 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoMMI: Learning Whole-Body Mobile Manipulation from Human Demonstrations
Mar 03, 2026We present Whole-Body Mobile Manipulation Interface (HoMMI), a data collection and policy learning framework that learns whole-body mobile manipulation directly from robot-free human demonstrations. We augment UMI interfaces with egocentric sensing to capture the global context required for mobile manipulation, enabling portable, robot-free, and scalable data collection. However, naively incorporating egocentric sensing introduces a larger human-to-robot embodiment gap in both observation and action spaces, making policy transfer difficult. We explicitly bridge this gap with a cross-embodiment hand-eye policy design, including an embodiment agnostic visual representation; a relaxed head action representation; and a whole-body controller that realizes hand-eye trajectories through coordinated whole-body motion under robot-specific physical constraints. Together, these enable long-horizon mobile manipulation tasks requiring bimanual and whole-body coordination, navigation, and active perception. Results are best viewed on: https://hommi-robot.github.io
Geometry-aware 4D Video Generation for Robot Manipulation
Jul 01, 2025Understanding and predicting the dynamics of the physical world can enhance a robot's ability to plan and interact effectively in complex environments. While recent video generation models have shown strong potential in modeling dynamic scenes, generating videos that are both temporally coherent and geometrically consistent across camera views remains a significant challenge. To address this, we propose a 4D video generation model that enforces multi-view 3D consistency of videos by supervising the model with cross-view pointmap alignment during training. This geometric supervision enables the model to learn a shared 3D representation of the scene, allowing it to predict future video sequences from novel viewpoints based solely on the given RGB-D observations, without requiring camera poses as inputs. Compared to existing baselines, our method produces more visually stable and spatially aligned predictions across multiple simulated and real-world robotic datasets. We further show that the predicted 4D videos can be used to recover robot end-effector trajectories using an off-the-shelf 6DoF pose tracker, supporting robust robot manipulation and generalization to novel camera viewpoints.
Adaptive Compliance Policy: Learning Approximate Compliance for Diffusion Guided Control
Oct 12, 2024



Compliance plays a crucial role in manipulation, as it balances between the concurrent control of position and force under uncertainties. Yet compliance is often overlooked by today's visuomotor policies that solely focus on position control. This paper introduces Adaptive Compliance Policy (ACP), a novel framework that learns to dynamically adjust system compliance both spatially and temporally for given manipulation tasks from human demonstrations, improving upon previous approaches that rely on pre-selected compliance parameters or assume uniform constant stiffness. However, computing full compliance parameters from human demonstrations is an ill-defined problem. Instead, we estimate an approximate compliance profile with two useful properties: avoiding large contact forces and encouraging accurate tracking. Our approach enables robots to handle complex contact-rich manipulation tasks and achieves over 50\% performance improvement compared to state-of-the-art visuomotor policy methods. For result videos, see https://adaptive-compliance.github.io/
Vegetable Peeling: A Case Study in Constrained Dexterous Manipulation
Jul 10, 2024


Recent studies have made significant progress in addressing dexterous manipulation problems, particularly in in-hand object reorientation. However, there are few existing works that explore the potential utilization of developed dexterous manipulation controllers for downstream tasks. In this study, we focus on constrained dexterous manipulation for food peeling. Food peeling presents various constraints on the reorientation controller, such as the requirement for the hand to securely hold the object after reorientation for peeling. We propose a simple system for learning a reorientation controller that facilitates the subsequent peeling task. Videos are available at: https://taochenshh.github.io/projects/veg-peeling.
ManiWAV: Learning Robot Manipulation from In-the-Wild Audio-Visual Data
Jun 27, 2024



Audio signals provide rich information for the robot interaction and object properties through contact. These information can surprisingly ease the learning of contact-rich robot manipulation skills, especially when the visual information alone is ambiguous or incomplete. However, the usage of audio data in robot manipulation has been constrained to teleoperated demonstrations collected by either attaching a microphone to the robot or object, which significantly limits its usage in robot learning pipelines. In this work, we introduce ManiWAV: an 'ear-in-hand' data collection device to collect in-the-wild human demonstrations with synchronous audio and visual feedback, and a corresponding policy interface to learn robot manipulation policy directly from the demonstrations. We demonstrate the capabilities of our system through four contact-rich manipulation tasks that require either passively sensing the contact events and modes, or actively sensing the object surface materials and states. In addition, we show that our system can generalize to unseen in-the-wild environments, by learning from diverse in-the-wild human demonstrations. Project website: https://mani-wav.github.io/
Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots
Feb 19, 2024



We present Universal Manipulation Interface (UMI) -- a data collection and policy learning framework that allows direct skill transfer from in-the-wild human demonstrations to deployable robot policies. UMI employs hand-held grippers coupled with careful interface design to enable portable, low-cost, and information-rich data collection for challenging bimanual and dynamic manipulation demonstrations. To facilitate deployable policy learning, UMI incorporates a carefully designed policy interface with inference-time latency matching and a relative-trajectory action representation. The resulting learned policies are hardware-agnostic and deployable across multiple robot platforms. Equipped with these features, UMI framework unlocks new robot manipulation capabilities, allowing zero-shot generalizable dynamic, bimanual, precise, and long-horizon behaviors, by only changing the training data for each task. We demonstrate UMI's versatility and efficacy with comprehensive real-world experiments, where policies learned via UMI zero-shot generalize to novel environments and objects when trained on diverse human demonstrations. UMI's hardware and software system is open-sourced at https://umi-gripper.github.io.
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Mar 10, 2023This paper introduces Diffusion Policy, a new way of generating robot behavior by representing a robot's visuomotor policy as a conditional denoising diffusion process. We benchmark Diffusion Policy across 11 different tasks from 4 different robot manipulation benchmarks and find that it consistently outperforms existing state-of-the-art robot learning methods with an average improvement of 46.9%. Diffusion Policy learns the gradient of the action-distribution score function and iteratively optimizes with respect to this gradient field during inference via a series of stochastic Langevin dynamics steps. We find that the diffusion formulation yields powerful advantages when used for robot policies, including gracefully handling multimodal action distributions, being suitable for high-dimensional action spaces, and exhibiting impressive training stability. To fully unlock the potential of diffusion models for visuomotor policy learning on physical robots, this paper presents a set of key technical contributions including the incorporation of receding horizon control, visual conditioning, and the time-series diffusion transformer. We hope this work will help motivate a new generation of policy learning techniques that are able to leverage the powerful generative modeling capabilities of diffusion models. Code, data, and training details will be publicly available.
Bag All You Need: Learning a Generalizable Bagging Strategy for Heterogeneous Objects
Oct 18, 2022
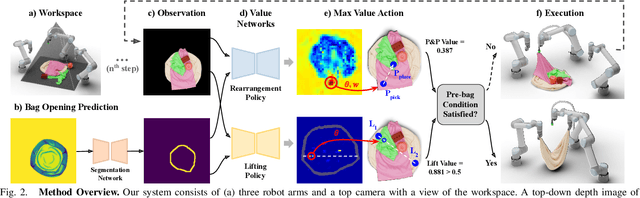
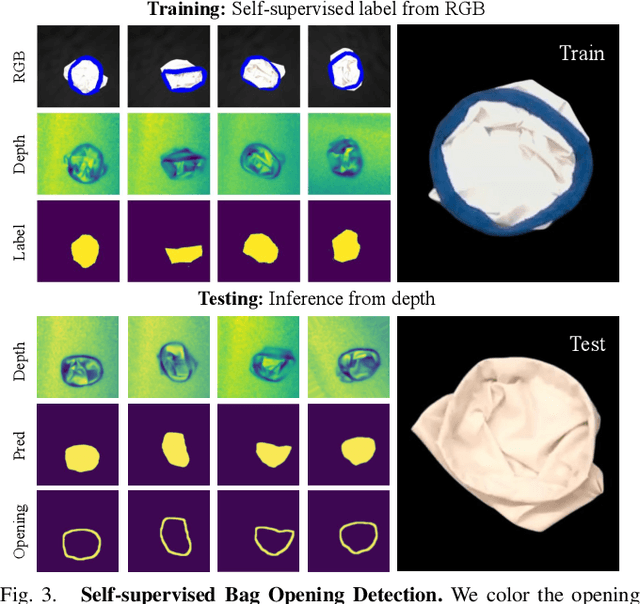
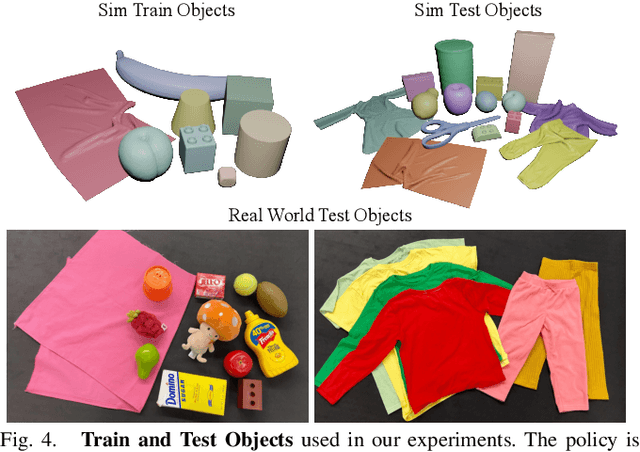
We introduce a practical robotics solution for the task of heterogeneous bagging, requiring the placement of multiple rigid and deformable objects into a deformable bag. This is a difficult task as it features complex interactions between multiple highly deformable objects under limited observability. To tackle these challenges, we propose a robotic system consisting of two learned policies: a rearrangement policy that learns to place multiple rigid objects and fold deformable objects in order to achieve desirable pre-bagging conditions, and a lifting policy to infer suitable grasp points for bi-manual bag lifting. We evaluate these learned policies on a real-world three-arm robot platform that achieves a 70% heterogeneous bagging success rate with novel objects. To facilitate future research and comparison, we also develop a novel heterogeneous bagging simulation benchmark that will be made publicly available.
Cloth Funnels: Canonicalized-Alignment for Multi-Purpose Garment Manipulation
Oct 17, 2022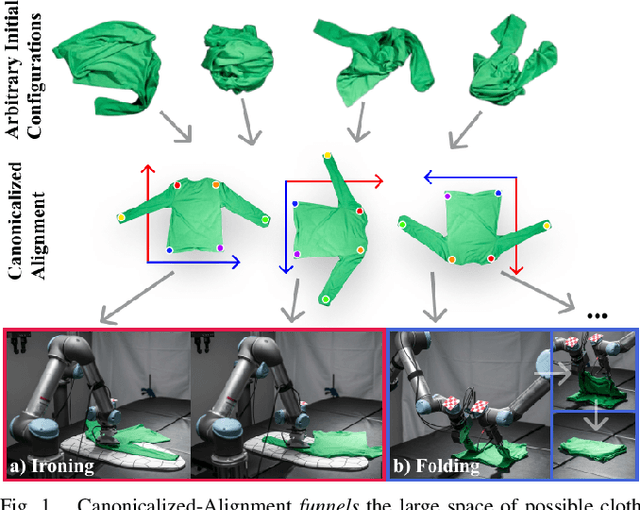
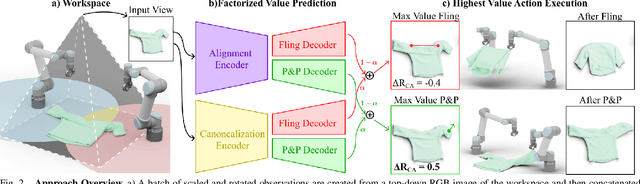
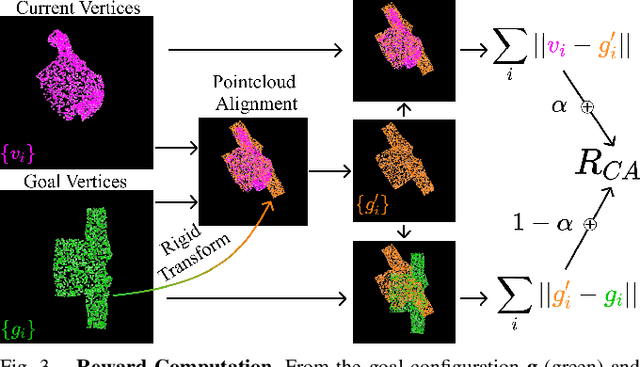
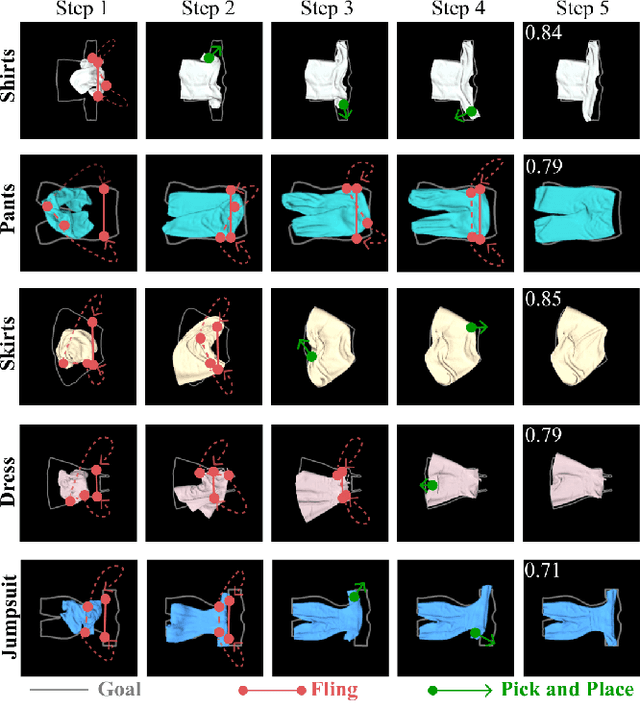
Automating garment manipulation is challenging due to extremely high variability in object configurations. To reduce this intrinsic variation, we introduce the task of "canonicalized-alignment" that simplifies downstream applications by reducing the possible garment configurations. This task can be considered as "cloth state funnel" that manipulates arbitrarily configured clothing items into a predefined deformable configuration (i.e. canonicalization) at an appropriate rigid pose (i.e. alignment). In the end, the cloth items will result in a compact set of structured and highly visible configurations - which are desirable for downstream manipulation skills. To enable this task, we propose a novel canonicalized-alignment objective that effectively guides learning to avoid adverse local minima during learning. Using this objective, we learn a multi-arm, multi-primitive policy that strategically chooses between dynamic flings and quasi-static pick and place actions to achieve efficient canonicalized-alignment. We evaluate this approach on a real-world ironing and folding system that relies on this learned policy as the common first step. Empirically, we demonstrate that our task-agnostic canonicalized-alignment can enable even simple manually-designed policies to work well where they were previously inadequate, thus bridging the gap between automated non-deformable manufacturing and deformable manipulation. Code and qualitative visualizations are available at https://clothfunnels.cs.columbia.edu/. Video can be found at https://www.youtube.com/watch?v=TkUn0b7mbj0.
Conditional Energy-Based Models for Implicit Policies: The Gap between Theory and Practice
Jul 12, 2022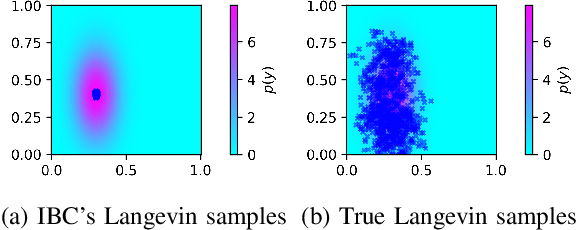
We present our findings in the gap between theory and practice of using conditional energy-based models (EBM) as an implicit representation for behavior-cloned policies. We also clarify several subtle, and potentially confusing, details in previous work in an attempt to help future research in this area. We point out key differences between unconditional and conditional EBMs, and warn that blindly applying training methods for one to the other could lead to undesirable results that do not generalize well. Finally, we emphasize the importance of the Maximum Mutual Information principle as a necessary condition to achieve good generalization in conditional EBMs as implicit models for regression tasks.