 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiamond Maps: Efficient Reward Alignment via Stochastic Flow Maps
Feb 05, 2026Flow and diffusion models produce high-quality samples, but adapting them to user preferences or constraints post-training remains costly and brittle, a challenge commonly called reward alignment. We argue that efficient reward alignment should be a property of the generative model itself, not an afterthought, and redesign the model for adaptability. We propose "Diamond Maps", stochastic flow map models that enable efficient and accurate alignment to arbitrary rewards at inference time. Diamond Maps amortize many simulation steps into a single-step sampler, like flow maps, while preserving the stochasticity required for optimal reward alignment. This design makes search, sequential Monte Carlo, and guidance scalable by enabling efficient and consistent estimation of the value function. Our experiments show that Diamond Maps can be learned efficiently via distillation from GLASS Flows, achieve stronger reward alignment performance, and scale better than existing methods. Our results point toward a practical route to generative models that can be rapidly adapted to arbitrary preferences and constraints at inference time.
Is Your Conditional Diffusion Model Actually Denoising?
Dec 21, 2025We study the inductive biases of diffusion models with a conditioning-variable, which have seen widespread application as both text-conditioned generative image models and observation-conditioned continuous control policies. We observe that when these models are queried conditionally, their generations consistently deviate from the idealized "denoising" process upon which diffusion models are formulated, inducing disagreement between popular sampling algorithms (e.g. DDPM, DDIM). We introduce Schedule Deviation, a rigorous measure which captures the rate of deviation from a standard denoising process, and provide a methodology to compute it. Crucially, we demonstrate that the deviation from an idealized denoising process occurs irrespective of the model capacity or amount of training data. We posit that this phenomenon occurs due to the difficulty of bridging distinct denoising flows across different parts of the conditioning space and show theoretically how such a phenomenon can arise through an inductive bias towards smoothness.
e3: Learning to Explore Enables Extrapolation of Test-Time Compute for LLMs
Jun 10, 2025Test-time scaling offers a promising path to improve LLM reasoning by utilizing more compute at inference time; however, the true promise of this paradigm lies in extrapolation (i.e., improvement in performance on hard problems as LLMs keep "thinking" for longer, beyond the maximum token budget they were trained on). Surprisingly, we find that most existing reasoning models do not extrapolate well. We show that one way to enable extrapolation is by training the LLM to perform in-context exploration: training the LLM to effectively spend its test time budget by chaining operations (such as generation, verification, refinement, etc.), or testing multiple hypotheses before it commits to an answer. To enable in-context exploration, we identify three key ingredients as part of our recipe e3: (1) chaining skills that the base LLM has asymmetric competence in, e.g., chaining verification (easy) with generation (hard), as a way to implement in-context search; (2) leveraging "negative" gradients from incorrect traces to amplify exploration during RL, resulting in longer search traces that chains additional asymmetries; and (3) coupling task difficulty with training token budget during training via a specifically-designed curriculum to structure in-context exploration. Our recipe e3 produces the best known 1.7B model according to AIME'25 and HMMT'25 scores, and extrapolates to 2x the training token budget. Our e3-1.7B model not only attains high pass@1 scores, but also improves pass@k over the base model.
The Pitfalls of Imitation Learning when Actions are Continuous
Mar 12, 2025We study the problem of imitating an expert demonstrator in a discrete-time, continuous state-and-action control system. We show that, even if the dynamics are stable (i.e. contracting exponentially quickly), and the expert is smooth and deterministic, any smooth, deterministic imitator policy necessarily suffers error on execution that is exponentially larger, as a function of problem horizon, than the error under the distribution of expert training data. Our negative result applies to both behavior cloning and offline-RL algorithms, unless they produce highly "improper" imitator policies--those which are non-smooth, non-Markovian, or which exhibit highly state-dependent stochasticity--or unless the expert trajectory distribution is sufficiently "spread." We provide experimental evidence of the benefits of these more complex policy parameterizations, explicating the benefits of today's popular policy parameterizations in robot learning (e.g. action-chunking and Diffusion Policies). We also establish a host of complementary negative and positive results for imitation in control systems.
History-Guided Video Diffusion
Feb 10, 2025
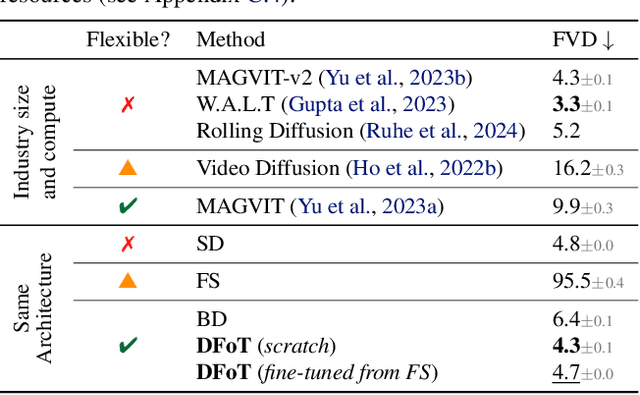
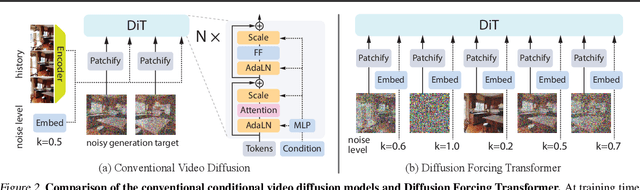
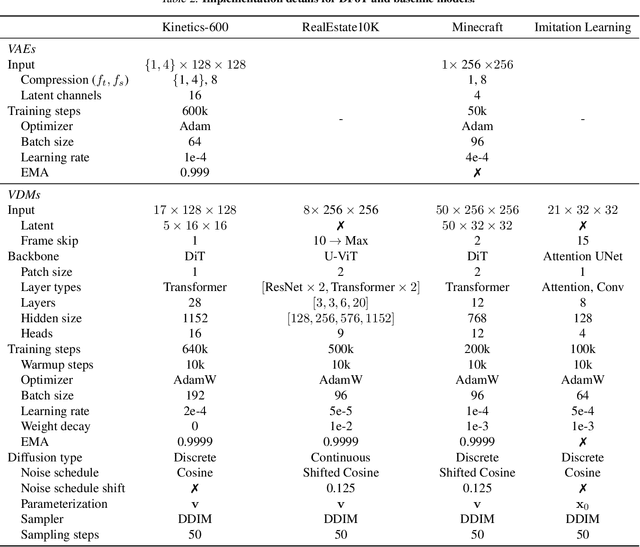
Classifier-free guidance (CFG) is a key technique for improving conditional generation in diffusion models, enabling more accurate control while enhancing sample quality. It is natural to extend this technique to video diffusion, which generates video conditioned on a variable number of context frames, collectively referred to as history. However, we find two key challenges to guiding with variable-length history: architectures that only support fixed-size conditioning, and the empirical observation that CFG-style history dropout performs poorly. To address this, we propose the Diffusion Forcing Transformer (DFoT), a video diffusion architecture and theoretically grounded training objective that jointly enable conditioning on a flexible number of history frames. We then introduce History Guidance, a family of guidance methods uniquely enabled by DFoT. We show that its simplest form, vanilla history guidance, already significantly improves video generation quality and temporal consistency. A more advanced method, history guidance across time and frequency further enhances motion dynamics, enables compositional generalization to out-of-distribution history, and can stably roll out extremely long videos. Website: https://boyuan.space/history-guidance
Self-Improvement in Language Models: The Sharpening Mechanism
Dec 02, 2024



Recent work in language modeling has raised the possibility of self-improvement, where a language models evaluates and refines its own generations to achieve higher performance without external feedback. It is impossible for this self-improvement to create information that is not already in the model, so why should we expect that this will lead to improved capabilities? We offer a new perspective on the capabilities of self-improvement through a lens we refer to as sharpening. Motivated by the observation that language models are often better at verifying response quality than they are at generating correct responses, we formalize self-improvement as using the model itself as a verifier during post-training in order to ``sharpen'' the model to one placing large mass on high-quality sequences, thereby amortizing the expensive inference-time computation of generating good sequences. We begin by introducing a new statistical framework for sharpening in which the learner aims to sharpen a pre-trained base policy via sample access, and establish fundamental limits. Then we analyze two natural families of self-improvement algorithms based on SFT and RLHF.
Is Linear Feedback on Smoothed Dynamics Sufficient for Stabilizing Contact-Rich Plans?
Nov 14, 2024



Designing planners and controllers for contact-rich manipulation is extremely challenging as contact violates the smoothness conditions that many gradient-based controller synthesis tools assume. Contact smoothing approximates a non-smooth system with a smooth one, allowing one to use these synthesis tools more effectively. However, applying classical control synthesis methods to smoothed contact dynamics remains relatively under-explored. This paper analyzes the efficacy of linear controller synthesis using differential simulators based on contact smoothing. We introduce natural baselines for leveraging contact smoothing to compute (a) open-loop plans robust to uncertain conditions and/or dynamics, and (b) feedback gains to stabilize around open-loop plans. Using robotic bimanual whole-body manipulation as a testbed, we perform extensive empirical experiments on over 300 trajectories and analyze why LQR seems insufficient for stabilizing contact-rich plans. The video summarizing this paper and hardware experiments is found here: https://youtu.be/HLaKi6qbwQg?si=_zCAmBBD6rGSitm9.
Faster Algorithms for Growing Collision-Free Convex Polytopes in Robot Configuration Space
Oct 16, 2024We propose two novel algorithms for constructing convex collision-free polytopes in robot configuration space. Finding these polytopes enables the application of stronger motion-planning frameworks such as trajectory optimization with Graphs of Convex Sets [1] and is currently a major roadblock in the adoption of these approaches. In this paper, we build upon IRIS-NP (Iterative Regional Inflation by Semidefinite & Nonlinear Programming) [2] to significantly improve tunability, runtimes, and scaling to complex environments. IRIS-NP uses nonlinear programming paired with uniform random initialization to find configurations on the boundary of the free configuration space. Our key insight is that finding near-by configuration-space obstacles using sampling is inexpensive and greatly accelerates region generation. We propose two algorithms using such samples to either employ nonlinear programming more efficiently (IRIS-NP2 ) or circumvent it altogether using a massively-parallel zero-order optimization strategy (IRIS-ZO). We also propose a termination condition that controls the probability of exceeding a user-specified permissible fraction-in-collision, eliminating a significant source of tuning difficulty in IRIS-NP. We compare performance across eight robot environments, showing that IRIS-ZO achieves an order-of-magnitude speed advantage over IRIS-NP. IRISNP2, also significantly faster than IRIS-NP, builds larger polytopes using fewer hyperplanes, enabling faster downstream computation. Website: https://sites.google.com/view/fastiris
Diffusion Policy Policy Optimization
Sep 01, 2024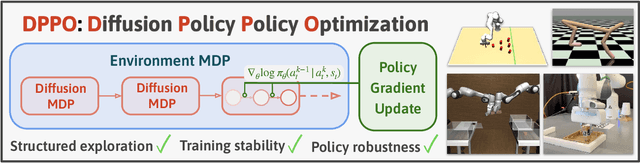

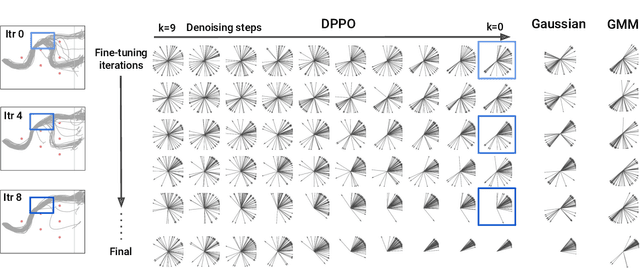
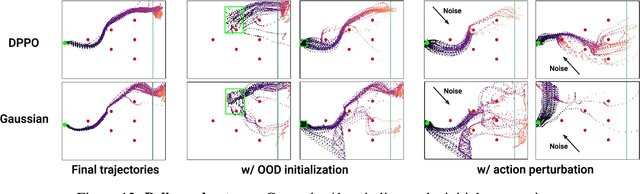
We introduce Diffusion Policy Policy Optimization, DPPO, an algorithmic framework including best practices for fine-tuning diffusion-based policies (e.g. Diffusion Policy) in continuous control and robot learning tasks using the policy gradient (PG) method from reinforcement learning (RL). PG methods are ubiquitous in training RL policies with other policy parameterizations; nevertheless, they had been conjectured to be less efficient for diffusion-based policies. Surprisingly, we show that DPPO achieves the strongest overall performance and efficiency for fine-tuning in common benchmarks compared to other RL methods for diffusion-based policies and also compared to PG fine-tuning of other policy parameterizations. Through experimental investigation, we find that DPPO takes advantage of unique synergies between RL fine-tuning and the diffusion parameterization, leading to structured and on-manifold exploration, stable training, and strong policy robustness. We further demonstrate the strengths of DPPO in a range of realistic settings, including simulated robotic tasks with pixel observations, and via zero-shot deployment of simulation-trained policies on robot hardware in a long-horizon, multi-stage manipulation task. Website with code: diffusion-ppo.github.io
Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion
Jul 02, 2024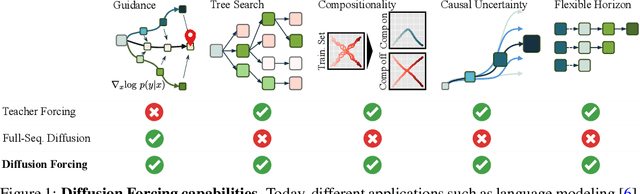
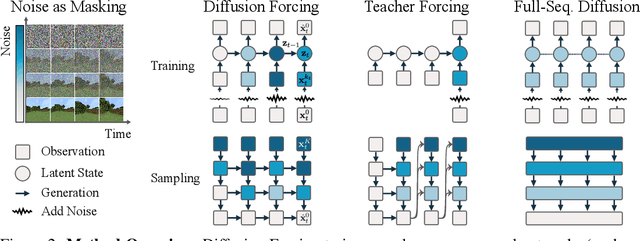
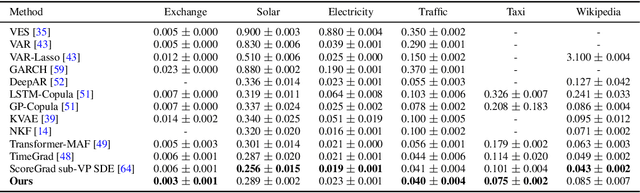
This paper presents Diffusion Forcing, a new training paradigm where a diffusion model is trained to denoise a set of tokens with independent per-token noise levels. We apply Diffusion Forcing to sequence generative modeling by training a causal next-token prediction model to generate one or several future tokens without fully diffusing past ones. Our approach is shown to combine the strengths of next-token prediction models, such as variable-length generation, with the strengths of full-sequence diffusion models, such as the ability to guide sampling to desirable trajectories. Our method offers a range of additional capabilities, such as (1) rolling-out sequences of continuous tokens, such as video, with lengths past the training horizon, where baselines diverge and (2) new sampling and guiding schemes that uniquely profit from Diffusion Forcing's variable-horizon and causal architecture, and which lead to marked performance gains in decision-making and planning tasks. In addition to its empirical success, our method is proven to optimize a variational lower bound on the likelihoods of all subsequences of tokens drawn from the true joint distribution. Project website: https://boyuan.space/diffusion-forcing/