 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapture Global Feature Statistics for One-Shot Federated Learning
Mar 10, 2025Traditional Federated Learning (FL) necessitates numerous rounds of communication between the server and clients, posing significant challenges including high communication costs, connection drop risks and susceptibility to privacy attacks. One-shot FL has become a compelling learning paradigm to overcome above drawbacks by enabling the training of a global server model via a single communication round. However, existing one-shot FL methods suffer from expensive computation cost on the server or clients and cannot deal with non-IID (Independent and Identically Distributed) data stably and effectively. To address these challenges, this paper proposes FedCGS, a novel Federated learning algorithm that Capture Global feature Statistics leveraging pre-trained models. With global feature statistics, we achieve training-free and heterogeneity-resistant one-shot FL. Furthermore, we extend its application to personalization scenario, where clients only need execute one extra communication round with server to download global statistics. Extensive experimental results demonstrate the effectiveness of our methods across diverse data heterogeneity settings. Code is available at https://github.com/Yuqin-G/FedCGS.
Imagine by Reasoning: A Reasoning-Based Implicit Semantic Data Augmentation for Long-Tailed Classification
Dec 15, 2021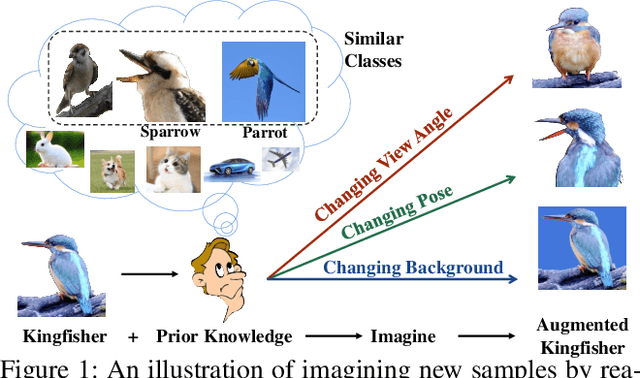
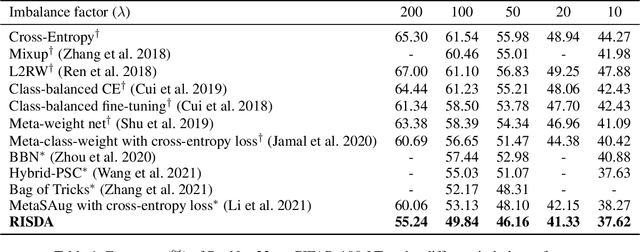
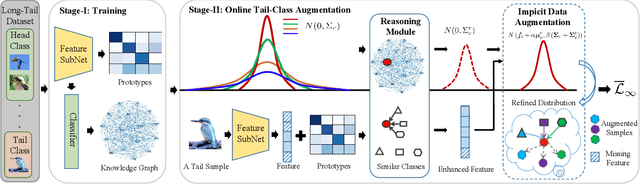
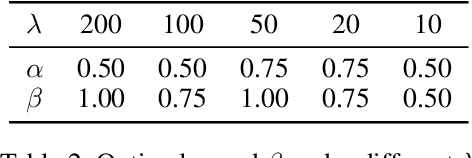
Real-world data often follows a long-tailed distribution, which makes the performance of existing classification algorithms degrade heavily. A key issue is that samples in tail categories fail to depict their intra-class diversity. Humans can imagine a sample in new poses, scenes, and view angles with their prior knowledge even if it is the first time to see this category. Inspired by this, we propose a novel reasoning-based implicit semantic data augmentation method to borrow transformation directions from other classes. Since the covariance matrix of each category represents the feature transformation directions, we can sample new directions from similar categories to generate definitely different instances. Specifically, the long-tailed distributed data is first adopted to train a backbone and a classifier. Then, a covariance matrix for each category is estimated, and a knowledge graph is constructed to store the relations of any two categories. Finally, tail samples are adaptively enhanced via propagating information from all the similar categories in the knowledge graph. Experimental results on CIFAR-100-LT, ImageNet-LT, and iNaturalist 2018 have demonstrated the effectiveness of our proposed method compared with the state-of-the-art methods.
MMF: Multi-Task Multi-Structure Fusion for Hierarchical Image Classification
Jul 02, 2021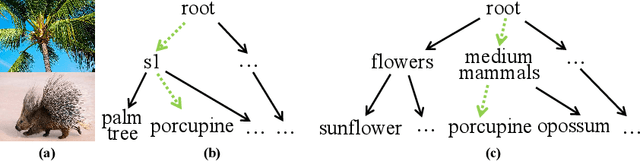
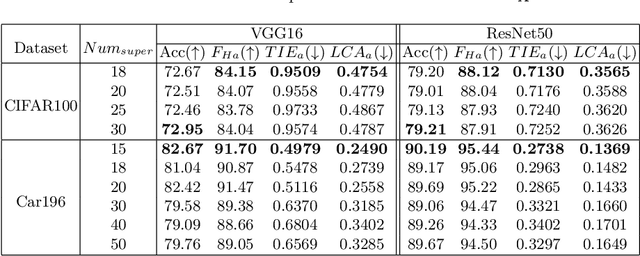
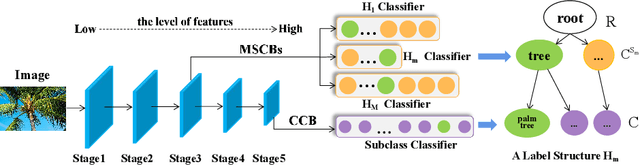
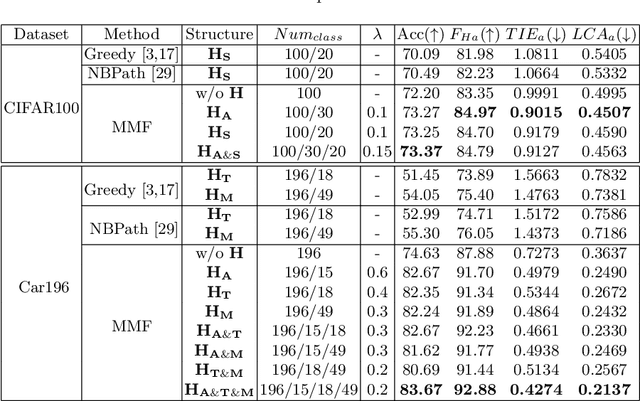
Hierarchical classification is significant for complex tasks by providing multi-granular predictions and encouraging better mistakes. As the label structure decides its performance, many existing approaches attempt to construct an excellent label structure for promoting the classification results. In this paper, we consider that different label structures provide a variety of prior knowledge for category recognition, thus fusing them is helpful to achieve better hierarchical classification results. Furthermore, we propose a multi-task multi-structure fusion model to integrate different label structures. It contains two kinds of branches: one is the traditional classification branch to classify the common subclasses, the other is responsible for identifying the heterogeneous superclasses defined by different label structures. Besides the effect of multiple label structures, we also explore the architecture of the deep model for better hierachical classification and adjust the hierarchical evaluation metrics for multiple label structures. Experimental results on CIFAR100 and Car196 show that our method obtains significantly better results than using a flat classifier or a hierarchical classifier with any single label structure.
Rescuing Deep Hashing from Dead Bits Problem
Feb 01, 2021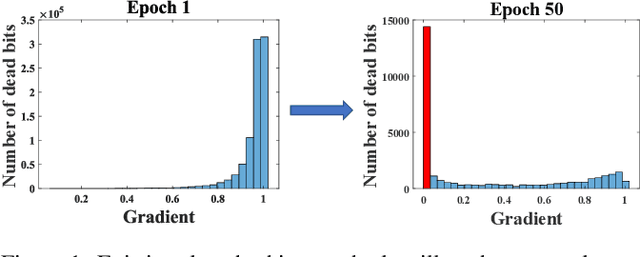
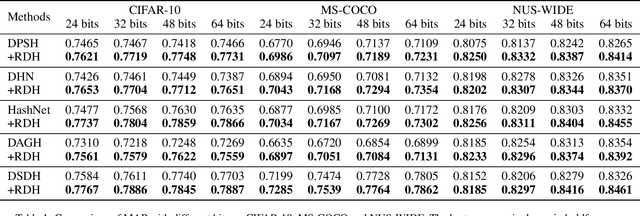
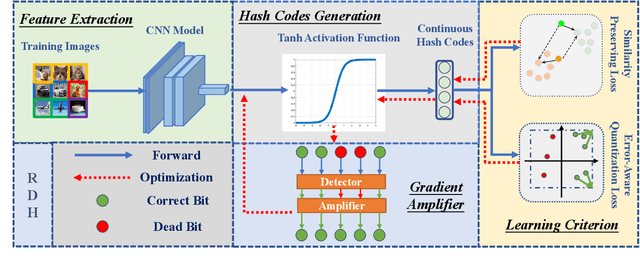
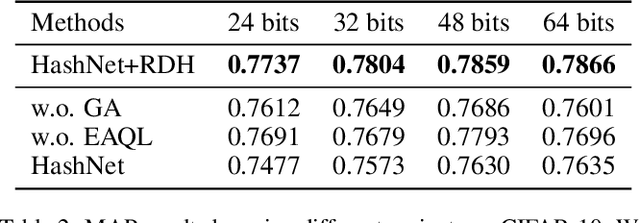
Deep hashing methods have shown great retrieval accuracy and efficiency in large-scale image retrieval. How to optimize discrete hash bits is always the focus in deep hashing methods. A common strategy in these methods is to adopt an activation function, e.g. $\operatorname{sigmoid}(\cdot)$ or $\operatorname{tanh}(\cdot)$, and minimize a quantization loss to approximate discrete values. However, this paradigm may make more and more hash bits stuck into the wrong saturated area of the activation functions and never escaped. We call this problem "Dead Bits Problem~(DBP)". Besides, the existing quantization loss will aggravate DBP as well. In this paper, we propose a simple but effective gradient amplifier which acts before activation functions to alleviate DBP. Moreover, we devise an error-aware quantization loss to further alleviate DBP. It avoids the negative effect of quantization loss based on the similarity between two images. The proposed gradient amplifier and error-aware quantization loss are compatible with a variety of deep hashing methods. Experimental results on three datasets demonstrate the efficiency of the proposed gradient amplifier and the error-aware quantization loss.
Exploring Relations in Untrimmed Videos for Self-Supervised Learning
Aug 06, 2020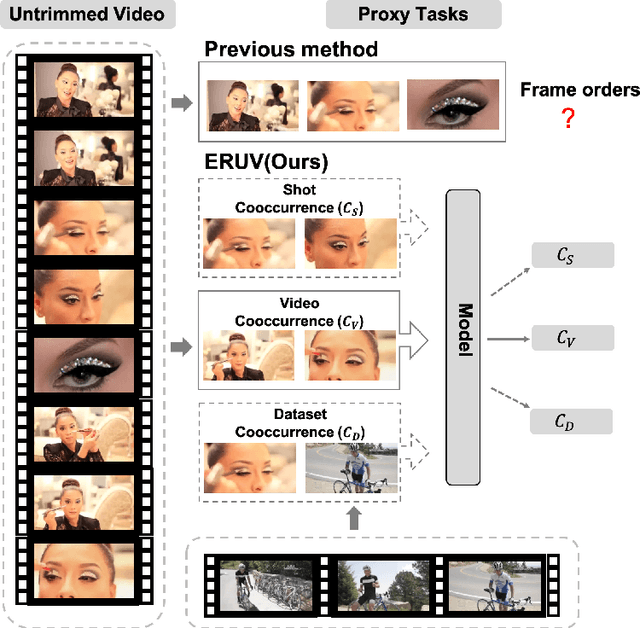
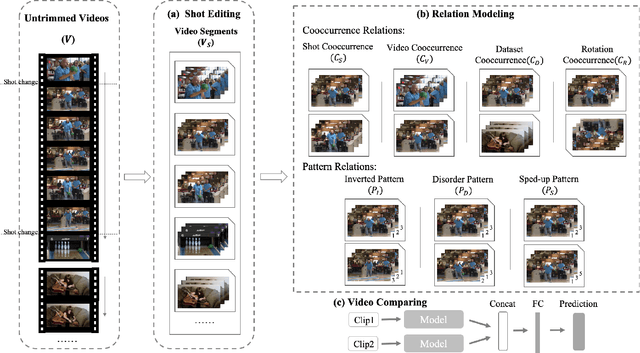
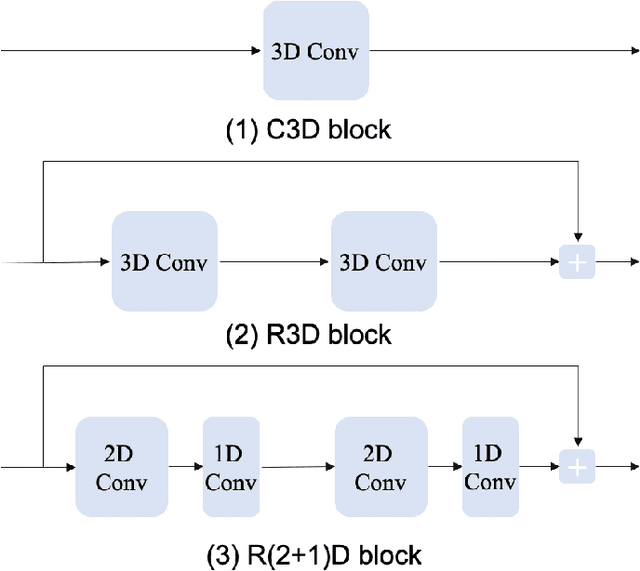

Existing video self-supervised learning methods mainly rely on trimmed videos for model training. However, trimmed datasets are manually annotated from untrimmed videos. In this sense, these methods are not really self-supervised. In this paper, we propose a novel self-supervised method, referred to as Exploring Relations in Untrimmed Videos (ERUV), which can be straightforwardly applied to untrimmed videos (real unlabeled) to learn spatio-temporal features. ERUV first generates single-shot videos by shot change detection. Then a designed sampling strategy is used to model relations for video clips. The strategy is saved as our self-supervision signals. Finally, the network learns representations by predicting the category of relations between the video clips. ERUV is able to compare the differences and similarities of videos, which is also an essential procedure for action and video related tasks. We validate our learned models with action recognition and video retrieval tasks with three kinds of 3D CNNs. Experimental results show that ERUV is able to learn richer representations and it outperforms state-of-the-art self-supervised methods with significant margins.
Expert Training: Task Hardness Aware Meta-Learning for Few-Shot Classification
Jul 13, 2020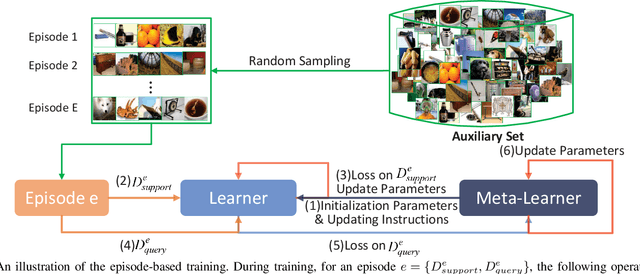



Deep neural networks are highly effective when a large number of labeled samples are available but fail with few-shot classification tasks. Recently, meta-learning methods have received much attention, which train a meta-learner on massive additional tasks to gain the knowledge to instruct the few-shot classification. Usually, the training tasks are randomly sampled and performed indiscriminately, often making the meta-learner stuck into a bad local optimum. Some works in the optimization of deep neural networks have shown that a better arrangement of training data can make the classifier converge faster and perform better. Inspired by this idea, we propose an easy-to-hard expert meta-training strategy to arrange the training tasks properly, where easy tasks are preferred in the first phase, then, hard tasks are emphasized in the second phase. A task hardness aware module is designed and integrated into the training procedure to estimate the hardness of a task based on the distinguishability of its categories. In addition, we explore multiple hardness measurements including the semantic relation, the pairwise Euclidean distance, the Hausdorff distance, and the Hilbert-Schmidt independence criterion. Experimental results on the miniImageNet and tieredImageNetSketch datasets show that the meta-learners can obtain better results with our expert training strategy.
SEED: Semantics Enhanced Encoder-Decoder Framework for Scene Text Recognition
May 22, 2020



Scene text recognition is a hot research topic in computer vision. Recently, many recognition methods based on the encoder-decoder framework have been proposed, and they can handle scene texts of perspective distortion and curve shape. Nevertheless, they still face lots of challenges like image blur, uneven illumination, and incomplete characters. We argue that most encoder-decoder methods are based on local visual features without explicit global semantic information. In this work, we propose a semantics enhanced encoder-decoder framework to robustly recognize low-quality scene texts. The semantic information is used both in the encoder module for supervision and in the decoder module for initializing. In particular, the state-of-the art ASTER method is integrated into the proposed framework as an exemplar. Extensive experiments demonstrate that the proposed framework is more robust for low-quality text images, and achieves state-of-the-art results on several benchmark datasets.