 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-aware 4D Video Generation for Robot Manipulation
Jul 01, 2025Understanding and predicting the dynamics of the physical world can enhance a robot's ability to plan and interact effectively in complex environments. While recent video generation models have shown strong potential in modeling dynamic scenes, generating videos that are both temporally coherent and geometrically consistent across camera views remains a significant challenge. To address this, we propose a 4D video generation model that enforces multi-view 3D consistency of videos by supervising the model with cross-view pointmap alignment during training. This geometric supervision enables the model to learn a shared 3D representation of the scene, allowing it to predict future video sequences from novel viewpoints based solely on the given RGB-D observations, without requiring camera poses as inputs. Compared to existing baselines, our method produces more visually stable and spatially aligned predictions across multiple simulated and real-world robotic datasets. We further show that the predicted 4D videos can be used to recover robot end-effector trajectories using an off-the-shelf 6DoF pose tracker, supporting robust robot manipulation and generalization to novel camera viewpoints.
PolyTouch: A Robust Multi-Modal Tactile Sensor for Contact-rich Manipulation Using Tactile-Diffusion Policies
Apr 27, 2025Achieving robust dexterous manipulation in unstructured domestic environments remains a significant challenge in robotics. Even with state-of-the-art robot learning methods, haptic-oblivious control strategies (i.e. those relying only on external vision and/or proprioception) often fall short due to occlusions, visual complexities, and the need for precise contact interaction control. To address these limitations, we introduce PolyTouch, a novel robot finger that integrates camera-based tactile sensing, acoustic sensing, and peripheral visual sensing into a single design that is compact and durable. PolyTouch provides high-resolution tactile feedback across multiple temporal scales, which is essential for efficiently learning complex manipulation tasks. Experiments demonstrate an at least 20-fold increase in lifespan over commercial tactile sensors, with a design that is both easy to manufacture and scalable. We then use this multi-modal tactile feedback along with visuo-proprioceptive observations to synthesize a tactile-diffusion policy from human demonstrations; the resulting contact-aware control policy significantly outperforms haptic-oblivious policies in multiple contact-aware manipulation policies. This paper highlights how effectively integrating multi-modal contact sensing can hasten the development of effective contact-aware manipulation policies, paving the way for more reliable and versatile domestic robots. More information can be found at https://polytouch.alanz.info/
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
Apr 03, 2025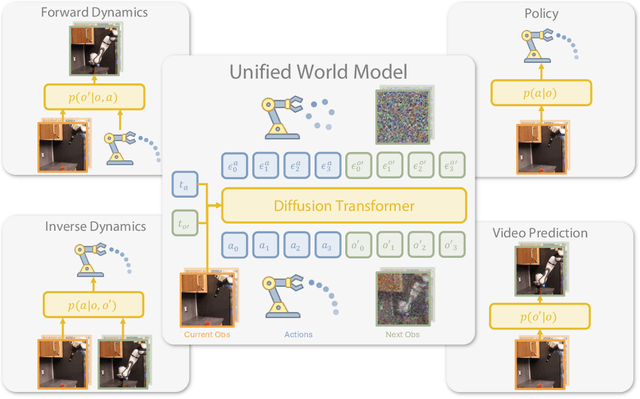
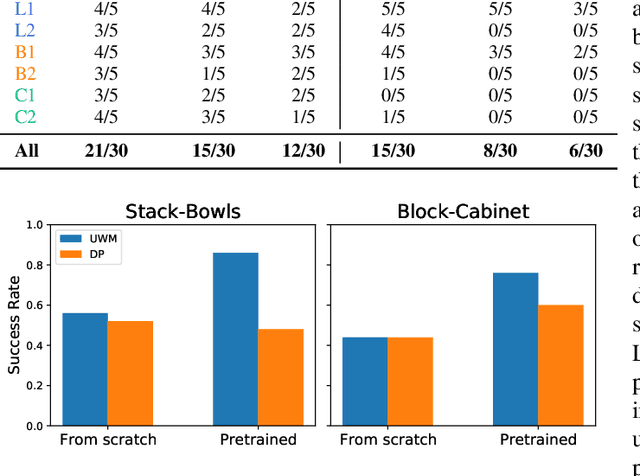


Imitation learning has emerged as a promising approach towards building generalist robots. However, scaling imitation learning for large robot foundation models remains challenging due to its reliance on high-quality expert demonstrations. Meanwhile, large amounts of video data depicting a wide range of environments and diverse behaviors are readily available. This data provides a rich source of information about real-world dynamics and agent-environment interactions. Leveraging this data directly for imitation learning, however, has proven difficult due to the lack of action annotation required for most contemporary methods. In this work, we present Unified World Models (UWM), a framework that allows for leveraging both video and action data for policy learning. Specifically, a UWM integrates an action diffusion process and a video diffusion process within a unified transformer architecture, where independent diffusion timesteps govern each modality. We show that by simply controlling each diffusion timestep, UWM can flexibly represent a policy, a forward dynamics, an inverse dynamics, and a video generator. Through simulated and real-world experiments, we show that: (1) UWM enables effective pretraining on large-scale multitask robot datasets with both dynamics and action predictions, resulting in more generalizable and robust policies than imitation learning, (2) UWM naturally facilitates learning from action-free video data through independent control of modality-specific diffusion timesteps, further improving the performance of finetuned policies. Our results suggest that UWM offers a promising step toward harnessing large, heterogeneous datasets for scalable robot learning, and provides a simple unification between the often disparate paradigms of imitation learning and world modeling. Videos and code are available at https://weirdlabuw.github.io/uwm/.
Should VLMs be Pre-trained with Image Data?
Mar 10, 2025Pre-trained LLMs that are further trained with image data perform well on vision-language tasks. While adding images during a second training phase effectively unlocks this capability, it is unclear how much of a gain or loss this two-step pipeline gives over VLMs which integrate images earlier into the training process. To investigate this, we train models spanning various datasets, scales, image-text ratios, and amount of pre-training done before introducing vision tokens. We then fine-tune these models and evaluate their downstream performance on a suite of vision-language and text-only tasks. We find that pre-training with a mixture of image and text data allows models to perform better on vision-language tasks while maintaining strong performance on text-only evaluations. On an average of 6 diverse tasks, we find that for a 1B model, introducing visual tokens 80% of the way through pre-training results in a 2% average improvement over introducing visual tokens to a fully pre-trained model.
GHIL-Glue: Hierarchical Control with Filtered Subgoal Images
Oct 26, 2024

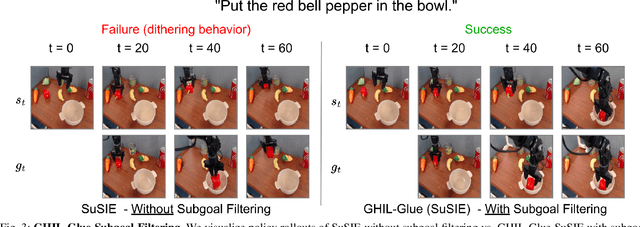

Image and video generative models that are pre-trained on Internet-scale data can greatly increase the generalization capacity of robot learning systems. These models can function as high-level planners, generating intermediate subgoals for low-level goal-conditioned policies to reach. However, the performance of these systems can be greatly bottlenecked by the interface between generative models and low-level controllers. For example, generative models may predict photorealistic yet physically infeasible frames that confuse low-level policies. Low-level policies may also be sensitive to subtle visual artifacts in generated goal images. This paper addresses these two facets of generalization, providing an interface to effectively "glue together" language-conditioned image or video prediction models with low-level goal-conditioned policies. Our method, Generative Hierarchical Imitation Learning-Glue (GHIL-Glue), filters out subgoals that do not lead to task progress and improves the robustness of goal-conditioned policies to generated subgoals with harmful visual artifacts. We find in extensive experiments in both simulated and real environments that GHIL-Glue achieves a 25% improvement across several hierarchical models that leverage generative subgoals, achieving a new state-of-the-art on the CALVIN simulation benchmark for policies using observations from a single RGB camera. GHIL-Glue also outperforms other generalist robot policies across 3/4 language-conditioned manipulation tasks testing zero-shot generalization in physical experiments.
Adaptive Compliance Policy: Learning Approximate Compliance for Diffusion Guided Control
Oct 12, 2024



Compliance plays a crucial role in manipulation, as it balances between the concurrent control of position and force under uncertainties. Yet compliance is often overlooked by today's visuomotor policies that solely focus on position control. This paper introduces Adaptive Compliance Policy (ACP), a novel framework that learns to dynamically adjust system compliance both spatially and temporally for given manipulation tasks from human demonstrations, improving upon previous approaches that rely on pre-selected compliance parameters or assume uniform constant stiffness. However, computing full compliance parameters from human demonstrations is an ill-defined problem. Instead, we estimate an approximate compliance profile with two useful properties: avoiding large contact forces and encouraging accurate tracking. Our approach enables robots to handle complex contact-rich manipulation tasks and achieves over 50\% performance improvement compared to state-of-the-art visuomotor policy methods. For result videos, see https://adaptive-compliance.github.io/
Robot Learning as an Empirical Science: Best Practices for Policy Evaluation
Sep 14, 2024
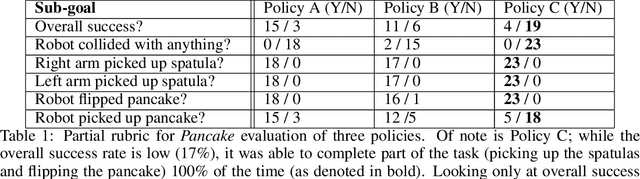

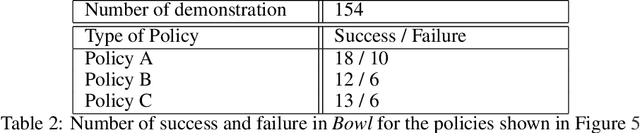
The robot learning community has made great strides in recent years, proposing new architectures and showcasing impressive new capabilities; however, the dominant metric used in the literature, especially for physical experiments, is "success rate", i.e. the percentage of runs that were successful. Furthermore, it is common for papers to report this number with little to no information regarding the number of runs, the initial conditions, and the success criteria, little to no narrative description of the behaviors and failures observed, and little to no statistical analysis of the findings. In this paper we argue that to move the field forward, researchers should provide a nuanced evaluation of their methods, especially when evaluating and comparing learned policies on physical robots. To do so, we propose best practices for future evaluations: explicitly reporting the experimental conditions, evaluating several metrics designed to complement success rate, conducting statistical analysis, and adding a qualitative description of failures modes. We illustrate these through an evaluation on physical robots of several learned policies for manipulation tasks.
Diffusion Policy Policy Optimization
Sep 01, 2024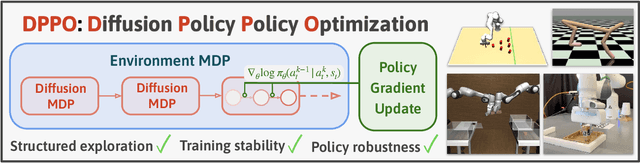

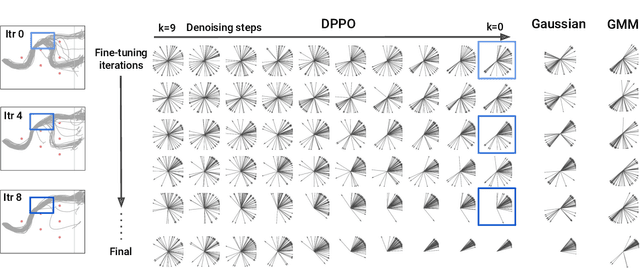
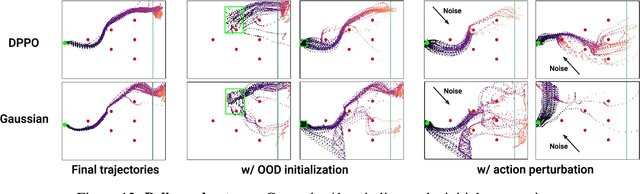
We introduce Diffusion Policy Policy Optimization, DPPO, an algorithmic framework including best practices for fine-tuning diffusion-based policies (e.g. Diffusion Policy) in continuous control and robot learning tasks using the policy gradient (PG) method from reinforcement learning (RL). PG methods are ubiquitous in training RL policies with other policy parameterizations; nevertheless, they had been conjectured to be less efficient for diffusion-based policies. Surprisingly, we show that DPPO achieves the strongest overall performance and efficiency for fine-tuning in common benchmarks compared to other RL methods for diffusion-based policies and also compared to PG fine-tuning of other policy parameterizations. Through experimental investigation, we find that DPPO takes advantage of unique synergies between RL fine-tuning and the diffusion parameterization, leading to structured and on-manifold exploration, stable training, and strong policy robustness. We further demonstrate the strengths of DPPO in a range of realistic settings, including simulated robotic tasks with pixel observations, and via zero-shot deployment of simulation-trained policies on robot hardware in a long-horizon, multi-stage manipulation task. Website with code: diffusion-ppo.github.io
ManiWAV: Learning Robot Manipulation from In-the-Wild Audio-Visual Data
Jun 27, 2024



Audio signals provide rich information for the robot interaction and object properties through contact. These information can surprisingly ease the learning of contact-rich robot manipulation skills, especially when the visual information alone is ambiguous or incomplete. However, the usage of audio data in robot manipulation has been constrained to teleoperated demonstrations collected by either attaching a microphone to the robot or object, which significantly limits its usage in robot learning pipelines. In this work, we introduce ManiWAV: an 'ear-in-hand' data collection device to collect in-the-wild human demonstrations with synchronous audio and visual feedback, and a corresponding policy interface to learn robot manipulation policy directly from the demonstrations. We demonstrate the capabilities of our system through four contact-rich manipulation tasks that require either passively sensing the contact events and modes, or actively sensing the object surface materials and states. In addition, we show that our system can generalize to unseen in-the-wild environments, by learning from diverse in-the-wild human demonstrations. Project website: https://mani-wav.github.io/
OpenVLA: An Open-Source Vision-Language-Action Model
Jun 13, 2024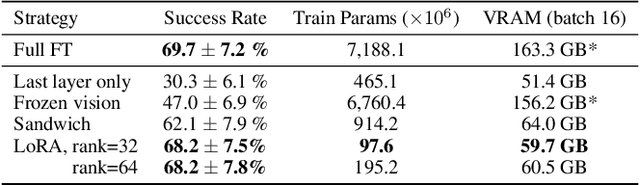
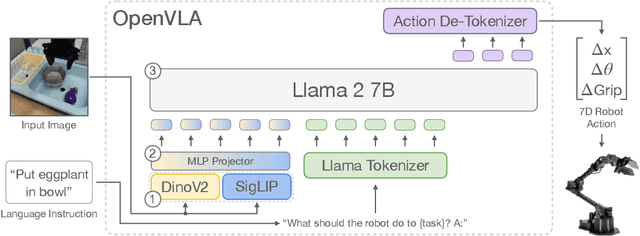
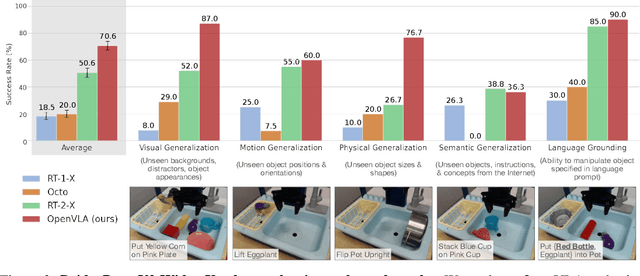
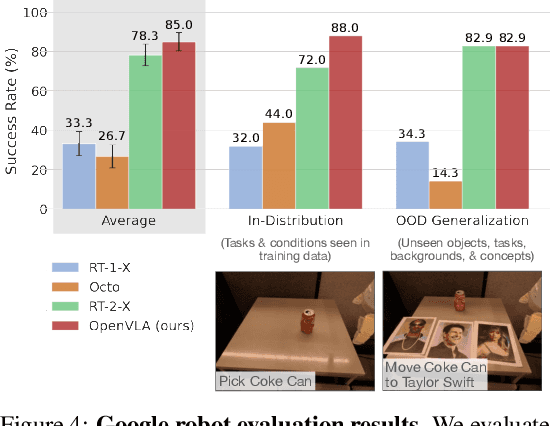
Large policies pretrained on a combination of Internet-scale vision-language data and diverse robot demonstrations have the potential to change how we teach robots new skills: rather than training new behaviors from scratch, we can fine-tune such vision-language-action (VLA) models to obtain robust, generalizable policies for visuomotor control. Yet, widespread adoption of VLAs for robotics has been challenging as 1) existing VLAs are largely closed and inaccessible to the public, and 2) prior work fails to explore methods for efficiently fine-tuning VLAs for new tasks, a key component for adoption. Addressing these challenges, we introduce OpenVLA, a 7B-parameter open-source VLA trained on a diverse collection of 970k real-world robot demonstrations. OpenVLA builds on a Llama 2 language model combined with a visual encoder that fuses pretrained features from DINOv2 and SigLIP. As a product of the added data diversity and new model components, OpenVLA demonstrates strong results for generalist manipulation, outperforming closed models such as RT-2-X (55B) by 16.5% in absolute task success rate across 29 tasks and multiple robot embodiments, with 7x fewer parameters. We further show that we can effectively fine-tune OpenVLA for new settings, with especially strong generalization results in multi-task environments involving multiple objects and strong language grounding abilities, and outperform expressive from-scratch imitation learning methods such as Diffusion Policy by 20.4%. We also explore compute efficiency; as a separate contribution, we show that OpenVLA can be fine-tuned on consumer GPUs via modern low-rank adaptation methods and served efficiently via quantization without a hit to downstream success rate. Finally, we release model checkpoints, fine-tuning notebooks, and our PyTorch codebase with built-in support for training VLAs at scale on Open X-Embodiment datasets.