 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Video Generation in Enhancing Data-Limited Action Understanding
May 26, 2025



Video action understanding tasks in real-world scenarios always suffer data limitations. In this paper, we address the data-limited action understanding problem by bridging data scarcity. We propose a novel method that employs a text-to-video diffusion transformer to generate annotated data for model training. This paradigm enables the generation of realistic annotated data on an infinite scale without human intervention. We proposed the information enhancement strategy and the uncertainty-based label smoothing tailored to generate sample training. Through quantitative and qualitative analysis, we observed that real samples generally contain a richer level of information than generated samples. Based on this observation, the information enhancement strategy is proposed to enhance the informative content of the generated samples from two aspects: the environments and the characters. Furthermore, we observed that some low-quality generated samples might negatively affect model training. To address this, we devised the uncertainty-based label smoothing strategy to increase the smoothing of these samples, thus reducing their impact. We demonstrate the effectiveness of the proposed method on four datasets across five tasks and achieve state-of-the-art performance for zero-shot action recognition.
ViMo: A Generative Visual GUI World Model for App Agent
Apr 15, 2025App agents, which autonomously operate mobile Apps through Graphical User Interfaces (GUIs), have gained significant interest in real-world applications. Yet, they often struggle with long-horizon planning, failing to find the optimal actions for complex tasks with longer steps. To address this, world models are used to predict the next GUI observation based on user actions, enabling more effective agent planning. However, existing world models primarily focus on generating only textual descriptions, lacking essential visual details. To fill this gap, we propose ViMo, the first visual world model designed to generate future App observations as images. For the challenge of generating text in image patches, where even minor pixel errors can distort readability, we decompose GUI generation into graphic and text content generation. We propose a novel data representation, the Symbolic Text Representation~(STR) to overlay text content with symbolic placeholders while preserving graphics. With this design, ViMo employs a STR Predictor to predict future GUIs' graphics and a GUI-text Predictor for generating the corresponding text. Moreover, we deploy ViMo to enhance agent-focused tasks by predicting the outcome of different action options. Experiments show ViMo's ability to generate visually plausible and functionally effective GUIs that enable App agents to make more informed decisions.
Generative Video Diffusion for Unseen Cross-Domain Video Moment Retrieval
Jan 29, 2024Video Moment Retrieval (VMR) requires precise modelling of fine-grained moment-text associations to capture intricate visual-language relationships. Due to the lack of a diverse and generalisable VMR dataset to facilitate learning scalable moment-text associations, existing methods resort to joint training on both source and target domain videos for cross-domain applications. Meanwhile, recent developments in vision-language multimodal models pre-trained on large-scale image-text and/or video-text pairs are only based on coarse associations (weakly labelled). They are inadequate to provide fine-grained moment-text correlations required for cross-domain VMR. In this work, we solve the problem of unseen cross-domain VMR, where certain visual and textual concepts do not overlap across domains, by only utilising target domain sentences (text prompts) without accessing their videos. To that end, we explore generative video diffusion for fine-grained editing of source videos controlled by the target sentences, enabling us to simulate target domain videos. We address two problems in video editing for optimising unseen domain VMR: (1) generation of high-quality simulation videos of different moments with subtle distinctions, (2) selection of simulation videos that complement existing source training videos without introducing harmful noise or unnecessary repetitions. On the first problem, we formulate a two-stage video diffusion generation controlled simultaneously by (1) the original video structure of a source video, (2) subject specifics, and (3) a target sentence prompt. This ensures fine-grained variations between video moments. On the second problem, we introduce a hybrid selection mechanism that combines two quantitative metrics for noise filtering and one qualitative metric for leveraging VMR prediction on simulation video selection.
Zero-Shot Video Moment Retrieval from Frozen Vision-Language Models
Sep 01, 2023Accurate video moment retrieval (VMR) requires universal visual-textual correlations that can handle unknown vocabulary and unseen scenes. However, the learned correlations are likely either biased when derived from a limited amount of moment-text data which is hard to scale up because of the prohibitive annotation cost (fully-supervised), or unreliable when only the video-text pairwise relationships are available without fine-grained temporal annotations (weakly-supervised). Recently, the vision-language models (VLM) demonstrate a new transfer learning paradigm to benefit different vision tasks through the universal visual-textual correlations derived from large-scale vision-language pairwise web data, which has also shown benefits to VMR by fine-tuning in the target domains. In this work, we propose a zero-shot method for adapting generalisable visual-textual priors from arbitrary VLM to facilitate moment-text alignment, without the need for accessing the VMR data. To this end, we devise a conditional feature refinement module to generate boundary-aware visual features conditioned on text queries to enable better moment boundary understanding. Additionally, we design a bottom-up proposal generation strategy that mitigates the impact of domain discrepancies and breaks down complex-query retrieval tasks into individual action retrievals, thereby maximizing the benefits of VLM. Extensive experiments conducted on three VMR benchmark datasets demonstrate the notable performance advantages of our zero-shot algorithm, especially in the novel-word and novel-location out-of-distribution setups.
Towards Generalisable Video Moment Retrieval: Visual-Dynamic Injection to Image-Text Pre-Training
Feb 28, 2023The correlation between the vision and text is essential for video moment retrieval (VMR), however, existing methods heavily rely on separate pre-training feature extractors for visual and textual understanding. Without sufficient temporal boundary annotations, it is non-trivial to learn universal video-text alignments. In this work, we explore multi-modal correlations derived from large-scale image-text data to facilitate generalisable VMR. To address the limitations of image-text pre-training models on capturing the video changes, we propose a generic method, referred to as Visual-Dynamic Injection (VDI), to empower the model's understanding of video moments. Whilst existing VMR methods are focusing on building temporal-aware video features, being aware of the text descriptions about the temporal changes is also critical but originally overlooked in pre-training by matching static images with sentences. Therefore, we extract visual context and spatial dynamic information from video frames and explicitly enforce their alignments with the phrases describing video changes (e.g. verb). By doing so, the potentially relevant visual and motion patterns in videos are encoded in the corresponding text embeddings (injected) so to enable more accurate video-text alignments. We conduct extensive experiments on two VMR benchmark datasets (Charades-STA and ActivityNet-Captions) and achieve state-of-the-art performances. Especially, VDI yields notable advantages when being tested on the out-of-distribution splits where the testing samples involve novel scenes and vocabulary.
Video 3D Sampling for Self-supervised Representation Learning
Jul 08, 2021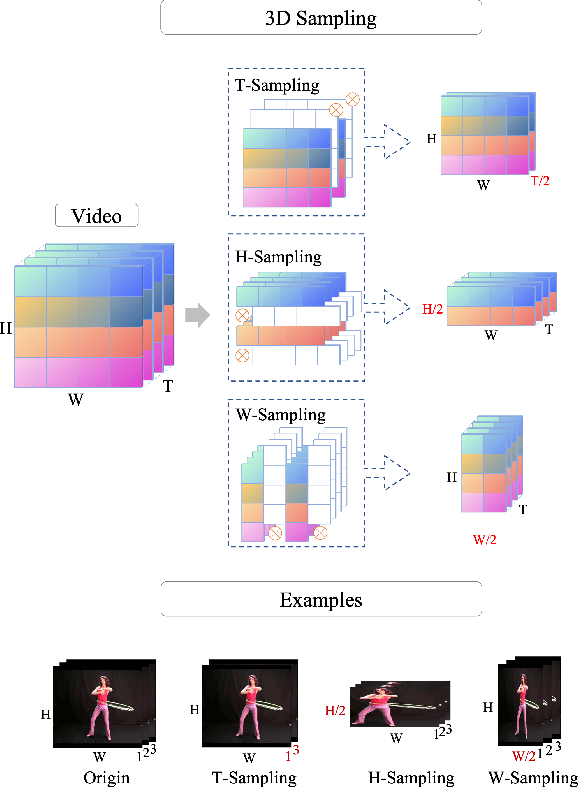
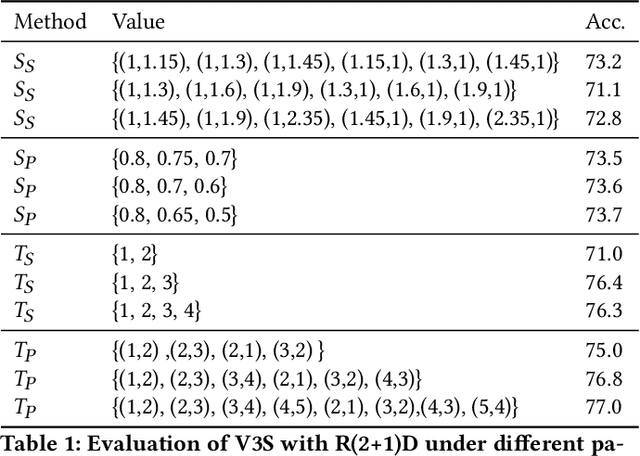
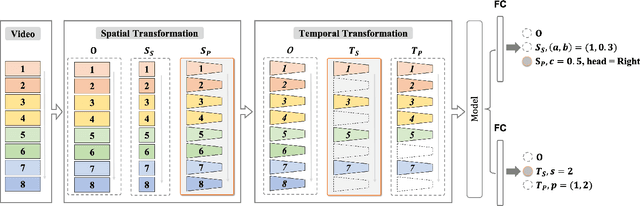
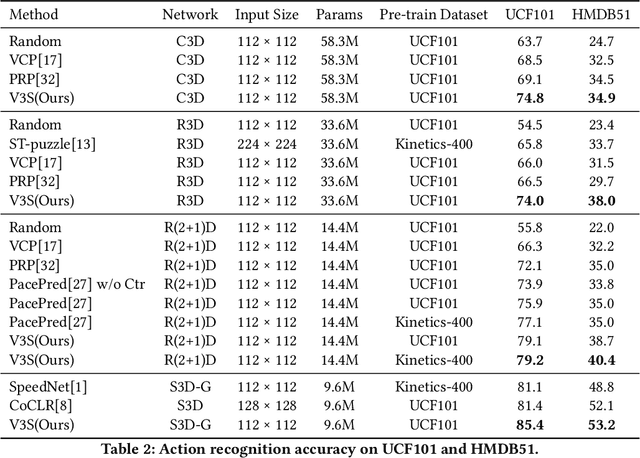
Most of the existing video self-supervised methods mainly leverage temporal signals of videos, ignoring that the semantics of moving objects and environmental information are all critical for video-related tasks. In this paper, we propose a novel self-supervised method for video representation learning, referred to as Video 3D Sampling (V3S). In order to sufficiently utilize the information (spatial and temporal) provided in videos, we pre-process a video from three dimensions (width, height, time). As a result, we can leverage the spatial information (the size of objects), temporal information (the direction and magnitude of motions) as our learning target. In our implementation, we combine the sampling of the three dimensions and propose the scale and projection transformations in space and time respectively. The experimental results show that, when applied to action recognition, video retrieval and action similarity labeling, our approach improves the state-of-the-arts with significant margins.
Exploring Relations in Untrimmed Videos for Self-Supervised Learning
Aug 06, 2020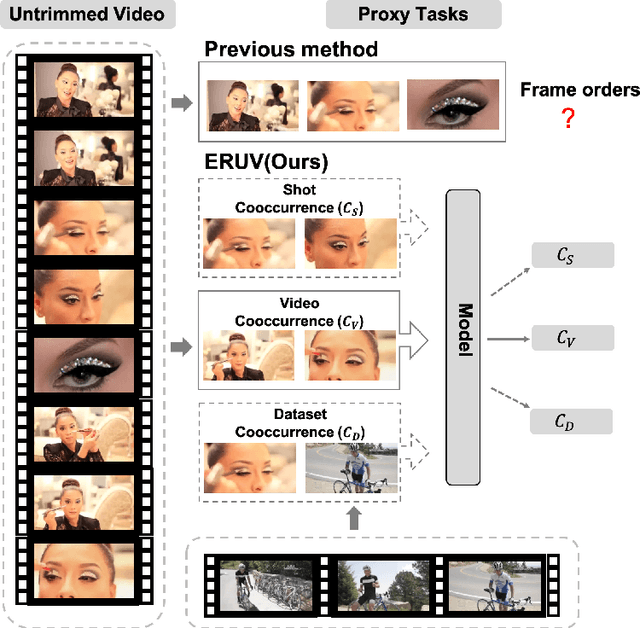
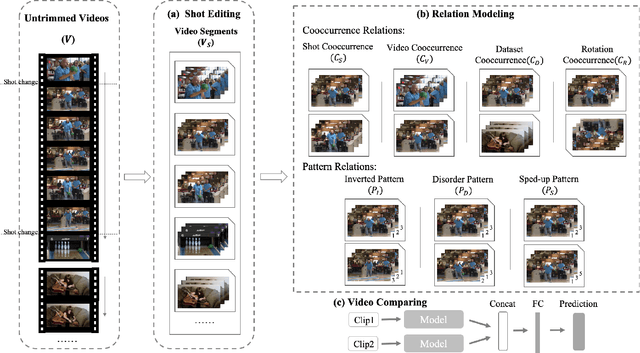

Existing video self-supervised learning methods mainly rely on trimmed videos for model training. However, trimmed datasets are manually annotated from untrimmed videos. In this sense, these methods are not really self-supervised. In this paper, we propose a novel self-supervised method, referred to as Exploring Relations in Untrimmed Videos (ERUV), which can be straightforwardly applied to untrimmed videos (real unlabeled) to learn spatio-temporal features. ERUV first generates single-shot videos by shot change detection. Then a designed sampling strategy is used to model relations for video clips. The strategy is saved as our self-supervision signals. Finally, the network learns representations by predicting the category of relations between the video clips. ERUV is able to compare the differences and similarities of videos, which is also an essential procedure for action and video related tasks. We validate our learned models with action recognition and video retrieval tasks with three kinds of 3D CNNs. Experimental results show that ERUV is able to learn richer representations and it outperforms state-of-the-art self-supervised methods with significant margins.
Video Playback Rate Perception for Self-supervisedSpatio-Temporal Representation Learning
Jun 20, 2020

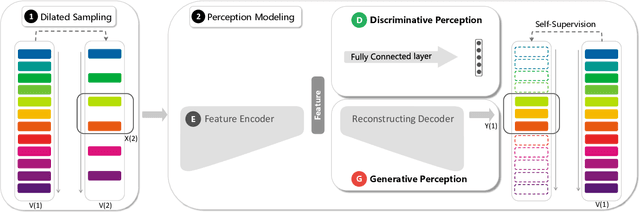

In self-supervised spatio-temporal representation learning, the temporal resolution and long-short term characteristics are not yet fully explored, which limits representation capabilities of learned models. In this paper, we propose a novel self-supervised method, referred to as video Playback Rate Perception (PRP), to learn spatio-temporal representation in a simple-yet-effective way. PRP roots in a dilated sampling strategy, which produces self-supervision signals about video playback rates for representation model learning. PRP is implemented with a feature encoder, a classification module, and a reconstructing decoder, to achieve spatio-temporal semantic retention in a collaborative discrimination-generation manner. The discriminative perception model follows a feature encoder to prefer perceiving low temporal resolution and long-term representation by classifying fast-forward rates. The generative perception model acts as a feature decoder to focus on comprehending high temporal resolution and short-term representation by introducing a motion-attention mechanism. PRP is applied on typical video target tasks including action recognition and video retrieval. Experiments show that PRP outperforms state-of-the-art self-supervised models with significant margins. Code is available at github.com/yuanyao366/PRP
Video Cloze Procedure for Self-Supervised Spatio-Temporal Learning
Jan 02, 2020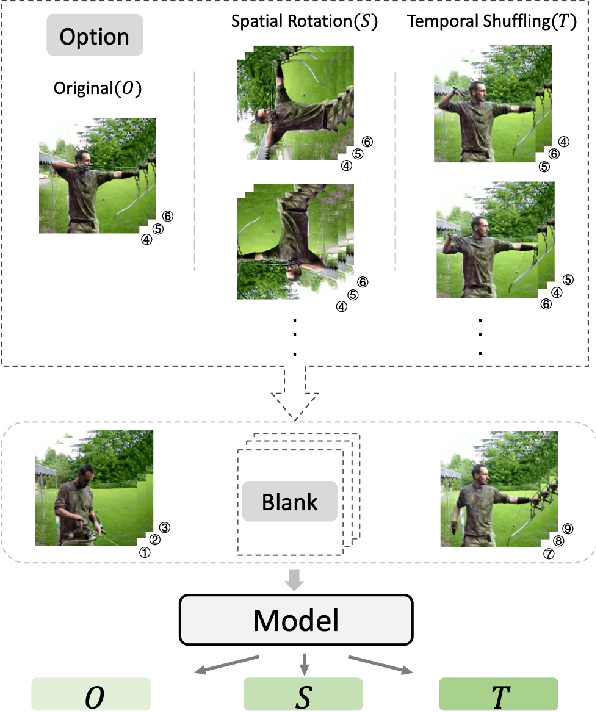



We propose a novel self-supervised method, referred to as Video Cloze Procedure (VCP), to learn rich spatial-temporal representations. VCP first generates "blanks" by withholding video clips and then creates "options" by applying spatio-temporal operations on the withheld clips. Finally, it fills the blanks with "options" and learns representations by predicting the categories of operations applied on the clips. VCP can act as either a proxy task or a target task in self-supervised learning. As a proxy task, it converts rich self-supervised representations into video clip operations (options), which enhances the flexibility and reduces the complexity of representation learning. As a target task, it can assess learned representation models in a uniform and interpretable manner. With VCP, we train spatial-temporal representation models (3D-CNNs) and apply such models on action recognition and video retrieval tasks. Experiments on commonly used benchmarks show that the trained models outperform the state-of-the-art self-supervised models with significant margins.