 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Keep a Promise: Scaling Language Model Decoding Parallelism with Learned Asynchronous Decoding
Feb 17, 2025

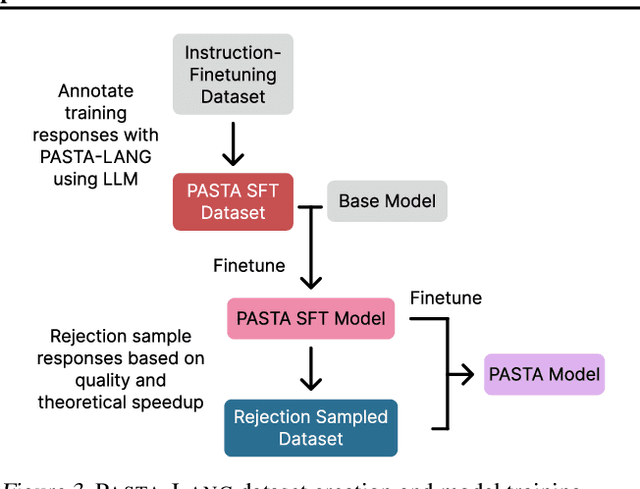
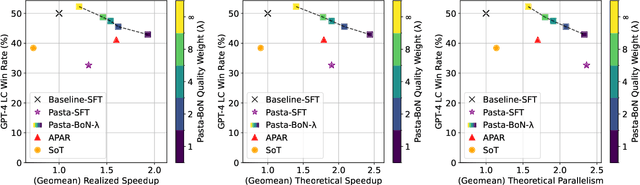
Decoding with autoregressive large language models (LLMs) traditionally occurs sequentially, generating one token after another. An emerging line of work explored parallel decoding by identifying and simultaneously generating semantically independent chunks of LLM responses. However, these techniques rely on hand-crafted heuristics tied to syntactic structures like lists and paragraphs, making them rigid and imprecise. We present PASTA, a learning-based system that teaches LLMs to identify semantic independence and express parallel decoding opportunities in their own responses. At its core are PASTA-LANG and its interpreter: PASTA-LANG is an annotation language that enables LLMs to express semantic independence in their own responses; the language interpreter acts on these annotations to orchestrate parallel decoding on-the-fly at inference time. Through a two-stage finetuning process, we train LLMs to generate PASTA-LANG annotations that optimize both response quality and decoding speed. Evaluation on AlpacaEval, an instruction following benchmark, shows that our approach Pareto-dominates existing methods in terms of decoding speed and response quality; our results demonstrate geometric mean speedups ranging from 1.21x to 1.93x with corresponding quality changes of +2.2% to -7.1%, measured by length-controlled win rates against sequential decoding baseline.
Vid3D: Synthesis of Dynamic 3D Scenes using 2D Video Diffusion
Jun 17, 2024A recent frontier in computer vision has been the task of 3D video generation, which consists of generating a time-varying 3D representation of a scene. To generate dynamic 3D scenes, current methods explicitly model 3D temporal dynamics by jointly optimizing for consistency across both time and views of the scene. In this paper, we instead investigate whether it is necessary to explicitly enforce multiview consistency over time, as current approaches do, or if it is sufficient for a model to generate 3D representations of each timestep independently. We hence propose a model, Vid3D, that leverages 2D video diffusion to generate 3D videos by first generating a 2D "seed" of the video's temporal dynamics and then independently generating a 3D representation for each timestep in the seed video. We evaluate Vid3D against two state-of-the-art 3D video generation methods and find that Vid3D is achieves comparable results despite not explicitly modeling 3D temporal dynamics. We further ablate how the quality of Vid3D depends on the number of views generated per frame. While we observe some degradation with fewer views, performance degradation remains minor. Our results thus suggest that 3D temporal knowledge may not be necessary to generate high-quality dynamic 3D scenes, potentially enabling simpler generative algorithms for this task.