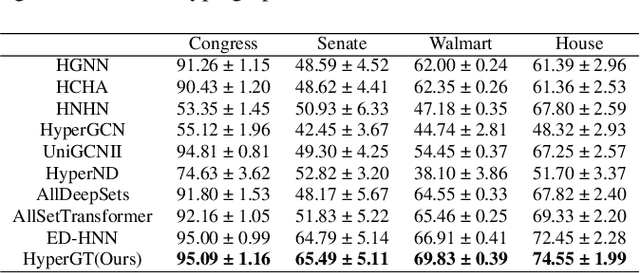
Hypergraphs play a pivotal role in the modelling of data featuring higher-order relations involving more than two entities. Hypergraph neural networks emerge as a powerful tool for processing hypergraph-structured data, delivering remarkable performance across various tasks, e.g., hypergraph node classification. However, these models struggle to capture global structural information due to their reliance on local message passing. To address this challenge, we propose a novel hypergraph learning framework, HyperGraph Transformer (HyperGT). HyperGT uses a Transformer-based neural network architecture to effectively consider global correlations among all nodes and hyperedges. To incorporate local structural information, HyperGT has two distinct designs: i) a positional encoding based on the hypergraph incidence matrix, offering valuable insights into node-node and hyperedge-hyperedge interactions; and ii) a hypergraph structure regularization in the loss function, capturing connectivities between nodes and hyperedges. Through these designs, HyperGT achieves comprehensive hypergraph representation learning by effectively incorporating global interactions while preserving local connectivity patterns. Extensive experiments conducted on real-world hypergraph node classification tasks showcase that HyperGT consistently outperforms existing methods, establishing new state-of-the-art benchmarks. Ablation studies affirm the effectiveness of the individual designs of our model.