 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining neural networks faster with minimal tuning using pre-computed lists of hyperparameters for NAdamW
Mar 06, 2025



If we want to train a neural network using any of the most popular optimization algorithms, we are immediately faced with a dilemma: how to set the various optimization and regularization hyperparameters? When computational resources are abundant, there are a variety of methods for finding good hyperparameter settings, but when resources are limited the only realistic choices are using standard default values of uncertain quality and provenance, or tuning only a couple of the most important hyperparameters via extremely limited handdesigned sweeps. Extending the idea of default settings to a modest tuning budget, Metz et al. (2020) proposed using ordered lists of well-performing hyperparameter settings, derived from a broad hyperparameter search on a large library of training workloads. However, to date, no practical and performant hyperparameter lists that generalize to representative deep learning workloads have been demonstrated. In this paper, we present hyperparameter lists for NAdamW derived from extensive experiments on the realistic workloads in the AlgoPerf: Training Algorithms benchmark. Our hyperparameter lists also include values for basic regularization techniques (i.e. weight decay, label smoothing, and dropout). In particular, our best NAdamW hyperparameter list performs well on AlgoPerf held-out workloads not used to construct it, and represents a compelling turn-key approach to tuning when restricted to five or fewer trials. It also outperforms basic learning rate/weight decay sweeps and an off-the-shelf Bayesian optimization tool when restricted to the same budget.
A Loss Curvature Perspective on Training Instability in Deep Learning
Oct 08, 2021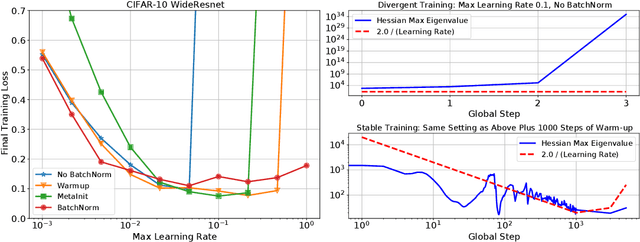

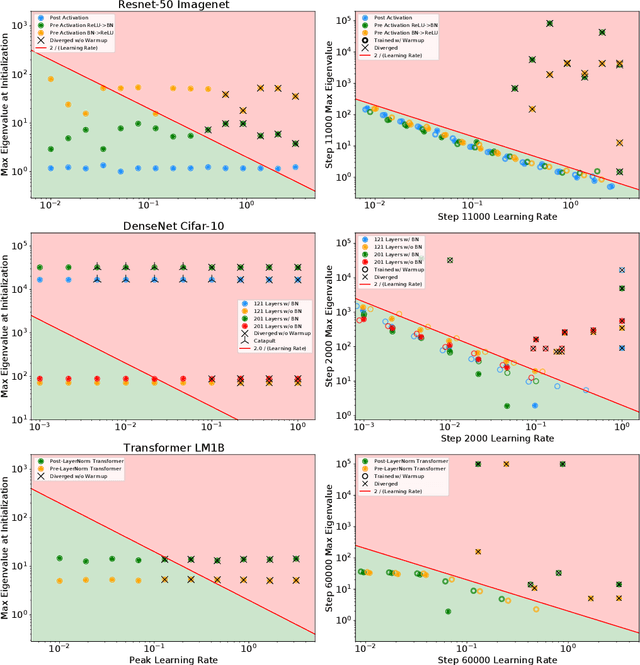

In this work, we study the evolution of the loss Hessian across many classification tasks in order to understand the effect the curvature of the loss has on the training dynamics. Whereas prior work has focused on how different learning rates affect the loss Hessian observed during training, we also analyze the effects of model initialization, architectural choices, and common training heuristics such as gradient clipping and learning rate warmup. Our results demonstrate that successful model and hyperparameter choices allow the early optimization trajectory to either avoid -- or navigate out of -- regions of high curvature and into flatter regions that tolerate a higher learning rate. Our results suggest a unifying perspective on how disparate mitigation strategies for training instability ultimately address the same underlying failure mode of neural network optimization, namely poor conditioning. Inspired by the conditioning perspective, we show that learning rate warmup can improve training stability just as much as batch normalization, layer normalization, MetaInit, GradInit, and Fixup initialization.
Relational inductive biases, deep learning, and graph networks
Oct 17, 2018
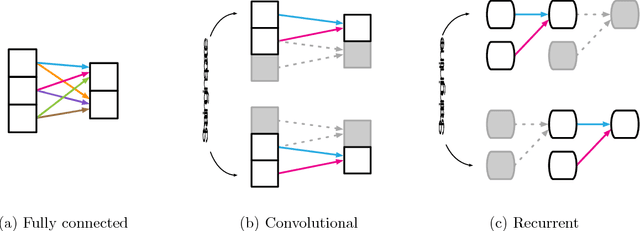
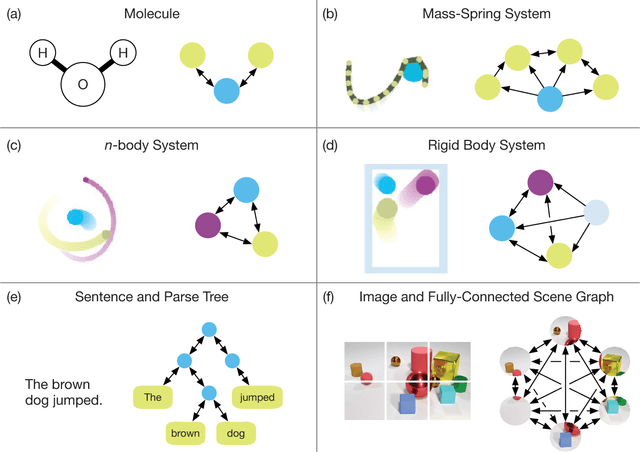
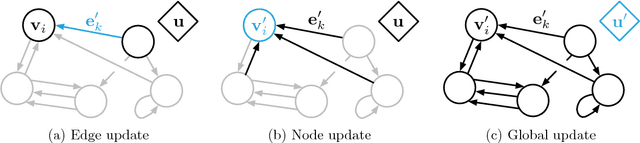
Artificial intelligence (AI) has undergone a renaissance recently, making major progress in key domains such as vision, language, control, and decision-making. This has been due, in part, to cheap data and cheap compute resources, which have fit the natural strengths of deep learning. However, many defining characteristics of human intelligence, which developed under much different pressures, remain out of reach for current approaches. In particular, generalizing beyond one's experiences--a hallmark of human intelligence from infancy--remains a formidable challenge for modern AI. The following is part position paper, part review, and part unification. We argue that combinatorial generalization must be a top priority for AI to achieve human-like abilities, and that structured representations and computations are key to realizing this objective. Just as biology uses nature and nurture cooperatively, we reject the false choice between "hand-engineering" and "end-to-end" learning, and instead advocate for an approach which benefits from their complementary strengths. We explore how using relational inductive biases within deep learning architectures can facilitate learning about entities, relations, and rules for composing them. We present a new building block for the AI toolkit with a strong relational inductive bias--the graph network--which generalizes and extends various approaches for neural networks that operate on graphs, and provides a straightforward interface for manipulating structured knowledge and producing structured behaviors. We discuss how graph networks can support relational reasoning and combinatorial generalization, laying the foundation for more sophisticated, interpretable, and flexible patterns of reasoning. As a companion to this paper, we have released an open-source software library for building graph networks, with demonstrations of how to use them in practice.
Peptide-Spectra Matching from Weak Supervision
Aug 22, 2018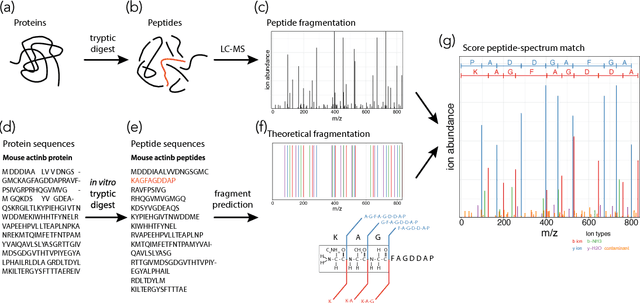

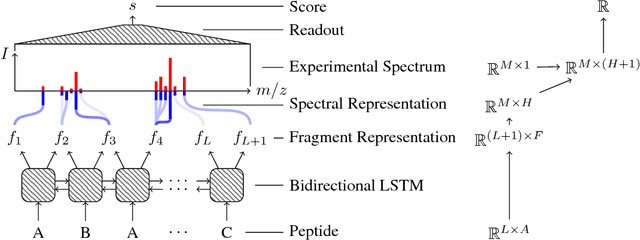

As in many other scientific domains, we face a fundamental problem when using machine learning to identify proteins from mass spectrometry data: large ground truth datasets mapping inputs to correct outputs are extremely difficult to obtain. Instead, we have access to imperfect hand-coded models crafted by domain experts. In this paper, we apply deep neural networks to an important step of the protein identification problem, the pairing of mass spectra with short sequences of amino acids called peptides. We train our model to differentiate between top scoring results from a state-of-the art classical system and hard-negative second and third place results. Our resulting model is much better at identifying peptides with spectra than the model used to generate its training data. In particular, we achieve a 43% improvement over standard matching methods and a 10% improvement over a combination of the matching method and an industry standard cross-spectra reranking tool. Importantly, in a more difficult experimental regime that reflects current challenges facing biologists, our advantage over the previous state-of-the-art grows to 15% even after reranking. We believe this approach will generalize to other challenging scientific problems.