 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Inductive Bias of Stacking Towards Improving Reasoning
Sep 27, 2024Given the increasing scale of model sizes, novel training strategies like gradual stacking [Gong et al., 2019, Reddi et al., 2023] have garnered interest. Stacking enables efficient training by gradually growing the depth of a model in stages and using layers from a smaller model in an earlier stage to initialize the next stage. Although efficient for training, the model biases induced by such growing approaches are largely unexplored. In this work, we examine this fundamental aspect of gradual stacking, going beyond its efficiency benefits. We propose a variant of gradual stacking called MIDAS that can speed up language model training by up to 40%. Furthermore we discover an intriguing phenomenon: MIDAS is not only training-efficient but surprisingly also has an inductive bias towards improving downstream tasks, especially tasks that require reasoning abilities like reading comprehension and math problems, despite having similar or slightly worse perplexity compared to baseline training. To further analyze this inductive bias, we construct reasoning primitives -- simple synthetic tasks that are building blocks for reasoning -- and find that a model pretrained with stacking is significantly better than standard pretraining on these primitives, with and without fine-tuning. This provides stronger and more robust evidence for this inductive bias towards reasoning. These findings of training efficiency and inductive bias towards reasoning are verified at 1B, 2B and 8B parameter language models. Finally, we conjecture the underlying reason for this inductive bias by exploring the connection of stacking to looped models and provide strong supporting empirical analysis.
Landscape-Aware Growing: The Power of a Little LAG
Jun 04, 2024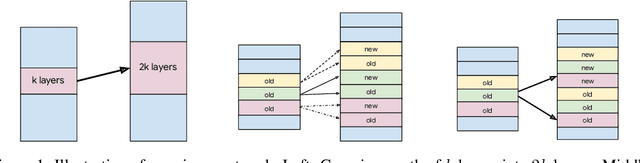



Recently, there has been increasing interest in efficient pretraining paradigms for training Transformer-based models. Several recent approaches use smaller models to initialize larger models in order to save computation (e.g., stacking and fusion). In this work, we study the fundamental question of how to select the best growing strategy from a given pool of growing strategies. Prior works have extensively focused on loss- and/or function-preserving behavior at initialization or simply performance at the end of training. Instead, we identify that behavior at initialization can be misleading as a predictor of final performance and present an alternative perspective based on early training dynamics, which we call "landscape-aware growing (LAG)". We perform extensive analysis of correlation of the final performance with performance in the initial steps of training and find early and more accurate predictions of the optimal growing strategy (i.e., with only a small "lag" after initialization). This perspective also motivates an adaptive strategy for gradual stacking.
Efficient Stagewise Pretraining via Progressive Subnetworks
Feb 08, 2024



Recent developments in large language models have sparked interest in efficient pretraining methods. A recent effective paradigm is to perform stage-wise training, where the size of the model is gradually increased over the course of training (e.g. gradual stacking (Reddi et al., 2023)). While the resource and wall-time savings are appealing, it has limitations, particularly the inability to evaluate the full model during earlier stages, and degradation in model quality due to smaller model capacity in the initial stages. In this work, we propose an alternative framework, progressive subnetwork training, that maintains the full model throughout training, but only trains subnetworks within the model in each step. We focus on a simple instantiation of this framework, Random Path Training (RaPTr) that only trains a sub-path of layers in each step, progressively increasing the path lengths in stages. RaPTr achieves better pre-training loss for BERT and UL2 language models while requiring 20-33% fewer FLOPs compared to standard training, and is competitive or better than other efficient training methods. Furthermore, RaPTr shows better downstream performance on UL2, improving QA tasks and SuperGLUE by 1-5% compared to standard training and stacking. Finally, we provide a theoretical basis for RaPTr to justify (a) the increasing complexity of subnetworks in stages, and (b) the stability in loss across stage transitions due to residual connections and layer norm.
ReST meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent
Dec 15, 2023Answering complex natural language questions often necessitates multi-step reasoning and integrating external information. Several systems have combined knowledge retrieval with a large language model (LLM) to answer such questions. These systems, however, suffer from various failure cases, and we cannot directly train them end-to-end to fix such failures, as interaction with external knowledge is non-differentiable. To address these deficiencies, we define a ReAct-style LLM agent with the ability to reason and act upon external knowledge. We further refine the agent through a ReST-like method that iteratively trains on previous trajectories, employing growing-batch reinforcement learning with AI feedback for continuous self-improvement and self-distillation. Starting from a prompted large model and after just two iterations of the algorithm, we can produce a fine-tuned small model that achieves comparable performance on challenging compositional question-answering benchmarks with two orders of magnitude fewer parameters.
Provable Reinforcement Learning with a Short-Term Memory
Feb 08, 2022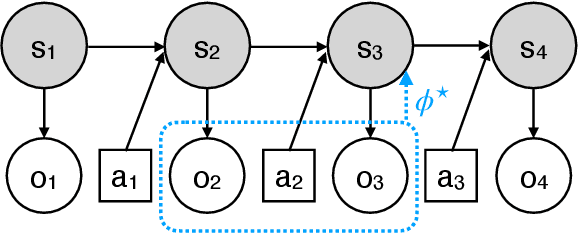
Real-world sequential decision making problems commonly involve partial observability, which requires the agent to maintain a memory of history in order to infer the latent states, plan and make good decisions. Coping with partial observability in general is extremely challenging, as a number of worst-case statistical and computational barriers are known in learning Partially Observable Markov Decision Processes (POMDPs). Motivated by the problem structure in several physical applications, as well as a commonly used technique known as "frame stacking", this paper proposes to study a new subclass of POMDPs, whose latent states can be decoded by the most recent history of a short length $m$. We establish a set of upper and lower bounds on the sample complexity for learning near-optimal policies for this class of problems in both tabular and rich-observation settings (where the number of observations is enormous). In particular, in the rich-observation setting, we develop new algorithms using a novel "moment matching" approach with a sample complexity that scales exponentially with the short length $m$ rather than the problem horizon, and is independent of the number of observations. Our results show that a short-term memory suffices for reinforcement learning in these environments.
A Simple Reward-free Approach to Constrained Reinforcement Learning
Jul 12, 2021
In constrained reinforcement learning (RL), a learning agent seeks to not only optimize the overall reward but also satisfy the additional safety, diversity, or budget constraints. Consequently, existing constrained RL solutions require several new algorithmic ingredients that are notably different from standard RL. On the other hand, reward-free RL is independently developed in the unconstrained literature, which learns the transition dynamics without using the reward information, and thus naturally capable of addressing RL with multiple objectives under the common dynamics. This paper bridges reward-free RL and constrained RL. Particularly, we propose a simple meta-algorithm such that given any reward-free RL oracle, the approachability and constrained RL problems can be directly solved with negligible overheads in sample complexity. Utilizing the existing reward-free RL solvers, our framework provides sharp sample complexity results for constrained RL in the tabular MDP setting, matching the best existing results up to a factor of horizon dependence; our framework directly extends to a setting of tabular two-player Markov games, and gives a new result for constrained RL with linear function approximation.
Bellman Eluder Dimension: New Rich Classes of RL Problems, and Sample-Efficient Algorithms
Feb 05, 2021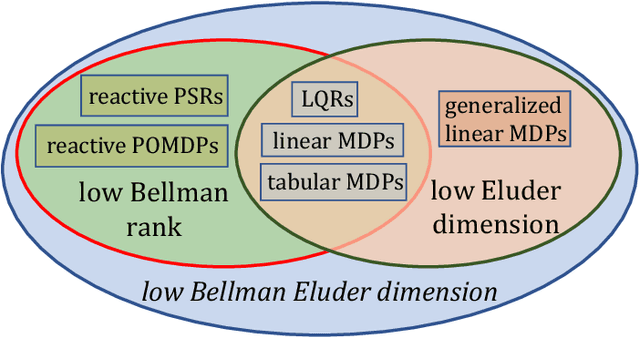
Finding the minimal structural assumptions that empower sample-efficient learning is one of the most important research directions in Reinforcement Learning (RL). This paper advances our understanding of this fundamental question by introducing a new complexity measure -- Bellman Eluder (BE) dimension. We show that the family of RL problems of low BE dimension is remarkably rich, which subsumes a vast majority of existing tractable RL problems including but not limited to tabular MDPs, linear MDPs, reactive POMDPs, low Bellman rank problems as well as low Eluder dimension problems. This paper further designs a new optimization-based algorithm -- GOLF, and reanalyzes a hypothesis elimination-based algorithm -- OLIVE (proposed in Jiang et al. (2017)). We prove that both algorithms learn the near-optimal policies of low BE dimension problems in a number of samples that is polynomial in all relevant parameters, but independent of the size of state-action space. Our regret and sample complexity results match or improve the best existing results for several well-known subclasses of low BE dimension problems.
Constrained episodic reinforcement learning in concave-convex and knapsack settings
Jun 09, 2020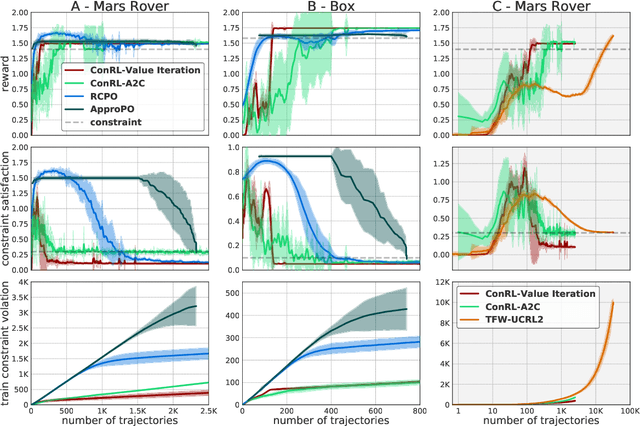

We propose an algorithm for tabular episodic reinforcement learning with constraints. We provide a modular analysis with strong theoretical guarantees for settings with concave rewards and convex constraints, and for settings with hard constraints (knapsacks). Most of the previous work in constrained reinforcement learning is limited to linear constraints, and the remaining work focuses on either the feasibility question or settings with a single episode. Our experiments demonstrate that the proposed algorithm significantly outperforms these approaches in existing constrained episodic environments.
Reinforcement Learning with Convex Constraints
Jun 21, 2019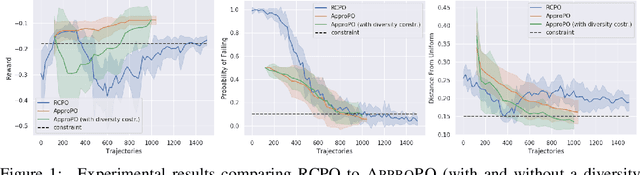
In standard reinforcement learning (RL), a learning agent seeks to optimize the overall reward. However, many key aspects of a desired behavior are more naturally expressed as constraints. For instance, the designer may want to limit the use of unsafe actions, increase the diversity of trajectories to enable exploration, or approximate expert trajectories when rewards are sparse. In this paper, we propose an algorithmic scheme that can handle a wide class of constraints in RL tasks: specifically, any constraints that require expected values of some vector measurements (such as the use of an action) to lie in a convex set. This captures previously studied constraints (such as safety and proximity to an expert), but also enables new classes of constraints (such as diversity). Our approach comes with rigorous theoretical guarantees and only relies on the ability to approximately solve standard RL tasks. As a result, it can be easily adapted to work with any model-free or model-based RL. In our experiments, we show that it matches previous algorithms that enforce safety via constraints, but can also enforce new properties that these algorithms do not incorporate, such as diversity.