 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoVerse: An Egocentric Human Dataset for Robot Learning from Around the World
Apr 08, 2026Robot learning increasingly depends on large and diverse data, yet robot data collection remains expensive and difficult to scale. Egocentric human data offer a promising alternative by capturing rich manipulation behavior across everyday environments. However, existing human datasets are often limited in scope, difficult to extend, and fragmented across institutions. We introduce EgoVerse, a collaborative platform for human data-driven robot learning that unifies data collection, processing, and access under a shared framework, enabling contributions from individual researchers, academic labs, and industry partners. The current release includes 1,362 hours (80k episodes) of human demonstrations spanning 1,965 tasks, 240 scenes, and 2,087 unique demonstrators, with standardized formats, manipulation-relevant annotations, and tooling for downstream learning. Beyond the dataset, we conduct a large-scale study of human-to-robot transfer with experiments replicated across multiple labs, tasks, and robot embodiments under shared protocols. We find that policy performance generally improves with increased human data, but that effective scaling depends on alignment between human data and robot learning objectives. Together, the dataset, platform, and study establish a foundation for reproducible progress in human data-driven robot learning. Videos and additional information can be found at https://egoverse.ai/
InspecSafe-V1: A Multimodal Benchmark for Safety Assessment in Industrial Inspection Scenarios
Jan 29, 2026With the rapid development of industrial intelligence and unmanned inspection, reliable perception and safety assessment for AI systems in complex and dynamic industrial sites has become a key bottleneck for deploying predictive maintenance and autonomous inspection. Most public datasets remain limited by simulated data sources, single-modality sensing, or the absence of fine-grained object-level annotations, which prevents robust scene understanding and multimodal safety reasoning for industrial foundation models. To address these limitations, InspecSafe-V1 is released as the first multimodal benchmark dataset for industrial inspection safety assessment that is collected from routine operations of real inspection robots in real-world environments. InspecSafe-V1 covers five representative industrial scenarios, including tunnels, power facilities, sintering equipment, oil and gas petrochemical plants, and coal conveyor trestles. The dataset is constructed from 41 wheeled and rail-mounted inspection robots operating at 2,239 valid inspection sites, yielding 5,013 inspection instances. For each instance, pixel-level segmentation annotations are provided for key objects in visible-spectrum images. In addition, a semantic scene description and a corresponding safety level label are provided according to practical inspection tasks. Seven synchronized sensing modalities are further included, including infrared video, audio, depth point clouds, radar point clouds, gas measurements, temperature, and humidity, to support multimodal anomaly recognition, cross-modal fusion, and comprehensive safety assessment in industrial environments.
VLSA: Vision-Language-Action Models with Plug-and-Play Safety Constraint Layer
Dec 09, 2025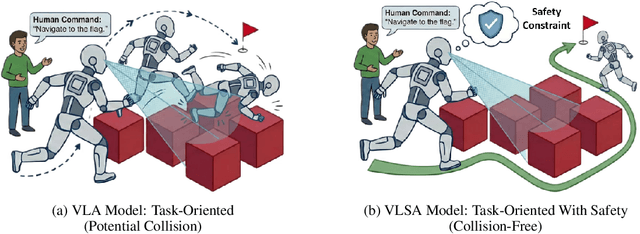
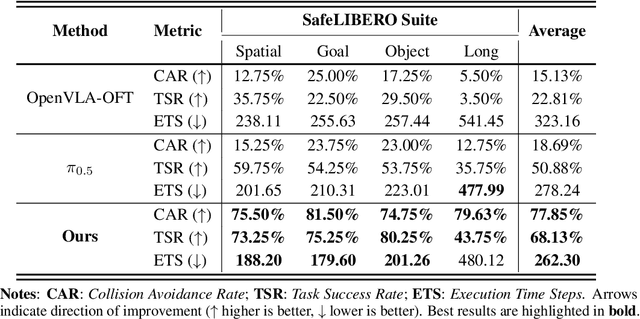
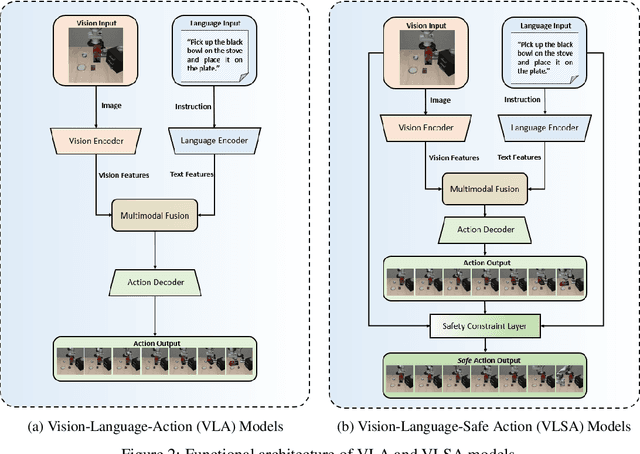
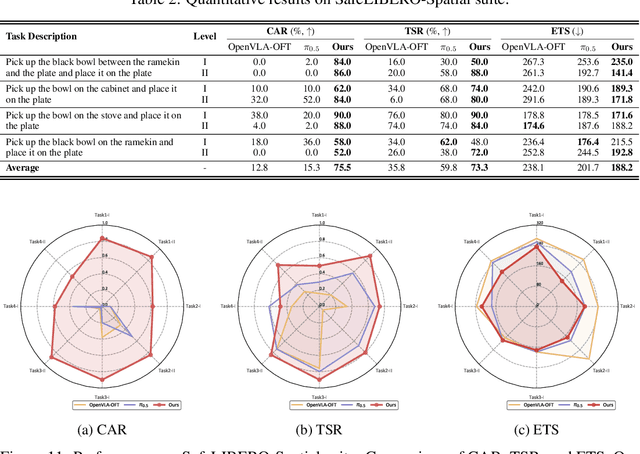
Vision-Language-Action (VLA) models have demonstrated remarkable capabilities in generalizing across diverse robotic manipulation tasks. However, deploying these models in unstructured environments remains challenging due to the critical need for simultaneous task compliance and safety assurance, particularly in preventing potential collisions during physical interactions. In this work, we introduce a Vision-Language-Safe Action (VLSA) architecture, named AEGIS, which contains a plug-and-play safety constraint (SC) layer formulated via control barrier functions. AEGIS integrates directly with existing VLA models to improve safety with theoretical guarantees, while maintaining their original instruction-following performance. To evaluate the efficacy of our architecture, we construct a comprehensive safety-critical benchmark SafeLIBERO, spanning distinct manipulation scenarios characterized by varying degrees of spatial complexity and obstacle intervention. Extensive experiments demonstrate the superiority of our method over state-of-the-art baselines. Notably, AEGIS achieves a 59.16% improvement in obstacle avoidance rate while substantially increasing the task execution success rate by 17.25%. To facilitate reproducibility and future research, we make our code, models, and the benchmark datasets publicly available at https://vlsa-aegis.github.io/.
Awesome-OL: An Extensible Toolkit for Online Learning
Jul 27, 2025In recent years, online learning has attracted increasing attention due to its adaptive capability to process streaming and non-stationary data. To facilitate algorithm development and practical deployment in this area, we introduce Awesome-OL, an extensible Python toolkit tailored for online learning research. Awesome-OL integrates state-of-the-art algorithm, which provides a unified framework for reproducible comparisons, curated benchmark datasets, and multi-modal visualization. Built upon the scikit-multiflow open-source infrastructure, Awesome-OL emphasizes user-friendly interactions without compromising research flexibility or extensibility. The source code is publicly available at: https://github.com/liuzy0708/Awesome-OL.
Geometry-aware 4D Video Generation for Robot Manipulation
Jul 01, 2025Understanding and predicting the dynamics of the physical world can enhance a robot's ability to plan and interact effectively in complex environments. While recent video generation models have shown strong potential in modeling dynamic scenes, generating videos that are both temporally coherent and geometrically consistent across camera views remains a significant challenge. To address this, we propose a 4D video generation model that enforces multi-view 3D consistency of videos by supervising the model with cross-view pointmap alignment during training. This geometric supervision enables the model to learn a shared 3D representation of the scene, allowing it to predict future video sequences from novel viewpoints based solely on the given RGB-D observations, without requiring camera poses as inputs. Compared to existing baselines, our method produces more visually stable and spatially aligned predictions across multiple simulated and real-world robotic datasets. We further show that the predicted 4D videos can be used to recover robot end-effector trajectories using an off-the-shelf 6DoF pose tracker, supporting robust robot manipulation and generalization to novel camera viewpoints.
Lite-RVFL: A Lightweight Random Vector Functional-Link Neural Network for Learning Under Concept Drift
Jun 09, 2025The change in data distribution over time, also known as concept drift, poses a significant challenge to the reliability of online learning methods. Existing methods typically require model retraining or drift detection, both of which demand high computational costs and are often unsuitable for real-time applications. To address these limitations, a lightweight, fast and efficient random vector functional-link network termed Lite-RVFL is proposed, capable of adapting to concept drift without drift detection and retraining. Lite-RVFL introduces a novel objective function that assigns weights exponentially increasing to new samples, thereby emphasizing recent data and enabling timely adaptation. Theoretical analysis confirms the feasibility of this objective function for drift adaptation, and an efficient incremental update rule is derived. Experimental results on a real-world safety assessment task validate the efficiency, effectiveness in adapting to drift, and potential to capture temporal patterns of Lite-RVFL. The source code is available at https://github.com/songqiaohu/Lite-RVFL.
Performance-bounded Online Ensemble Learning Method Based on Multi-armed bandits and Its Applications in Real-time Safety Assessment
Mar 19, 2025Ensemble learning plays a crucial role in practical applications of online learning due to its enhanced classification performance and adaptable adjustment mechanisms. However, most weight allocation strategies in ensemble learning are heuristic, making it challenging to theoretically guarantee that the ensemble classifier outperforms its base classifiers. To address this issue, a performance-bounded online ensemble learning method based on multi-armed bandits, named PB-OEL, is proposed in this paper. Specifically, multi-armed bandit with expert advice is incorporated into online ensemble learning, aiming to update the weights of base classifiers and make predictions. A theoretical framework is established to bound the performance of the ensemble classifier relative to base classifiers. By setting expert advice of bandits, the bound exceeds the performance of any base classifier when the length of data stream is sufficiently large. Additionally, performance bounds for scenarios with limited annotations are also derived. Numerous experiments on benchmark datasets and a dataset of real-time safety assessment tasks are conducted. The experimental results validate the theoretical bound to a certain extent and demonstrate that the proposed method outperforms existing state-of-the-art methods.
CoIn-SafeLink: Safety-critical Control With Cost-sensitive Incremental Random Vector Functional Link Network
Mar 19, 2025



Control barrier functions (CBFs) play a crucial role in achieving the safety-critical control of robotic systems theoretically. However, most existing methods rely on the analytical expressions of unsafe state regions, which is often impractical for irregular and dynamic unsafe regions. In this paper, a novel CBF construction approach, called CoIn-SafeLink, is proposed based on cost-sensitive incremental random vector functional-link (RVFL) neural networks. By designing an appropriate cost function, CoIn-SafeLink achieves differentiated sensitivities to safe and unsafe samples, effectively achieving zero false-negative risk in unsafe sample classification. Additionally, an incremental update theorem for CoIn-SafeLink is proposed, enabling precise adjustments in response to changes in the unsafe region. Finally, the gradient analytical expression of the CoIn-SafeLink is provided to calculate the control input. The proposed method is validated on a 3-degree-of-freedom drone attitude control system. Experimental results demonstrate that the method can effectively learn the unsafe region boundaries and rapidly adapt as these regions evolve, with an update speed approximately five times faster than comparison methods. The source code is available at https://github.com/songqiaohu/CoIn-SafeLink.
Sailor2: Sailing in South-East Asia with Inclusive Multilingual LLMs
Feb 18, 2025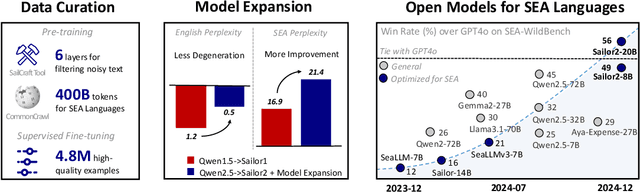
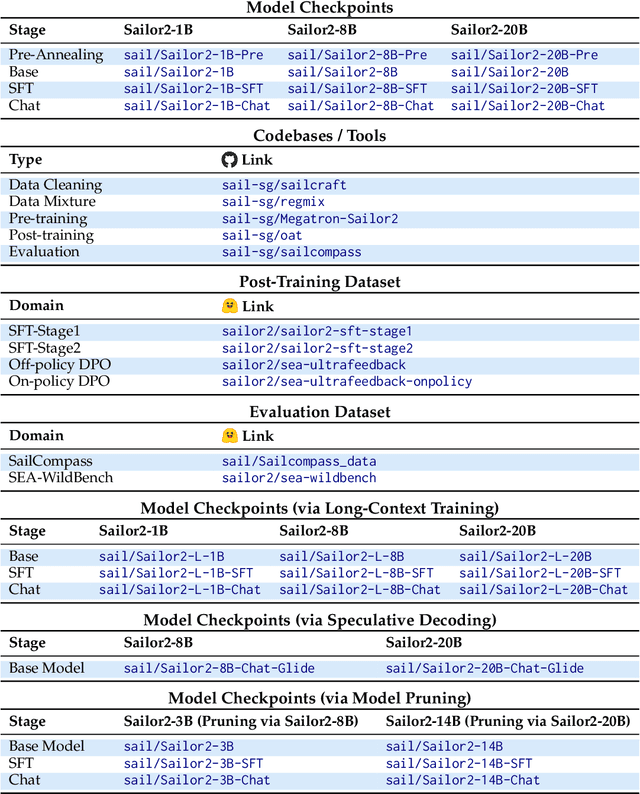

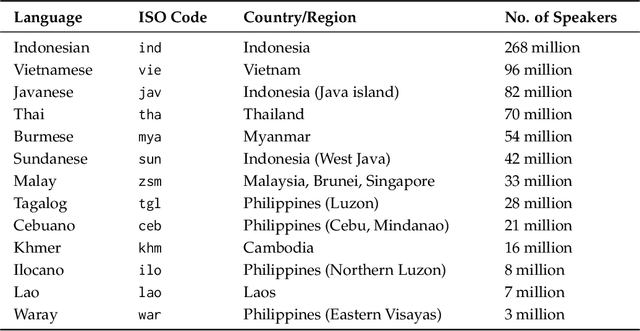
Sailor2 is a family of cutting-edge multilingual language models for South-East Asian (SEA) languages, available in 1B, 8B, and 20B sizes to suit diverse applications. Building on Qwen2.5, Sailor2 undergoes continuous pre-training on 500B tokens (400B SEA-specific and 100B replay tokens) to support 13 SEA languages while retaining proficiency in Chinese and English. Sailor2-20B model achieves a 50-50 win rate against GPT-4o across SEA languages. We also deliver a comprehensive cookbook on how to develop the multilingual model in an efficient manner, including five key aspects: data curation, pre-training, post-training, model customization and evaluation. We hope that Sailor2 model (Apache 2.0 license) will drive language development in the SEA region, and Sailor2 cookbook will inspire researchers to build more inclusive LLMs for other under-served languages.
Adaptive Compliance Policy: Learning Approximate Compliance for Diffusion Guided Control
Oct 12, 2024



Compliance plays a crucial role in manipulation, as it balances between the concurrent control of position and force under uncertainties. Yet compliance is often overlooked by today's visuomotor policies that solely focus on position control. This paper introduces Adaptive Compliance Policy (ACP), a novel framework that learns to dynamically adjust system compliance both spatially and temporally for given manipulation tasks from human demonstrations, improving upon previous approaches that rely on pre-selected compliance parameters or assume uniform constant stiffness. However, computing full compliance parameters from human demonstrations is an ill-defined problem. Instead, we estimate an approximate compliance profile with two useful properties: avoiding large contact forces and encouraging accurate tracking. Our approach enables robots to handle complex contact-rich manipulation tasks and achieves over 50\% performance improvement compared to state-of-the-art visuomotor policy methods. For result videos, see https://adaptive-compliance.github.io/