 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYouZhi: Towards High-Concurrency Financial LLMs via Adaptive GQA-to-MLA Transition
Jun 04, 2026Large language models (LLMs) drive significant financial innovations, yet their high-concurrency deployment is severely bottlenecked by KV cache memory overhead, which inflates infrastructure costs and throttles scalability. To address this, we propose YouZhi-LLM, a highly efficient financial LLM empowered by a comprehensive structural transition and training pipeline natively built on the Huawei Ascend ecosystem. At its algorithmic core, YouZhi-LLM features a layer-adaptive GQA-to-MLA transition framework that dynamically assigns per-layer FreqFold sizes, maximizing KV-cache compression while minimizing perplexity degradation. To recover representation capacity and inject domain expertise, the Ascend-based training pipeline seamlessly integrates generalized knowledge distillation with financial-specific supervised fine-tuning. Evaluations demonstrate the superiority of this systematic approach, with the adaptive transition reducing perplexity degradation by up to 35% over uniform baselines. Crucially, when evaluated on Ascend NPUs via vLLM-Ascend, the massive KV-cache reduction translates directly into deployment efficiency. Compared to their respective base models, YouZhi-7B yields a 12.3% improvement in average financial benchmark score alongside a 2.69$\times$ increase in maximum concurrency; similarly, YouZhi-14B achieves a 7.0% accuracy gain and a 2.43$\times$ concurrency boost, establishing a new paradigm for cost-effective, high-throughput financial inference.
Towards Self-Evolving Agentic Literature Retrieval
May 14, 2026As large language models reshape scientific research, literature retrieval faces a twofold challenge: ensuring source authenticity while maintaining a deep comprehension of academic search intents. While reliable, traditional keyword-centric search fails to capture complex research intents. Frontier LLMs can handle complex research intents, but their high cost and tendency to hallucinate remain key limitations. Here we introduce PaSaMaster, a self-evolving agentic literature retrieval system that produces relevance-scored paper rankings with evidence-grounded recommendations through iterative intent analysis, retrieval, and ranking. It is built on three key designs. First, it transforms literature retrieval from a one shot query--document matching problem into a search process that evolves over time, using ranked evidence to reveal gaps, refine intents, and guide follow-up searches. Second, it prevents hallucinated sources by treating retrieval as intent--paper relevance ranking rather than generation. Finally, PaSaMaster improves cost efficiency by separating planning from retrieval: a frontier LLM is used only for intent understanding, while large scale retrieval and relevance scoring are delegated to customized corpora and lightweight models. Evaluated on the PaSaMaster Benchmark across 38 scientific disciplines, our system exposes the severe inaccuracy and incompleteness of traditional keyword retrieval (improving F1-score by 15.6X) and the unreliability of generative LLMs (which exhibit hallucination rates up to 37.79%). Remarkably, PaSaMaster outperforms GPT-5.2 by 30.0% at a mere 1% of the computational cost while ensuring zero source hallucination: https://github.com/sjtu-sai-agents/PaSaMaster
PhysMaster: Building an Autonomous AI Physicist for Theoretical and Computational Physics Research
Dec 22, 2025Advances in LLMs have produced agents with knowledge and operational capabilities comparable to human scientists, suggesting potential to assist, accelerate, and automate research. However, existing studies mainly evaluate such systems on well-defined benchmarks or general tasks like literature retrieval, limiting their end-to-end problem-solving ability in open scientific scenarios. This is particularly true in physics, which is abstract, mathematically intensive, and requires integrating analytical reasoning with code-based computation. To address this, we propose PhysMaster, an LLM-based agent functioning as an autonomous theoretical and computational physicist. PhysMaster couples absract reasoning with numerical computation and leverages LANDAU, the Layered Academic Data Universe, which preserves retrieved literature, curated prior knowledge, and validated methodological traces, enhancing decision reliability and stability. It also employs an adaptive exploration strategy balancing efficiency and open-ended exploration, enabling robust performance in ultra-long-horizon tasks. We evaluate PhysMaster on problems from high-energy theory, condensed matter theory to astrophysics, including: (i) acceleration, compressing labor-intensive research from months to hours; (ii) automation, autonomously executing hypothesis-driven loops ; and (iii) autonomous discovery, independently exploring open problems.
Sharing State Between Prompts and Programs
Dec 16, 2025The rise of large language models (LLMs) has introduced a new type of programming: natural language programming. By writing prompts that direct LLMs to perform natural language processing, code generation, reasoning, etc., users are writing code in natural language -- natural language code -- for the LLM to execute. An emerging area of research enables interoperability between natural language code and formal languages such as Python. We present a novel programming abstraction, shared program state, that removes the manual work required to enable interoperability between natural language code and program state. With shared program state, programmers can write natural code that directly writes program variables, computes with program objects, and implements control flow in the program. We present a schema for specifying natural function interfaces that extend programming systems to support natural code and leverage this schema to specify shared program state as a natural function interface. We implement shared program state in the Nightjar programming system. Nightjar enables programmers to write Python programs that contain natural code that shares the Python program state. We show that Nightjar programs achieve comparable or higher task accuracy than manually written implementations (+4-19%), while decreasing the lines of code by 39.6% on average. The tradeoff to using Nightjar is that it may incur runtime overhead (0.4-4.3x runtime of manual implementations).
MASLab: A Unified and Comprehensive Codebase for LLM-based Multi-Agent Systems
May 22, 2025LLM-based multi-agent systems (MAS) have demonstrated significant potential in enhancing single LLMs to address complex and diverse tasks in practical applications. Despite considerable advancements, the field lacks a unified codebase that consolidates existing methods, resulting in redundant re-implementation efforts, unfair comparisons, and high entry barriers for researchers. To address these challenges, we introduce MASLab, a unified, comprehensive, and research-friendly codebase for LLM-based MAS. (1) MASLab integrates over 20 established methods across multiple domains, each rigorously validated by comparing step-by-step outputs with its official implementation. (2) MASLab provides a unified environment with various benchmarks for fair comparisons among methods, ensuring consistent inputs and standardized evaluation protocols. (3) MASLab implements methods within a shared streamlined structure, lowering the barriers for understanding and extension. Building on MASLab, we conduct extensive experiments covering 10+ benchmarks and 8 models, offering researchers a clear and comprehensive view of the current landscape of MAS methods. MASLab will continue to evolve, tracking the latest developments in the field, and invite contributions from the broader open-source community.
GraphMaster: Automated Graph Synthesis via LLM Agents in Data-Limited Environments
Apr 01, 2025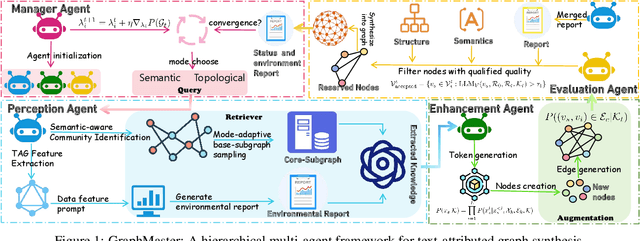



The era of foundation models has revolutionized AI research, yet Graph Foundation Models (GFMs) remain constrained by the scarcity of large-scale graph corpora. Traditional graph data synthesis techniques primarily focus on simplistic structural operations, lacking the capacity to generate semantically rich nodes with meaningful textual attributes: a critical limitation for real-world applications. While large language models (LLMs) demonstrate exceptional text generation capabilities, their direct application to graph synthesis is impeded by context window limitations, hallucination phenomena, and structural consistency challenges. To address these issues, we introduce GraphMaster, the first multi-agent framework specifically designed for graph data synthesis in data-limited environments. GraphMaster orchestrates four specialized LLM agents (Manager, Perception, Enhancement, and Evaluation) that collaboratively optimize the synthesis process through iterative refinement, ensuring both semantic coherence and structural integrity. To rigorously evaluate our approach, we create new data-limited "Sub" variants of six standard graph benchmarks, specifically designed to test synthesis capabilities under realistic constraints. Additionally, we develop a novel interpretability assessment framework that combines human evaluation with a principled Grassmannian manifold-based analysis, providing both qualitative and quantitative measures of semantic coherence. Experimental results demonstrate that GraphMaster significantly outperforms traditional synthesis methods across multiple datasets, establishing a strong foundation for advancing GFMs in data-scarce environments.
Unifying Structure and Activation: A Comprehensive Approach of Parameter and Memory Efficient Transfer Learning
Mar 11, 2025Parameter-efficient transfer learning (PETL) aims to reduce the scales of pre-trained models for multiple downstream tasks. However, as the models keep scaling up, the memory footprint of existing PETL methods is not significantly reduced compared to the reduction of learnable parameters. This limitation hinders the practical deployment of PETL methods on memory-constrained devices. To this end, we proposed a new PETL framework, called Structure to Activation (S2A), to reduce the memory footprint of activation during fine-tuning. Specifically, our framework consists of: 1)Activation modules design(i.e. bias, prompt and side modules) in the parametric model structure, which results in a significant reduction of adjustable parameters and activation memory 2) 4-bit quantisation of activations based on their derivatives for non-parametric structures (e.g., nonlinear functions), which maintains accuracy while significantly reducing memory usage. Our S2A method consequently offers a lightweight solution in terms of both parameter and memory footprint. We evaluate S2A with different backbones and conduct extensive experiments on various datasets to evaluate the effectiveness. The results show that our method not only outperforms existing PETL techniques, achieving a fourfold reduction in GPU memory footprint on average, but also shows competitive performance in accuracy with lower tunable parameters. These also demonstrate that our method is highly suitable for practical transfer learning on hardware-constrained devices.
EDENet: Echo Direction Encoding Network for Place Recognition Based on Ground Penetrating Radar
Feb 28, 2025



Ground penetrating radar (GPR) based localization has gained significant recognition in robotics due to its ability to detect stable subsurface features, offering advantages in environments where traditional sensors like cameras and LiDAR may struggle. However, existing methods are primarily focused on small-scale place recognition (PR), leaving the challenges of PR in large-scale maps unaddressed. These challenges include the inherent sparsity of underground features and the variability in underground dielectric constants, which complicate robust localization. In this work, we investigate the geometric relationship between GPR echo sequences and underground scenes, leveraging the robustness of directional features to inform our network design. We introduce learnable Gabor filters for the precise extraction of directional responses, coupled with a direction-aware attention mechanism for effective geometric encoding. To further enhance performance, we incorporate a shift-invariant unit and a multi-scale aggregation strategy to better accommodate variations in di-electric constants. Experiments conducted on public datasets demonstrate that our proposed EDENet not only surpasses existing solutions in terms of PR performance but also offers advantages in model size and computational efficiency.
Learning to Keep a Promise: Scaling Language Model Decoding Parallelism with Learned Asynchronous Decoding
Feb 17, 2025

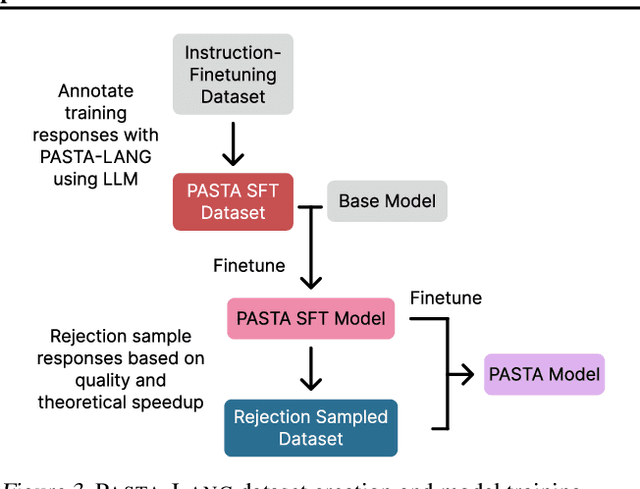
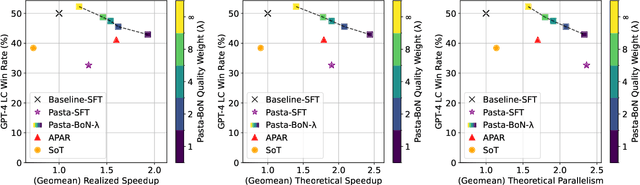
Decoding with autoregressive large language models (LLMs) traditionally occurs sequentially, generating one token after another. An emerging line of work explored parallel decoding by identifying and simultaneously generating semantically independent chunks of LLM responses. However, these techniques rely on hand-crafted heuristics tied to syntactic structures like lists and paragraphs, making them rigid and imprecise. We present PASTA, a learning-based system that teaches LLMs to identify semantic independence and express parallel decoding opportunities in their own responses. At its core are PASTA-LANG and its interpreter: PASTA-LANG is an annotation language that enables LLMs to express semantic independence in their own responses; the language interpreter acts on these annotations to orchestrate parallel decoding on-the-fly at inference time. Through a two-stage finetuning process, we train LLMs to generate PASTA-LANG annotations that optimize both response quality and decoding speed. Evaluation on AlpacaEval, an instruction following benchmark, shows that our approach Pareto-dominates existing methods in terms of decoding speed and response quality; our results demonstrate geometric mean speedups ranging from 1.21x to 1.93x with corresponding quality changes of +2.2% to -7.1%, measured by length-controlled win rates against sequential decoding baseline.
FedMobileAgent: Training Mobile Agents Using Decentralized Self-Sourced Data from Diverse Users
Feb 05, 2025



The advancement of mobile agents has opened new opportunities for automating tasks on mobile devices. Training these agents requires large-scale high-quality data, which is costly using human labor. Given the vast number of mobile phone users worldwide, if automated data collection from them is feasible, the resulting data volume and the subsequently trained mobile agents could reach unprecedented levels. Nevertheless, two major challenges arise: (1) extracting high-level and low-level user instructions without involving human and (2) utilizing distributed data from diverse users while preserving privacy. To tackle these challenges, we propose FedMobileAgent, a collaborative framework that trains mobile agents using self-sourced data from diverse users. Specifically, it includes two techniques. First, we propose Auto-Annotation, which enables the automatic collection of high-quality datasets during users' routine phone usage with minimal cost. Second, we introduce adapted aggregation to improve federated training of mobile agents on non-IID user data, by incorporating both episode- and step-level distributions. In distributed settings, FedMobileAgent achieves performance comparable to centralized human-annotated models at less than 0.02\% of the cost, highlighting its potential for real-world applications.