 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan-Animate: Unified Character Animation and Replacement with Holistic Replication
Sep 17, 2025

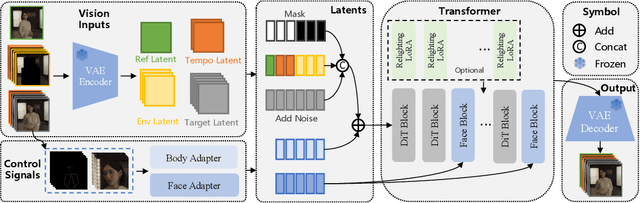
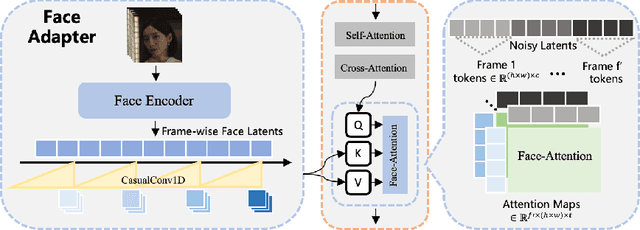
We introduce Wan-Animate, a unified framework for character animation and replacement. Given a character image and a reference video, Wan-Animate can animate the character by precisely replicating the expressions and movements of the character in the video to generate high-fidelity character videos. Alternatively, it can integrate the animated character into the reference video to replace the original character, replicating the scene's lighting and color tone to achieve seamless environmental integration. Wan-Animate is built upon the Wan model. To adapt it for character animation tasks, we employ a modified input paradigm to differentiate between reference conditions and regions for generation. This design unifies multiple tasks into a common symbolic representation. We use spatially-aligned skeleton signals to replicate body motion and implicit facial features extracted from source images to reenact expressions, enabling the generation of character videos with high controllability and expressiveness. Furthermore, to enhance environmental integration during character replacement, we develop an auxiliary Relighting LoRA. This module preserves the character's appearance consistency while applying the appropriate environmental lighting and color tone. Experimental results demonstrate that Wan-Animate achieves state-of-the-art performance. We are committed to open-sourcing the model weights and its source code.
Feasibility-Aware Pessimistic Estimation: Toward Long-Horizon Safety in Offline RL
May 13, 2025Offline safe reinforcement learning(OSRL) derives constraint-satisfying policies from pre-collected datasets, offers a promising avenue for deploying RL in safety-critical real-world domains such as robotics. However, the majority of existing approaches emphasize only short-term safety, neglecting long-horizon considerations. Consequently, they may violate safety constraints and fail to ensure sustained protection during online deployment. Moreover, the learned policies often struggle to handle states and actions that are not present or out-of-distribution(OOD) from the offline dataset, and exhibit limited sample efficiency. To address these challenges, we propose a novel framework Feasibility-Aware offline Safe Reinforcement Learning with CVAE-based Pessimism (FASP). First, we employ Hamilton-Jacobi (H-J) reachability analysis to generate reliable safety labels, which serve as supervisory signals for training both a conditional variational autoencoder (CVAE) and a safety classifier. This approach not only ensures high sampling efficiency but also provides rigorous long-horizon safety guarantees. Furthermore, we utilize pessimistic estimation methods to estimate the Q-value of reward and cost, which mitigates the extrapolation errors induces by OOD actions, and penalize unsafe actions to enabled the agent to proactively avoid high-risk behaviors. Moreover, we theoretically prove the validity of this pessimistic estimation. Extensive experiments on DSRL benchmarks demonstrate that FASP algorithm achieves competitive performance across multiple experimental tasks, particularly outperforming state-of-the-art algorithms in terms of safety.
CoIn-SafeLink: Safety-critical Control With Cost-sensitive Incremental Random Vector Functional Link Network
Mar 19, 2025Control barrier functions (CBFs) play a crucial role in achieving the safety-critical control of robotic systems theoretically. However, most existing methods rely on the analytical expressions of unsafe state regions, which is often impractical for irregular and dynamic unsafe regions. In this paper, a novel CBF construction approach, called CoIn-SafeLink, is proposed based on cost-sensitive incremental random vector functional-link (RVFL) neural networks. By designing an appropriate cost function, CoIn-SafeLink achieves differentiated sensitivities to safe and unsafe samples, effectively achieving zero false-negative risk in unsafe sample classification. Additionally, an incremental update theorem for CoIn-SafeLink is proposed, enabling precise adjustments in response to changes in the unsafe region. Finally, the gradient analytical expression of the CoIn-SafeLink is provided to calculate the control input. The proposed method is validated on a 3-degree-of-freedom drone attitude control system. Experimental results demonstrate that the method can effectively learn the unsafe region boundaries and rapidly adapt as these regions evolve, with an update speed approximately five times faster than comparison methods. The source code is available at https://github.com/songqiaohu/CoIn-SafeLink.
Animate Anyone 2: High-Fidelity Character Image Animation with Environment Affordance
Feb 10, 2025



Recent character image animation methods based on diffusion models, such as Animate Anyone, have made significant progress in generating consistent and generalizable character animations. However, these approaches fail to produce reasonable associations between characters and their environments. To address this limitation, we introduce Animate Anyone 2, aiming to animate characters with environment affordance. Beyond extracting motion signals from source video, we additionally capture environmental representations as conditional inputs. The environment is formulated as the region with the exclusion of characters and our model generates characters to populate these regions while maintaining coherence with the environmental context. We propose a shape-agnostic mask strategy that more effectively characterizes the relationship between character and environment. Furthermore, to enhance the fidelity of object interactions, we leverage an object guider to extract features of interacting objects and employ spatial blending for feature injection. We also introduce a pose modulation strategy that enables the model to handle more diverse motion patterns. Experimental results demonstrate the superior performance of the proposed method.
MLPHand: Real Time Multi-View 3D Hand Mesh Reconstruction via MLP Modeling
Jun 23, 2024



Multi-view hand mesh reconstruction is a critical task for applications in virtual reality and human-computer interaction, but it remains a formidable challenge. Although existing multi-view hand reconstruction methods achieve remarkable accuracy, they typically come with an intensive computational burden that hinders real-time inference. To this end, we propose MLPHand, a novel method designed for real-time multi-view single hand reconstruction. MLP Hand consists of two primary modules: (1) a lightweight MLP-based Skeleton2Mesh model that efficiently recovers hand meshes from hand skeletons, and (2) a multi-view geometry feature fusion prediction module that enhances the Skeleton2Mesh model with detailed geometric information from multiple views. Experiments on three widely used datasets demonstrate that MLPHand can reduce computational complexity by 90% while achieving comparable reconstruction accuracy to existing state-of-the-art baselines.
Compact Real-time Radiance Fields with Neural Codebook
May 29, 2023



Reconstructing neural radiance fields with explicit volumetric representations, demonstrated by Plenoxels, has shown remarkable advantages on training and rendering efficiency, while grid-based representations typically induce considerable overhead for storage and transmission. In this work, we present a simple and effective framework for pursuing compact radiance fields from the perspective of compression methodology. By exploiting intrinsic properties exhibiting in grid models, a non-uniform compression stem is developed to significantly reduce model complexity and a novel parameterized module, named Neural Codebook, is introduced for better encoding high-frequency details specific to per-scene models via a fast optimization. Our approach can achieve over 40 $\times$ reduction on grid model storage with competitive rendering quality. In addition, the method can achieve real-time rendering speed with 180 fps, realizing significant advantage on storage cost compared to real-time rendering methods.
4K-NeRF: High Fidelity Neural Radiance Fields at Ultra High Resolutions
Dec 09, 2022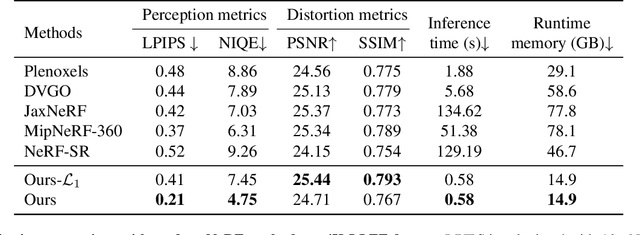
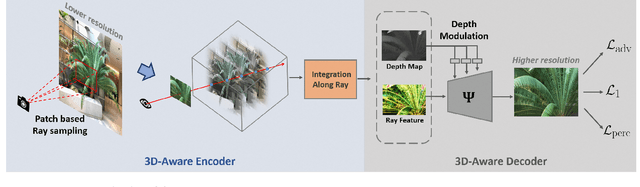
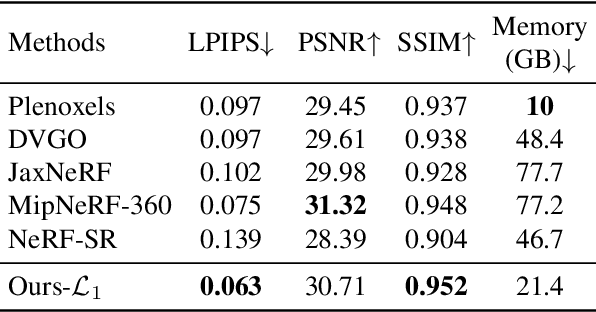

In this paper, we present a novel and effective framework, named 4K-NeRF, to pursue high fidelity view synthesis on the challenging scenarios of ultra high resolutions, building on the methodology of neural radiance fields (NeRF). The rendering procedure of NeRF-based methods typically relies on a pixel wise manner in which rays (or pixels) are treated independently on both training and inference phases, limiting its representational ability on describing subtle details especially when lifting to a extremely high resolution. We address the issue by better exploring ray correlation for enhancing high-frequency details benefiting from the use of geometry-aware local context. Particularly, we use the view-consistent encoder to model geometric information effectively in a lower resolution space and recover fine details through the view-consistent decoder, conditioned on ray features and depths estimated by the encoder. Joint training with patch-based sampling further facilitates our method incorporating the supervision from perception oriented regularization beyond pixel wise loss. Quantitative and qualitative comparisons with modern NeRF methods demonstrate that our method can significantly boost rendering quality for retaining high-frequency details, achieving the state-of-the-art visual quality on 4K ultra-high-resolution scenario. Code Available at \url{https://github.com/frozoul/4K-NeRF}
Compressing Volumetric Radiance Fields to 1 MB
Nov 29, 2022Approximating radiance fields with volumetric grids is one of promising directions for improving NeRF, represented by methods like Plenoxels and DVGO, which achieve super-fast training convergence and real-time rendering. However, these methods typically require a tremendous storage overhead, costing up to hundreds of megabytes of disk space and runtime memory for a single scene. We address this issue in this paper by introducing a simple yet effective framework, called vector quantized radiance fields (VQRF), for compressing these volume-grid-based radiance fields. We first present a robust and adaptive metric for estimating redundancy in grid models and performing voxel pruning by better exploring intermediate outputs of volumetric rendering. A trainable vector quantization is further proposed to improve the compactness of grid models. In combination with an efficient joint tuning strategy and post-processing, our method can achieve a compression ratio of 100$\times$ by reducing the overall model size to 1 MB with negligible loss on visual quality. Extensive experiments demonstrate that the proposed framework is capable of achieving unrivaled performance and well generalization across multiple methods with distinct volumetric structures, facilitating the wide use of volumetric radiance fields methods in real-world applications. Code Available at \url{https://github.com/AlgoHunt/VQRF}
Streaming Radiance Fields for 3D Video Synthesis
Oct 26, 2022We present an explicit-grid based method for efficiently reconstructing streaming radiance fields for novel view synthesis of real world dynamic scenes. Instead of training a single model that combines all the frames, we formulate the dynamic modeling problem with an incremental learning paradigm in which per-frame model difference is trained to complement the adaption of a base model on the current frame. By exploiting the simple yet effective tuning strategy with narrow bands, the proposed method realizes a feasible framework for handling video sequences on-the-fly with high training efficiency. The storage overhead induced by using explicit grid representations can be significantly reduced through the use of model difference based compression. We also introduce an efficient strategy to further accelerate model optimization for each frame. Experiments on challenging video sequences demonstrate that our approach is capable of achieving a training speed of 15 seconds per-frame with competitive rendering quality, which attains $1000 \times$ speedup over the state-of-the-art implicit methods. Code is available at https://github.com/AlgoHunt/StreamRF.
GraphFit: Learning Multi-scale Graph-Convolutional Representation for Point Cloud Normal Estimation
Jul 23, 2022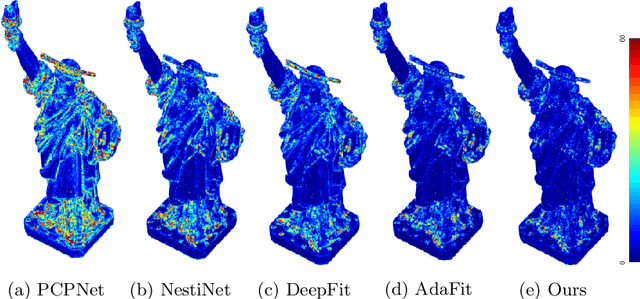
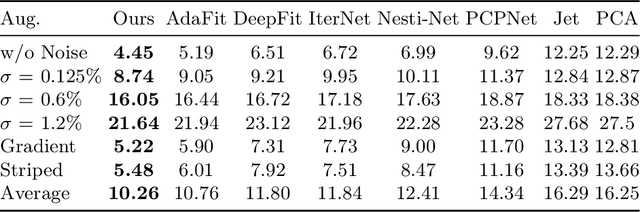
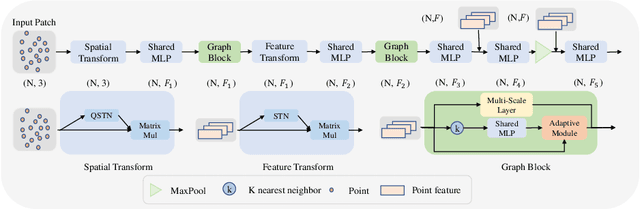
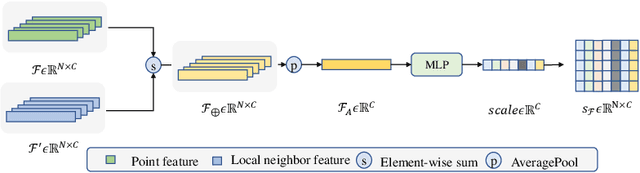
We propose a precise and efficient normal estimation method that can deal with noise and nonuniform density for unstructured 3D point clouds. Unlike existing approaches that directly take patches and ignore the local neighborhood relationships, which make them susceptible to challenging regions such as sharp edges, we propose to learn graph convolutional feature representation for normal estimation, which emphasizes more local neighborhood geometry and effectively encodes intrinsic relationships. Additionally, we design a novel adaptive module based on the attention mechanism to integrate point features with their neighboring features, hence further enhancing the robustness of the proposed normal estimator against point density variations. To make it more distinguishable, we introduce a multi-scale architecture in the graph block to learn richer geometric features. Our method outperforms competitors with the state-of-the-art accuracy on various benchmark datasets, and is quite robust against noise, outliers, as well as the density variations.