 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharing State Between Prompts and Programs
Dec 16, 2025The rise of large language models (LLMs) has introduced a new type of programming: natural language programming. By writing prompts that direct LLMs to perform natural language processing, code generation, reasoning, etc., users are writing code in natural language -- natural language code -- for the LLM to execute. An emerging area of research enables interoperability between natural language code and formal languages such as Python. We present a novel programming abstraction, shared program state, that removes the manual work required to enable interoperability between natural language code and program state. With shared program state, programmers can write natural code that directly writes program variables, computes with program objects, and implements control flow in the program. We present a schema for specifying natural function interfaces that extend programming systems to support natural code and leverage this schema to specify shared program state as a natural function interface. We implement shared program state in the Nightjar programming system. Nightjar enables programmers to write Python programs that contain natural code that shares the Python program state. We show that Nightjar programs achieve comparable or higher task accuracy than manually written implementations (+4-19%), while decreasing the lines of code by 39.6% on average. The tradeoff to using Nightjar is that it may incur runtime overhead (0.4-4.3x runtime of manual implementations).
Learning to Keep a Promise: Scaling Language Model Decoding Parallelism with Learned Asynchronous Decoding
Feb 17, 2025

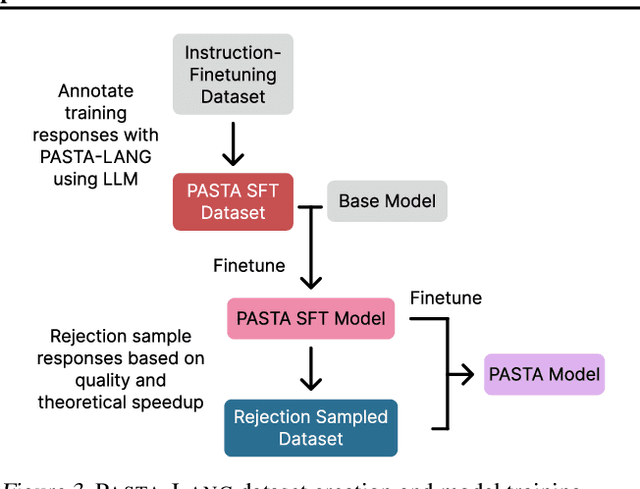
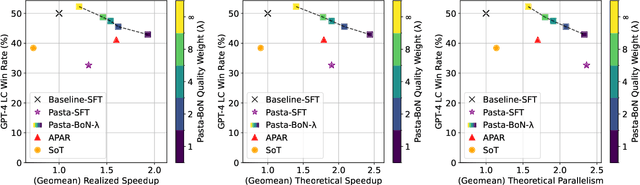
Decoding with autoregressive large language models (LLMs) traditionally occurs sequentially, generating one token after another. An emerging line of work explored parallel decoding by identifying and simultaneously generating semantically independent chunks of LLM responses. However, these techniques rely on hand-crafted heuristics tied to syntactic structures like lists and paragraphs, making them rigid and imprecise. We present PASTA, a learning-based system that teaches LLMs to identify semantic independence and express parallel decoding opportunities in their own responses. At its core are PASTA-LANG and its interpreter: PASTA-LANG is an annotation language that enables LLMs to express semantic independence in their own responses; the language interpreter acts on these annotations to orchestrate parallel decoding on-the-fly at inference time. Through a two-stage finetuning process, we train LLMs to generate PASTA-LANG annotations that optimize both response quality and decoding speed. Evaluation on AlpacaEval, an instruction following benchmark, shows that our approach Pareto-dominates existing methods in terms of decoding speed and response quality; our results demonstrate geometric mean speedups ranging from 1.21x to 1.93x with corresponding quality changes of +2.2% to -7.1%, measured by length-controlled win rates against sequential decoding baseline.
Inference Plans for Hybrid Particle Filtering
Aug 21, 2024



Advanced probabilistic programming languages (PPLs) use hybrid inference systems to combine symbolic exact inference and Monte Carlo methods to improve inference performance. These systems use heuristics to partition random variables within the program into variables that are encoded symbolically and variables that are encoded with sampled values, and the heuristics are not necessarily aligned with the performance evaluation metrics used by the developer. In this work, we present inference plans, a programming interface that enables developers to control the partitioning of random variables during hybrid particle filtering. We further present Siren, a new PPL that enables developers to use annotations to specify inference plans the inference system must implement. To assist developers with statically reasoning about whether an inference plan can be implemented, we present an abstract-interpretation-based static analysis for Siren for determining inference plan satisfiability. We prove the analysis is sound with respect to Siren's semantics. Our evaluation applies inference plans to three different hybrid particle filtering algorithms on a suite of benchmarks and shows that the control provided by inference plans enables speed ups of 1.76x on average and up to 206x to reach target accuracy, compared to the inference plans implemented by default heuristics; the results also show that inference plans improve accuracy by 1.83x on average and up to 595x with less or equal runtime, compared to the default inference plans. We further show that the static analysis is precise in practice, identifying all satisfiable inference plans in 27 out of the 33 benchmark-algorithm combinations.