 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Reinforcement Learning with a Short-Term Memory
Paper and Code
Feb 08, 2022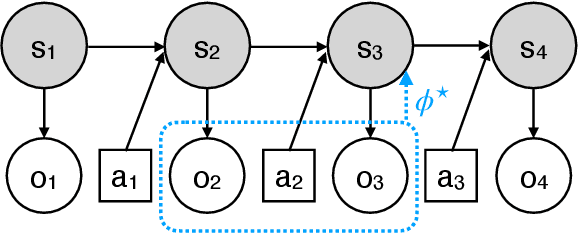
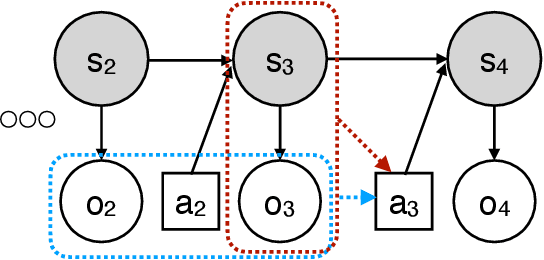
Real-world sequential decision making problems commonly involve partial observability, which requires the agent to maintain a memory of history in order to infer the latent states, plan and make good decisions. Coping with partial observability in general is extremely challenging, as a number of worst-case statistical and computational barriers are known in learning Partially Observable Markov Decision Processes (POMDPs). Motivated by the problem structure in several physical applications, as well as a commonly used technique known as "frame stacking", this paper proposes to study a new subclass of POMDPs, whose latent states can be decoded by the most recent history of a short length $m$. We establish a set of upper and lower bounds on the sample complexity for learning near-optimal policies for this class of problems in both tabular and rich-observation settings (where the number of observations is enormous). In particular, in the rich-observation setting, we develop new algorithms using a novel "moment matching" approach with a sample complexity that scales exponentially with the short length $m$ rather than the problem horizon, and is independent of the number of observations. Our results show that a short-term memory suffices for reinforcement learning in these environments.