 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpert Training: Task Hardness Aware Meta-Learning for Few-Shot Classification
Paper and Code
Jul 13, 2020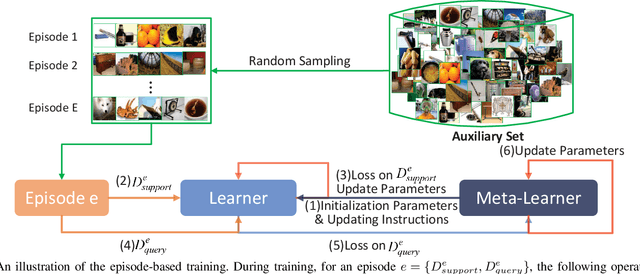



Deep neural networks are highly effective when a large number of labeled samples are available but fail with few-shot classification tasks. Recently, meta-learning methods have received much attention, which train a meta-learner on massive additional tasks to gain the knowledge to instruct the few-shot classification. Usually, the training tasks are randomly sampled and performed indiscriminately, often making the meta-learner stuck into a bad local optimum. Some works in the optimization of deep neural networks have shown that a better arrangement of training data can make the classifier converge faster and perform better. Inspired by this idea, we propose an easy-to-hard expert meta-training strategy to arrange the training tasks properly, where easy tasks are preferred in the first phase, then, hard tasks are emphasized in the second phase. A task hardness aware module is designed and integrated into the training procedure to estimate the hardness of a task based on the distinguishability of its categories. In addition, we explore multiple hardness measurements including the semantic relation, the pairwise Euclidean distance, the Hausdorff distance, and the Hilbert-Schmidt independence criterion. Experimental results on the miniImageNet and tieredImageNetSketch datasets show that the meta-learners can obtain better results with our expert training strategy.