 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Demo is Worth a Thousand Trajectories: Action-View Augmentation for Visuomotor Policies
Jun 17, 2026Visuomotor policies for manipulation have demonstrated remarkable potential in modeling complex robotic behaviors, yet minor alterations in the robot's initial configuration and unseen obstacles easily lead to out-of-distribution observations. Without extensive data collection effort, these result in catastrophic execution failures. In this work, we introduce an effective data augmentation framework that generates visually realistic fisheye image sequences and corresponding physically feasible action trajectories from real-world eye-in-hand demonstrations, captured with a portable parallel gripper with a single fisheye camera. We introduce a novel Gaussian Splatting formulation, adapted to wide FoV fisheye cameras, to reconstruct and edit the 3D scene with unseen objects. We utilize trajectory optimization to generate smooth, collision-free, view-rendering-friendly action trajectories and render visual observations from corresponding novel views. Comprehensive experiments in simulation and the real world show that our augmentation framework improves the success rate for various manipulation tasks in both the same scene and the augmented scene with obstacles requiring collision avoidance.
* Project website: https://chuerpan.com/1001-demos.github.io/. Published at CoRL 2025
In-the-Wild Compliant Manipulation with UMI-FT
Jan 15, 2026Many manipulation tasks require careful force modulation. With insufficient force the task may fail, while excessive force could cause damage. The high cost, bulky size and fragility of commercial force/torque (F/T) sensors have limited large-scale, force-aware policy learning. We introduce UMI-FT, a handheld data-collection platform that mounts compact, six-axis force/torque sensors on each finger, enabling finger-level wrench measurements alongside RGB, depth, and pose. Using the multimodal data collected from this device, we train an adaptive compliance policy that predicts position targets, grasp force, and stiffness for execution on standard compliance controllers. In evaluations on three contact-rich, force-sensitive tasks (whiteboard wiping, skewering zucchini, and lightbulb insertion), UMI-FT enables policies that reliably regulate external contact forces and internal grasp forces, outperforming baselines that lack compliance or force sensing. UMI-FT offers a scalable path to learning compliant manipulation from in-the-wild demonstrations. We open-source the hardware and software to facilitate broader adoption at:https://umi-ft.github.io/.
A Study of Perceived Safety for Soft Robotics in Caregiving Tasks
Mar 26, 2025

In this project, we focus on human-robot interaction in caregiving scenarios like bathing, where physical contact is inevitable and necessary for proper task execution because force must be applied to the skin. Using finite element analysis, we designed a 3D-printed gripper combining positive and negative pressure for secure yet compliant handling. Preliminary tests showed it exerted a lower, more uniform pressure profile than a standard rigid gripper. In a user study, participants' trust in robots significantly increased after they experienced a brief bathing demonstration performed by a robotic arm equipped with the soft gripper. These results suggest that soft robotics can enhance perceived safety and acceptance in intimate caregiving scenarios.
Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots
Feb 19, 2024



We present Universal Manipulation Interface (UMI) -- a data collection and policy learning framework that allows direct skill transfer from in-the-wild human demonstrations to deployable robot policies. UMI employs hand-held grippers coupled with careful interface design to enable portable, low-cost, and information-rich data collection for challenging bimanual and dynamic manipulation demonstrations. To facilitate deployable policy learning, UMI incorporates a carefully designed policy interface with inference-time latency matching and a relative-trajectory action representation. The resulting learned policies are hardware-agnostic and deployable across multiple robot platforms. Equipped with these features, UMI framework unlocks new robot manipulation capabilities, allowing zero-shot generalizable dynamic, bimanual, precise, and long-horizon behaviors, by only changing the training data for each task. We demonstrate UMI's versatility and efficacy with comprehensive real-world experiments, where policies learned via UMI zero-shot generalize to novel environments and objects when trained on diverse human demonstrations. UMI's hardware and software system is open-sourced at https://umi-gripper.github.io.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Deep Projective Rotation Estimation through Relative Supervision
Nov 21, 2022Orientation estimation is the core to a variety of vision and robotics tasks such as camera and object pose estimation. Deep learning has offered a way to develop image-based orientation estimators; however, such estimators often require training on a large labeled dataset, which can be time-intensive to collect. In this work, we explore whether self-supervised learning from unlabeled data can be used to alleviate this issue. Specifically, we assume access to estimates of the relative orientation between neighboring poses, such that can be obtained via a local alignment method. While self-supervised learning has been used successfully for translational object keypoints, in this work, we show that naively applying relative supervision to the rotational group $SO(3)$ will often fail to converge due to the non-convexity of the rotational space. To tackle this challenge, we propose a new algorithm for self-supervised orientation estimation which utilizes Modified Rodrigues Parameters to stereographically project the closed manifold of $SO(3)$ to the open manifold of $\mathbb{R}^{3}$, allowing the optimization to be done in an open Euclidean space. We empirically validate the benefits of the proposed algorithm for rotational averaging problem in two settings: (1) direct optimization on rotation parameters, and (2) optimization of parameters of a convolutional neural network that predicts object orientations from images. In both settings, we demonstrate that our proposed algorithm is able to converge to a consistent relative orientation frame much faster than algorithms that purely operate in the $SO(3)$ space. Additional information can be found at https://sites.google.com/view/deep-projective-rotation/home .
TAX-Pose: Task-Specific Cross-Pose Estimation for Robot Manipulation
Nov 17, 2022



How do we imbue robots with the ability to efficiently manipulate unseen objects and transfer relevant skills based on demonstrations? End-to-end learning methods often fail to generalize to novel objects or unseen configurations. Instead, we focus on the task-specific pose relationship between relevant parts of interacting objects. We conjecture that this relationship is a generalizable notion of a manipulation task that can transfer to new objects in the same category; examples include the relationship between the pose of a pan relative to an oven or the pose of a mug relative to a mug rack. We call this task-specific pose relationship ``cross-pose" and provide a mathematical definition of this concept. We propose a vision-based system that learns to estimate the cross-pose between two objects for a given manipulation task using learned cross-object correspondences. The estimated cross-pose is then used to guide a downstream motion planner to manipulate the objects into the desired pose relationship (placing a pan into the oven or the mug onto the mug rack). We demonstrate our method's capability to generalize to unseen objects, in some cases after training on only 10 demonstrations in the real world. Results show that our system achieves state-of-the-art performance in both simulated and real-world experiments across a number of tasks. Supplementary information and videos can be found at https://sites.google.com/view/tax-pose/home.
Examining the rhetorical capacities of neural language models
Oct 04, 2020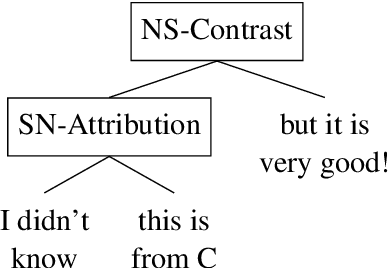
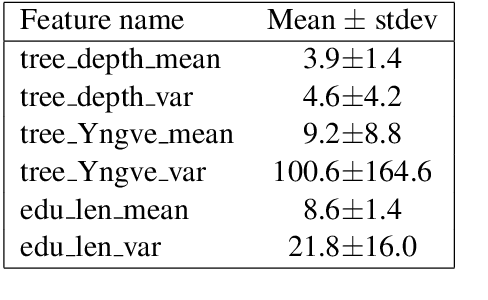
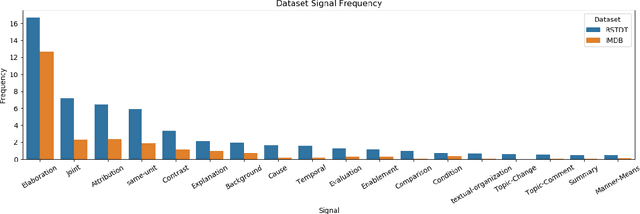
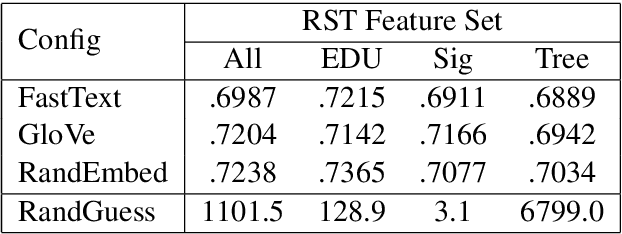
Recently, neural language models (LMs) have demonstrated impressive abilities in generating high-quality discourse. While many recent papers have analyzed the syntactic aspects encoded in LMs, there has been no analysis to date of the inter-sentential, rhetorical knowledge. In this paper, we propose a method that quantitatively evaluates the rhetorical capacities of neural LMs. We examine the capacities of neural LMs understanding the rhetoric of discourse by evaluating their abilities to encode a set of linguistic features derived from Rhetorical Structure Theory (RST). Our experiments show that BERT-based LMs outperform other Transformer LMs, revealing the richer discourse knowledge in their intermediate layer representations. In addition, GPT-2 and XLNet apparently encode less rhetorical knowledge, and we suggest an explanation drawing from linguistic philosophy. Our method shows an avenue towards quantifying the rhetorical capacities of neural LMs.