 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning with Latent Thoughts: On the Power of Looped Transformers
Feb 24, 2025Large language models have shown remarkable reasoning abilities and scaling laws suggest that large parameter count, especially along the depth axis, is the primary driver. In this work, we make a stronger claim -- many reasoning problems require a large depth but not necessarily many parameters. This unlocks a novel application of looped models for reasoning. Firstly, we show that for many synthetic reasoning problems like addition, $p$-hop induction, and math problems, a $k$-layer transformer looped $L$ times nearly matches the performance of a $kL$-layer non-looped model, and is significantly better than a $k$-layer model. This is further corroborated by theoretical results showing that many such reasoning problems can be solved via iterative algorithms, and thus, can be solved effectively using looped models with nearly optimal depth. Perhaps surprisingly, these benefits also translate to practical settings of language modeling -- on many downstream reasoning tasks, a language model with $k$-layers looped $L$ times can be competitive to, if not better than, a $kL$-layer language model. In fact, our empirical analysis reveals an intriguing phenomenon: looped and non-looped models exhibit scaling behavior that depends on their effective depth, akin to the inference-time scaling of chain-of-thought (CoT) reasoning. We further elucidate the connection to CoT reasoning by proving that looped models implicitly generate latent thoughts and can simulate $T$ steps of CoT with $T$ loops. Inspired by these findings, we also present an interesting dichotomy between reasoning and memorization, and design a looping-based regularization that is effective on both fronts.
Learning to Keep a Promise: Scaling Language Model Decoding Parallelism with Learned Asynchronous Decoding
Feb 17, 2025

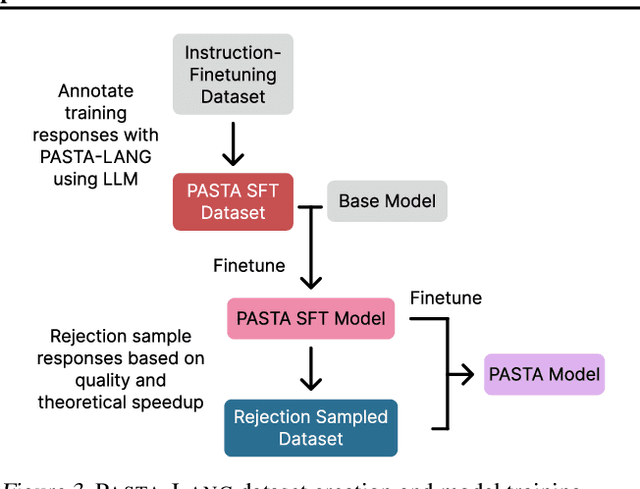
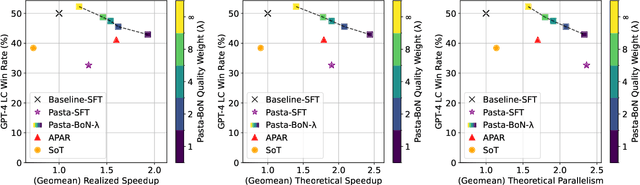
Decoding with autoregressive large language models (LLMs) traditionally occurs sequentially, generating one token after another. An emerging line of work explored parallel decoding by identifying and simultaneously generating semantically independent chunks of LLM responses. However, these techniques rely on hand-crafted heuristics tied to syntactic structures like lists and paragraphs, making them rigid and imprecise. We present PASTA, a learning-based system that teaches LLMs to identify semantic independence and express parallel decoding opportunities in their own responses. At its core are PASTA-LANG and its interpreter: PASTA-LANG is an annotation language that enables LLMs to express semantic independence in their own responses; the language interpreter acts on these annotations to orchestrate parallel decoding on-the-fly at inference time. Through a two-stage finetuning process, we train LLMs to generate PASTA-LANG annotations that optimize both response quality and decoding speed. Evaluation on AlpacaEval, an instruction following benchmark, shows that our approach Pareto-dominates existing methods in terms of decoding speed and response quality; our results demonstrate geometric mean speedups ranging from 1.21x to 1.93x with corresponding quality changes of +2.2% to -7.1%, measured by length-controlled win rates against sequential decoding baseline.
StagFormer: Time Staggering Transformer Decoding for RunningLayers In Parallel
Jan 26, 2025Standard decoding in a Transformer based language model is inherently sequential as we wait for a token's embedding to pass through all the layers in the network before starting the generation of the next token. In this work, we propose a new architecture StagFormer (Staggered Transformer), which staggered execution along the time axis and thereby enables parallelizing the decoding process along the depth of the model. We achieve this by breaking the dependency of the token representation at time step $i$ in layer $l$ upon the representations of tokens until time step $i$ from layer $l-1$. Instead, we stagger the execution and only allow a dependency on token representations until time step $i-1$. The later sections of the Transformer still get access to the ``rich" representations from the prior section but only from those token positions which are one time step behind. StagFormer allows for different sections of the model to be executed in parallel yielding at potential 33\% speedup in decoding while being quality neutral in our simulations. We also explore many natural variants of this idea. We present how weight-sharing across the different sections being staggered can be more practical in settings with limited memory. We show how one can approximate a recurrent model during inference using such weight-sharing. We explore the efficacy of using a bounded window attention to pass information from one section to another which helps drive further latency gains for some applications. We also explore demonstrate the scalability of the staggering idea over more than 2 sections of the Transformer.
On the Role of Depth and Looping for In-Context Learning with Task Diversity
Oct 29, 2024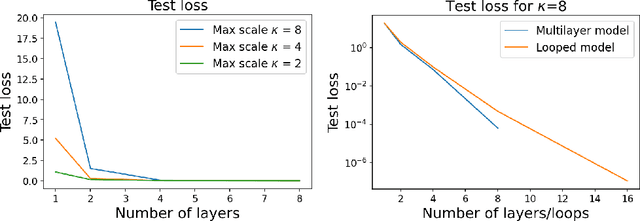
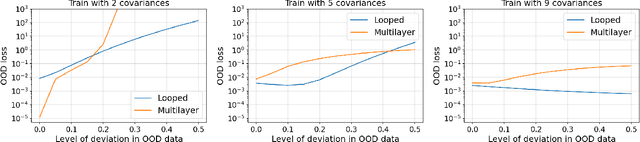
The intriguing in-context learning (ICL) abilities of deep Transformer models have lately garnered significant attention. By studying in-context linear regression on unimodal Gaussian data, recent empirical and theoretical works have argued that ICL emerges from Transformers' abilities to simulate learning algorithms like gradient descent. However, these works fail to capture the remarkable ability of Transformers to learn multiple tasks in context. To this end, we study in-context learning for linear regression with diverse tasks, characterized by data covariance matrices with condition numbers ranging from $[1, \kappa]$, and highlight the importance of depth in this setting. More specifically, (a) we show theoretical lower bounds of $\log(\kappa)$ (or $\sqrt{\kappa}$) linear attention layers in the unrestricted (or restricted) attention setting and, (b) we show that multilayer Transformers can indeed solve such tasks with a number of layers that matches the lower bounds. However, we show that this expressivity of multilayer Transformer comes at the price of robustness. In particular, multilayer Transformers are not robust to even distributional shifts as small as $O(e^{-L})$ in Wasserstein distance, where $L$ is the depth of the network. We then demonstrate that Looped Transformers -- a special class of multilayer Transformers with weight-sharing -- not only exhibit similar expressive power but are also provably robust under mild assumptions. Besides out-of-distribution generalization, we also show that Looped Transformers are the only models that exhibit a monotonic behavior of loss with respect to depth.
A Little Help Goes a Long Way: Efficient LLM Training by Leveraging Small LMs
Oct 24, 2024
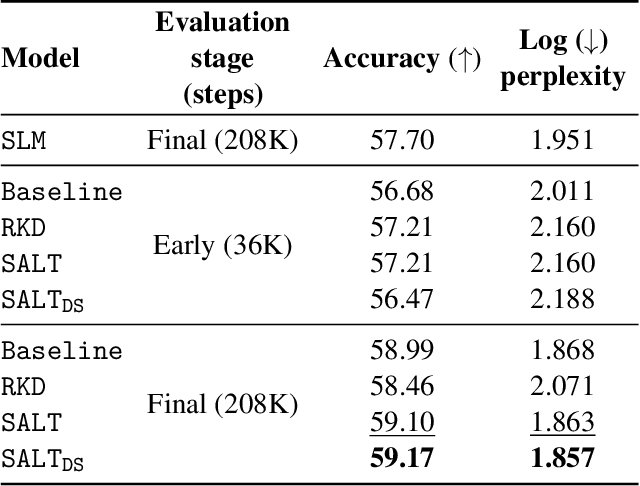

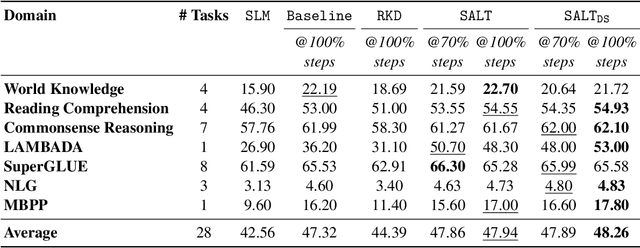
A primary challenge in large language model (LLM) development is their onerous pre-training cost. Typically, such pre-training involves optimizing a self-supervised objective (such as next-token prediction) over a large corpus. This paper explores a promising paradigm to improve LLM pre-training efficiency and quality by suitably leveraging a small language model (SLM). In particular, this paradigm relies on an SLM to both (1) provide soft labels as additional training supervision, and (2) select a small subset of valuable ("informative" and "hard") training examples. Put together, this enables an effective transfer of the SLM's predictive distribution to the LLM, while prioritizing specific regions of the training data distribution. Empirically, this leads to reduced LLM training time compared to standard training, while improving the overall quality. Theoretically, we develop a statistical framework to systematically study the utility of SLMs in enabling efficient training of high-quality LLMs. In particular, our framework characterizes how the SLM's seemingly low-quality supervision can enhance the training of a much more capable LLM. Furthermore, it also highlights the need for an adaptive utilization of such supervision, by striking a balance between the bias and variance introduced by the SLM-provided soft labels. We corroborate our theoretical framework by improving the pre-training of an LLM with 2.8B parameters by utilizing a smaller LM with 1.5B parameters on the Pile dataset.
Can Looped Transformers Learn to Implement Multi-step Gradient Descent for In-context Learning?
Oct 10, 2024
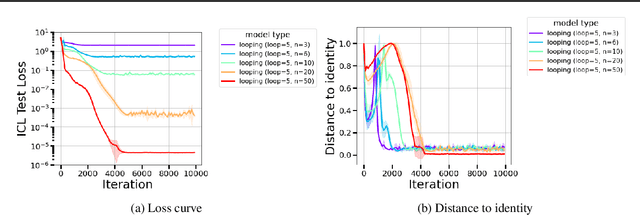
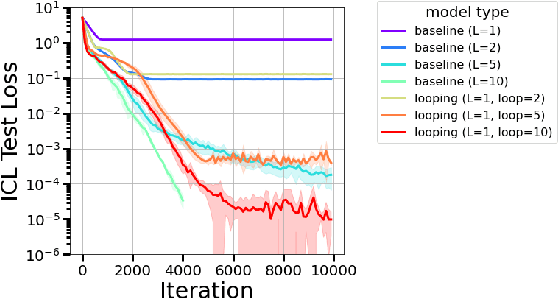
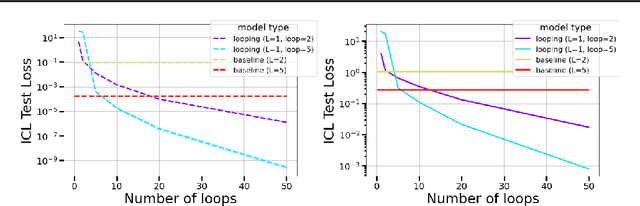
The remarkable capability of Transformers to do reasoning and few-shot learning, without any fine-tuning, is widely conjectured to stem from their ability to implicitly simulate a multi-step algorithms -- such as gradient descent -- with their weights in a single forward pass. Recently, there has been progress in understanding this complex phenomenon from an expressivity point of view, by demonstrating that Transformers can express such multi-step algorithms. However, our knowledge about the more fundamental aspect of its learnability, beyond single layer models, is very limited. In particular, can training Transformers enable convergence to algorithmic solutions? In this work we resolve this for in-context linear regression with linear looped Transformers -- a multi-layer model with weight sharing that is conjectured to have an inductive bias to learn fix-point iterative algorithms. More specifically, for this setting we show that the global minimizer of the population training loss implements multi-step preconditioned gradient descent, with a preconditioner that adapts to the data distribution. Furthermore, we show a fast convergence for gradient flow on the regression loss, despite the non-convexity of the landscape, by proving a novel gradient dominance condition. To our knowledge, this is the first theoretical analysis for multi-layer Transformer in this setting. We further validate our theoretical findings through synthetic experiments.
On the Inductive Bias of Stacking Towards Improving Reasoning
Sep 27, 2024Given the increasing scale of model sizes, novel training strategies like gradual stacking [Gong et al., 2019, Reddi et al., 2023] have garnered interest. Stacking enables efficient training by gradually growing the depth of a model in stages and using layers from a smaller model in an earlier stage to initialize the next stage. Although efficient for training, the model biases induced by such growing approaches are largely unexplored. In this work, we examine this fundamental aspect of gradual stacking, going beyond its efficiency benefits. We propose a variant of gradual stacking called MIDAS that can speed up language model training by up to 40%. Furthermore we discover an intriguing phenomenon: MIDAS is not only training-efficient but surprisingly also has an inductive bias towards improving downstream tasks, especially tasks that require reasoning abilities like reading comprehension and math problems, despite having similar or slightly worse perplexity compared to baseline training. To further analyze this inductive bias, we construct reasoning primitives -- simple synthetic tasks that are building blocks for reasoning -- and find that a model pretrained with stacking is significantly better than standard pretraining on these primitives, with and without fine-tuning. This provides stronger and more robust evidence for this inductive bias towards reasoning. These findings of training efficiency and inductive bias towards reasoning are verified at 1B, 2B and 8B parameter language models. Finally, we conjecture the underlying reason for this inductive bias by exploring the connection of stacking to looped models and provide strong supporting empirical analysis.
Landscape-Aware Growing: The Power of a Little LAG
Jun 04, 2024



Recently, there has been increasing interest in efficient pretraining paradigms for training Transformer-based models. Several recent approaches use smaller models to initialize larger models in order to save computation (e.g., stacking and fusion). In this work, we study the fundamental question of how to select the best growing strategy from a given pool of growing strategies. Prior works have extensively focused on loss- and/or function-preserving behavior at initialization or simply performance at the end of training. Instead, we identify that behavior at initialization can be misleading as a predictor of final performance and present an alternative perspective based on early training dynamics, which we call "landscape-aware growing (LAG)". We perform extensive analysis of correlation of the final performance with performance in the initial steps of training and find early and more accurate predictions of the optimal growing strategy (i.e., with only a small "lag" after initialization). This perspective also motivates an adaptive strategy for gradual stacking.
Efficient Stagewise Pretraining via Progressive Subnetworks
Feb 08, 2024



Recent developments in large language models have sparked interest in efficient pretraining methods. A recent effective paradigm is to perform stage-wise training, where the size of the model is gradually increased over the course of training (e.g. gradual stacking (Reddi et al., 2023)). While the resource and wall-time savings are appealing, it has limitations, particularly the inability to evaluate the full model during earlier stages, and degradation in model quality due to smaller model capacity in the initial stages. In this work, we propose an alternative framework, progressive subnetwork training, that maintains the full model throughout training, but only trains subnetworks within the model in each step. We focus on a simple instantiation of this framework, Random Path Training (RaPTr) that only trains a sub-path of layers in each step, progressively increasing the path lengths in stages. RaPTr achieves better pre-training loss for BERT and UL2 language models while requiring 20-33% fewer FLOPs compared to standard training, and is competitive or better than other efficient training methods. Furthermore, RaPTr shows better downstream performance on UL2, improving QA tasks and SuperGLUE by 1-5% compared to standard training and stacking. Finally, we provide a theoretical basis for RaPTr to justify (a) the increasing complexity of subnetworks in stages, and (b) the stability in loss across stage transitions due to residual connections and layer norm.
Reasoning in Large Language Models Through Symbolic Math Word Problems
Aug 03, 2023Large language models (LLMs) have revolutionized NLP by solving downstream tasks with little to no labeled data. Despite their versatile abilities, the larger question of their ability to reason remains ill-understood. This paper addresses reasoning in math word problems (MWPs) by studying symbolic versions of the numeric problems, since a symbolic expression is a "concise explanation" of the numeric answer. We create and use a symbolic version of the SVAMP dataset and find that GPT-3's davinci-002 model also has good zero-shot accuracy on symbolic MWPs. To evaluate the faithfulness of the model's reasoning, we go beyond accuracy and additionally evaluate the alignment between the final answer and the outputted reasoning, which correspond to numeric and symbolic answers respectively for MWPs. We explore a self-prompting approach to encourage the symbolic reasoning to align with the numeric answer, thus equipping the LLM with the ability to provide a concise and verifiable reasoning and making it more interpretable. Surprisingly, self-prompting also improves the symbolic accuracy to be higher than both the numeric and symbolic accuracies, thus providing an ensembling effect. The SVAMP_Sym dataset will be released for future research on symbolic math problems.