 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Cloze Procedure for Self-Supervised Spatio-Temporal Learning
Paper and Code
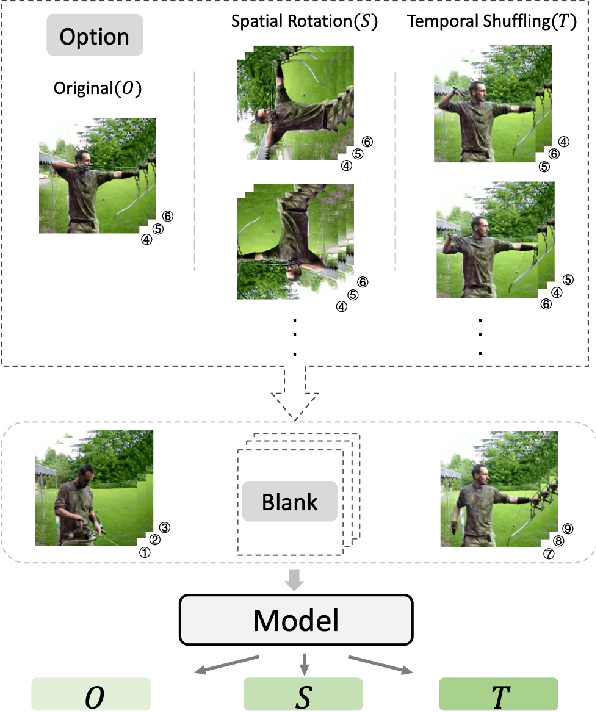



We propose a novel self-supervised method, referred to as Video Cloze Procedure (VCP), to learn rich spatial-temporal representations. VCP first generates "blanks" by withholding video clips and then creates "options" by applying spatio-temporal operations on the withheld clips. Finally, it fills the blanks with "options" and learns representations by predicting the categories of operations applied on the clips. VCP can act as either a proxy task or a target task in self-supervised learning. As a proxy task, it converts rich self-supervised representations into video clip operations (options), which enhances the flexibility and reduces the complexity of representation learning. As a target task, it can assess learned representation models in a uniform and interpretable manner. With VCP, we train spatial-temporal representation models (3D-CNNs) and apply such models on action recognition and video retrieval tasks. Experiments on commonly used benchmarks show that the trained models outperform the state-of-the-art self-supervised models with significant margins.