 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining neural networks faster with minimal tuning using pre-computed lists of hyperparameters for NAdamW
Mar 06, 2025



If we want to train a neural network using any of the most popular optimization algorithms, we are immediately faced with a dilemma: how to set the various optimization and regularization hyperparameters? When computational resources are abundant, there are a variety of methods for finding good hyperparameter settings, but when resources are limited the only realistic choices are using standard default values of uncertain quality and provenance, or tuning only a couple of the most important hyperparameters via extremely limited handdesigned sweeps. Extending the idea of default settings to a modest tuning budget, Metz et al. (2020) proposed using ordered lists of well-performing hyperparameter settings, derived from a broad hyperparameter search on a large library of training workloads. However, to date, no practical and performant hyperparameter lists that generalize to representative deep learning workloads have been demonstrated. In this paper, we present hyperparameter lists for NAdamW derived from extensive experiments on the realistic workloads in the AlgoPerf: Training Algorithms benchmark. Our hyperparameter lists also include values for basic regularization techniques (i.e. weight decay, label smoothing, and dropout). In particular, our best NAdamW hyperparameter list performs well on AlgoPerf held-out workloads not used to construct it, and represents a compelling turn-key approach to tuning when restricted to five or fewer trials. It also outperforms basic learning rate/weight decay sweeps and an off-the-shelf Bayesian optimization tool when restricted to the same budget.
On the Inductive Bias of Stacking Towards Improving Reasoning
Sep 27, 2024Given the increasing scale of model sizes, novel training strategies like gradual stacking [Gong et al., 2019, Reddi et al., 2023] have garnered interest. Stacking enables efficient training by gradually growing the depth of a model in stages and using layers from a smaller model in an earlier stage to initialize the next stage. Although efficient for training, the model biases induced by such growing approaches are largely unexplored. In this work, we examine this fundamental aspect of gradual stacking, going beyond its efficiency benefits. We propose a variant of gradual stacking called MIDAS that can speed up language model training by up to 40%. Furthermore we discover an intriguing phenomenon: MIDAS is not only training-efficient but surprisingly also has an inductive bias towards improving downstream tasks, especially tasks that require reasoning abilities like reading comprehension and math problems, despite having similar or slightly worse perplexity compared to baseline training. To further analyze this inductive bias, we construct reasoning primitives -- simple synthetic tasks that are building blocks for reasoning -- and find that a model pretrained with stacking is significantly better than standard pretraining on these primitives, with and without fine-tuning. This provides stronger and more robust evidence for this inductive bias towards reasoning. These findings of training efficiency and inductive bias towards reasoning are verified at 1B, 2B and 8B parameter language models. Finally, we conjecture the underlying reason for this inductive bias by exploring the connection of stacking to looped models and provide strong supporting empirical analysis.
Benchmarking Neural Network Training Algorithms
Jun 12, 2023



Training algorithms, broadly construed, are an essential part of every deep learning pipeline. Training algorithm improvements that speed up training across a wide variety of workloads (e.g., better update rules, tuning protocols, learning rate schedules, or data selection schemes) could save time, save computational resources, and lead to better, more accurate, models. Unfortunately, as a community, we are currently unable to reliably identify training algorithm improvements, or even determine the state-of-the-art training algorithm. In this work, using concrete experiments, we argue that real progress in speeding up training requires new benchmarks that resolve three basic challenges faced by empirical comparisons of training algorithms: (1) how to decide when training is complete and precisely measure training time, (2) how to handle the sensitivity of measurements to exact workload details, and (3) how to fairly compare algorithms that require hyperparameter tuning. In order to address these challenges, we introduce a new, competitive, time-to-result benchmark using multiple workloads running on fixed hardware, the AlgoPerf: Training Algorithms benchmark. Our benchmark includes a set of workload variants that make it possible to detect benchmark submissions that are more robust to workload changes than current widely-used methods. Finally, we evaluate baseline submissions constructed using various optimizers that represent current practice, as well as other optimizers that have recently received attention in the literature. These baseline results collectively demonstrate the feasibility of our benchmark, show that non-trivial gaps between methods exist, and set a provisional state-of-the-art for future benchmark submissions to try and surpass.
Adaptive Gradient Methods at the Edge of Stability
Jul 29, 2022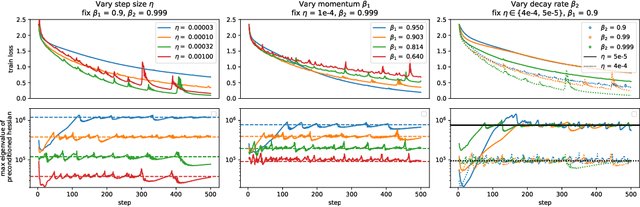
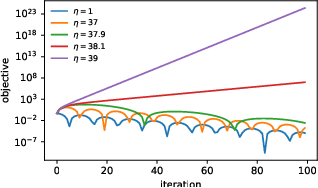

Very little is known about the training dynamics of adaptive gradient methods like Adam in deep learning. In this paper, we shed light on the behavior of these algorithms in the full-batch and sufficiently large batch settings. Specifically, we empirically demonstrate that during full-batch training, the maximum eigenvalue of the preconditioned Hessian typically equilibrates at a certain numerical value -- the stability threshold of a gradient descent algorithm. For Adam with step size $\eta$ and $\beta_1 = 0.9$, this stability threshold is $38/\eta$. Similar effects occur during minibatch training, especially as the batch size grows. Yet, even though adaptive methods train at the ``Adaptive Edge of Stability'' (AEoS), their behavior in this regime differs in a significant way from that of non-adaptive methods at the EoS. Whereas non-adaptive algorithms at the EoS are blocked from entering high-curvature regions of the loss landscape, adaptive gradient methods at the AEoS can keep advancing into high-curvature regions, while adapting the preconditioner to compensate. Our findings can serve as a foundation for the community's future understanding of adaptive gradient methods in deep learning.
A Unifying View on Implicit Bias in Training Linear Neural Networks
Oct 06, 2020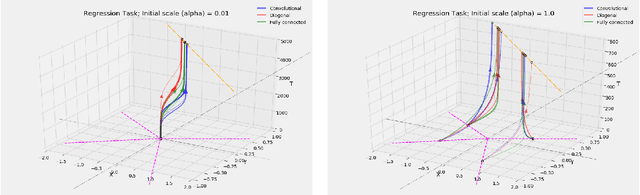
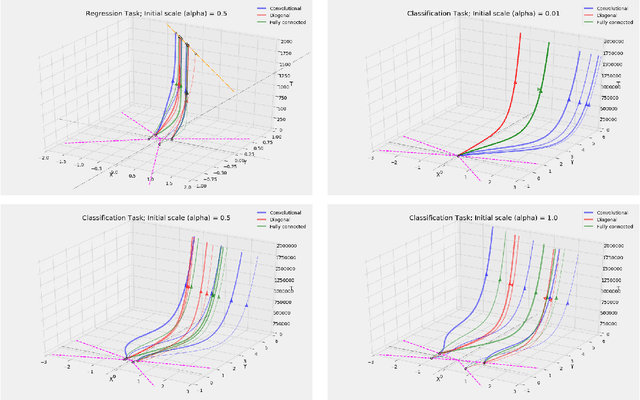
We study the implicit bias of gradient flow (i.e., gradient descent with infinitesimal step size) on linear neural network training. We propose a tensor formulation of neural networks that includes fully-connected, diagonal, and convolutional networks as special cases, and investigate the linear version of the formulation called linear tensor networks. For $L$-layer linear tensor networks that are orthogonally decomposable, we show that gradient flow on separable classification finds a stationary point of the $\ell_{2/L}$ max-margin problem in a "transformed" input space defined by the network. For underdetermined regression, we prove that gradient flow finds a global minimum which minimizes a norm-like function that interpolates between weighted $\ell_1$ and $\ell_2$ norms in the transformed input space. Our theorems subsume existing results in the literature while removing most of the convergence assumptions. We also provide experiments that corroborate our analysis.
Explaining Memorization and Generalization: A Large-Scale Study with Coherent Gradients
Mar 16, 2020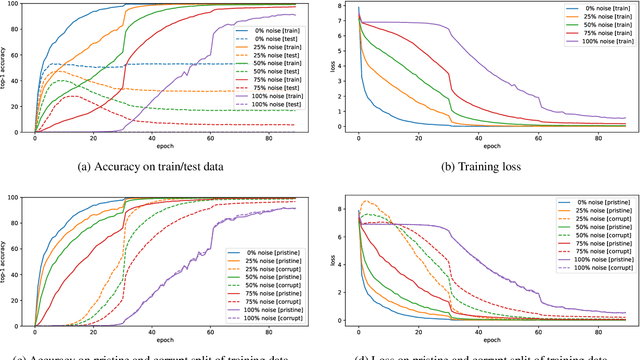
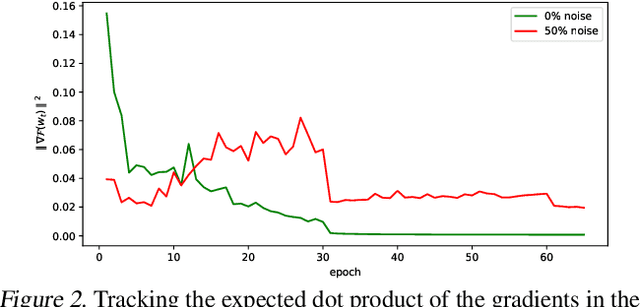
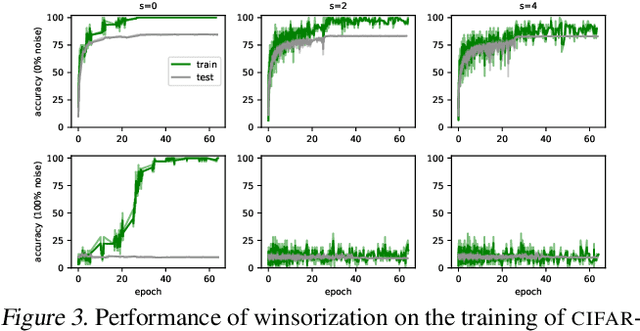

Coherent Gradients is a recently proposed hypothesis to explain why over-parameterized neural networks trained with gradient descent generalize well even though they have sufficient capacity to memorize the training set. Inspired by random forests, Coherent Gradients proposes that (Stochastic) Gradient Descent (SGD) finds common patterns amongst examples (if such common patterns exist) since descent directions that are common to many examples add up in the overall gradient, and thus the biggest changes to the network parameters are those that simultaneously help many examples. The original Coherent Gradients paper validated the theory through causal intervention experiments on shallow, fully connected networks on MNIST. In this work, we perform similar intervention experiments on more complex architectures (such as VGG, Inception and ResNet) on more complex datasets (such as CIFAR-10 and ImageNet). Our results are in good agreement with the small scale study in the original paper, thus providing the first validation of coherent gradients in more practically relevant settings. We also confirm in these settings that suppressing incoherent updates by natural modifications to SGD can significantly reduce overfitting--lending credence to the hypothesis that memorization occurs when few examples are responsible for most of the gradient used in the update. Furthermore, we use the coherent gradients theory to explore a new characterization of why some examples are learned earlier than other examples, i.e., "easy" and "hard" examples.
Filter Response Normalization Layer: Eliminating Batch Dependence in the Training of Deep Neural Networks
Nov 21, 2019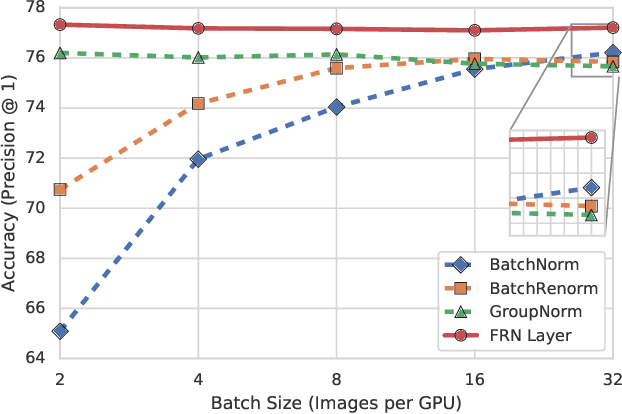
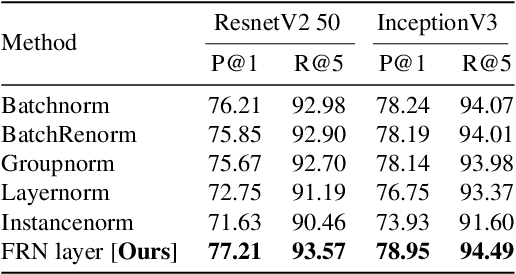
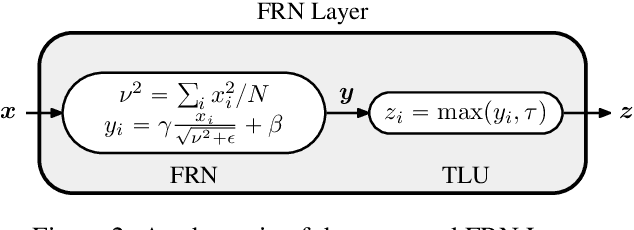
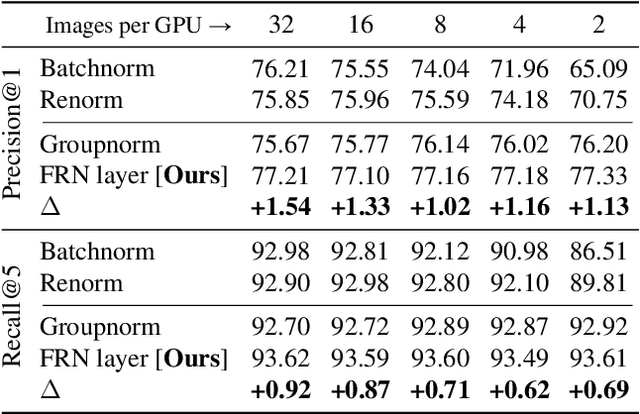
Batch Normalization (BN) is a highly successful and widely used batch dependent training method. Its use of mini-batch statistics to normalize the activations introduces dependence between samples, which can hurt the training if the mini-batch size is too small, or if the samples are correlated. Several alternatives, such as Batch Renormalization and Group Normalization (GN), have been proposed to address these issues. However, they either do not match the performance of BN for large batches, or still exhibit degradation in performance for smaller batches, or introduce artificial constraints on the model architecture. In this paper we propose the Filter Response Normalization (FRN) layer, a novel combination of a normalization and an activation function, that can be used as a drop-in replacement for other normalizations and activations. Our method operates on each activation map of each batch sample independently, eliminating the dependency on other batch samples or channels of the same sample. Our method outperforms BN and all alternatives in a variety of settings for all batch sizes. FRN layer performs $\approx 0.7-1.0\%$ better on top-1 validation accuracy than BN with large mini-batch sizes on Imagenet classification on InceptionV3 and ResnetV2-50 architectures. Further, it performs $>1\%$ better than GN on the same problem in the small mini-batch size regime. For object detection problem on COCO dataset, FRN layer outperforms all other methods by at least $0.3-0.5\%$ in all batch size regimes.
An Investigation into Neural Net Optimization via Hessian Eigenvalue Density
Jan 29, 2019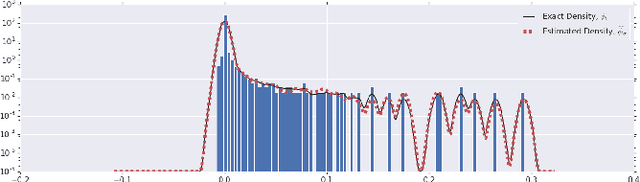
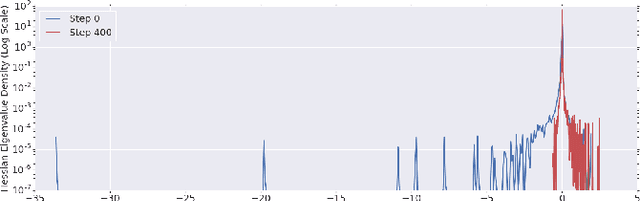
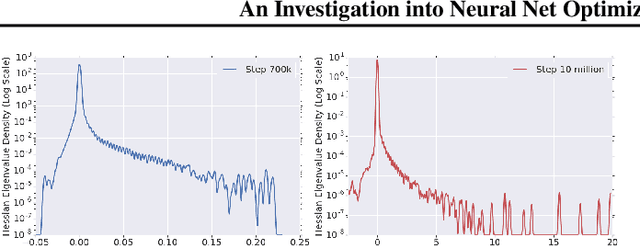
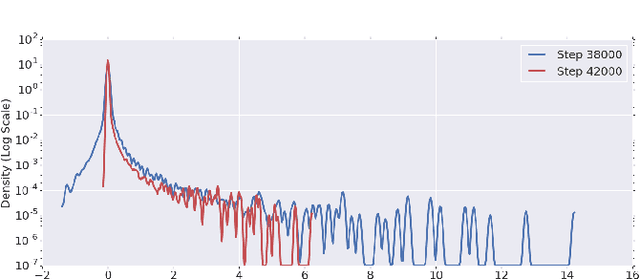
To understand the dynamics of optimization in deep neural networks, we develop a tool to study the evolution of the entire Hessian spectrum throughout the optimization process. Using this, we study a number of hypotheses concerning smoothness, curvature, and sharpness in the deep learning literature. We then thoroughly analyze a crucial structural feature of the spectra: in non-batch normalized networks, we observe the rapid appearance of large isolated eigenvalues in the spectrum, along with a surprising concentration of the gradient in the corresponding eigenspaces. In batch normalized networks, these two effects are almost absent. We characterize these effects, and explain how they affect optimization speed through both theory and experiments. As part of this work, we adapt advanced tools from numerical linear algebra that allow scalable and accurate estimation of the entire Hessian spectrum of ImageNet-scale neural networks; this technique may be of independent interest in other applications.
Neumann Optimizer: A Practical Optimization Algorithm for Deep Neural Networks
Dec 08, 2017
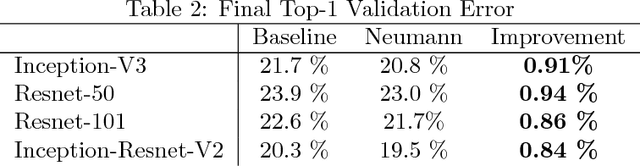


Progress in deep learning is slowed by the days or weeks it takes to train large models. The natural solution of using more hardware is limited by diminishing returns, and leads to inefficient use of additional resources. In this paper, we present a large batch, stochastic optimization algorithm that is both faster than widely used algorithms for fixed amounts of computation, and also scales up substantially better as more computational resources become available. Our algorithm implicitly computes the inverse Hessian of each mini-batch to produce descent directions; we do so without either an explicit approximation to the Hessian or Hessian-vector products. We demonstrate the effectiveness of our algorithm by successfully training large ImageNet models (Inception-V3, Resnet-50, Resnet-101 and Inception-Resnet-V2) with mini-batch sizes of up to 32000 with no loss in validation error relative to current baselines, and no increase in the total number of steps. At smaller mini-batch sizes, our optimizer improves the validation error in these models by 0.8-0.9%. Alternatively, we can trade off this accuracy to reduce the number of training steps needed by roughly 10-30%. Our work is practical and easily usable by others -- only one hyperparameter (learning rate) needs tuning, and furthermore, the algorithm is as computationally cheap as the commonly used Adam optimizer.
Achieving Approximate Soft Clustering in Data Streams
Jul 26, 2012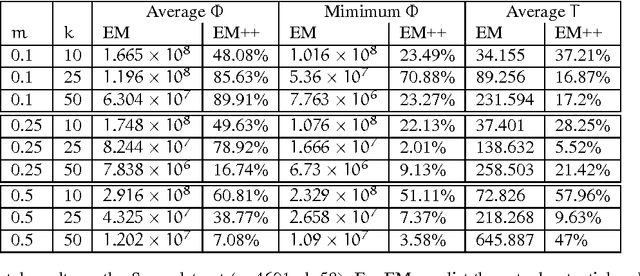
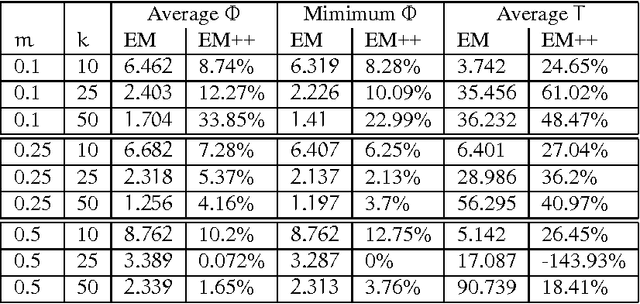
In recent years, data streaming has gained prominence due to advances in technologies that enable many applications to generate continuous flows of data. This increases the need to develop algorithms that are able to efficiently process data streams. Additionally, real-time requirements and evolving nature of data streams make stream mining problems, including clustering, challenging research problems. In this paper, we propose a one-pass streaming soft clustering (membership of a point in a cluster is described by a distribution) algorithm which approximates the "soft" version of the k-means objective function. Soft clustering has applications in various aspects of databases and machine learning including density estimation and learning mixture models. We first achieve a simple pseudo-approximation in terms of the "hard" k-means algorithm, where the algorithm is allowed to output more than $k$ centers. We convert this batch algorithm to a streaming one (using an extension of the k-means++ algorithm recently proposed) in the "cash register" model. We also extend this algorithm when the clustering is done over a moving window in the data stream.