 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGI-1: Autoregressive Video Generation at Scale
May 19, 2025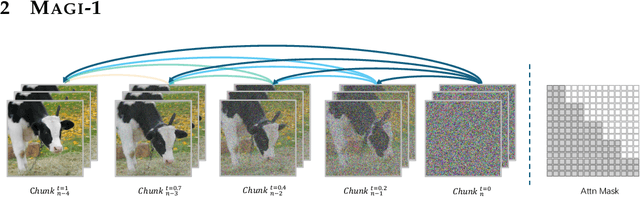
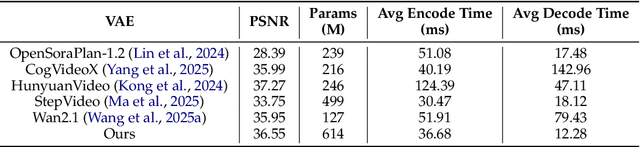
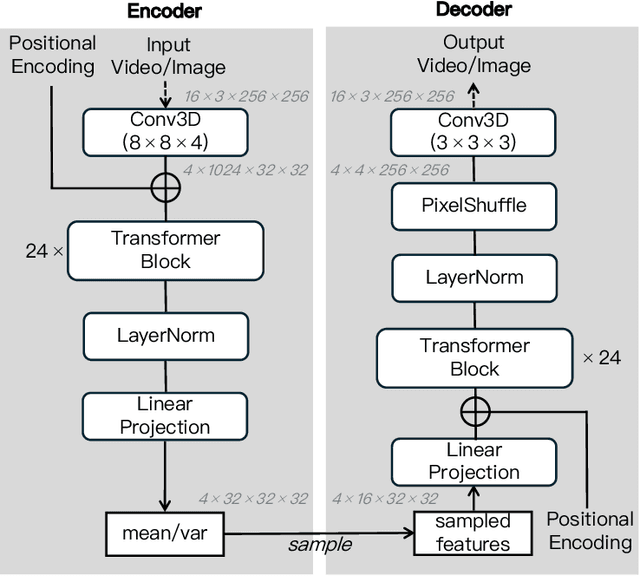
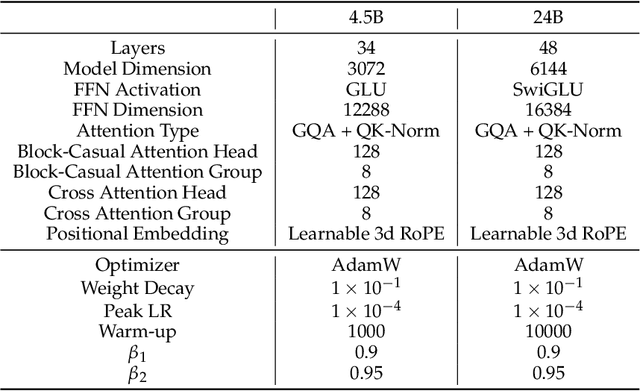
We present MAGI-1, a world model that generates videos by autoregressively predicting a sequence of video chunks, defined as fixed-length segments of consecutive frames. Trained to denoise per-chunk noise that increases monotonically over time, MAGI-1 enables causal temporal modeling and naturally supports streaming generation. It achieves strong performance on image-to-video (I2V) tasks conditioned on text instructions, providing high temporal consistency and scalability, which are made possible by several algorithmic innovations and a dedicated infrastructure stack. MAGI-1 facilitates controllable generation via chunk-wise prompting and supports real-time, memory-efficient deployment by maintaining constant peak inference cost, regardless of video length. The largest variant of MAGI-1 comprises 24 billion parameters and supports context lengths of up to 4 million tokens, demonstrating the scalability and robustness of our approach. The code and models are available at https://github.com/SandAI-org/MAGI-1 and https://github.com/SandAI-org/MagiAttention. The product can be accessed at https://sand.ai.
Compact Real-time Radiance Fields with Neural Codebook
May 29, 2023



Reconstructing neural radiance fields with explicit volumetric representations, demonstrated by Plenoxels, has shown remarkable advantages on training and rendering efficiency, while grid-based representations typically induce considerable overhead for storage and transmission. In this work, we present a simple and effective framework for pursuing compact radiance fields from the perspective of compression methodology. By exploiting intrinsic properties exhibiting in grid models, a non-uniform compression stem is developed to significantly reduce model complexity and a novel parameterized module, named Neural Codebook, is introduced for better encoding high-frequency details specific to per-scene models via a fast optimization. Our approach can achieve over 40 $\times$ reduction on grid model storage with competitive rendering quality. In addition, the method can achieve real-time rendering speed with 180 fps, realizing significant advantage on storage cost compared to real-time rendering methods.
4K-NeRF: High Fidelity Neural Radiance Fields at Ultra High Resolutions
Dec 09, 2022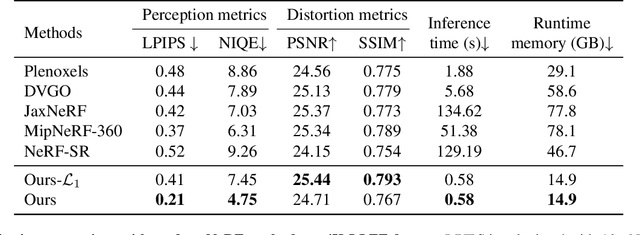
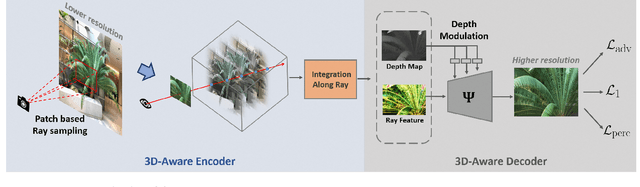
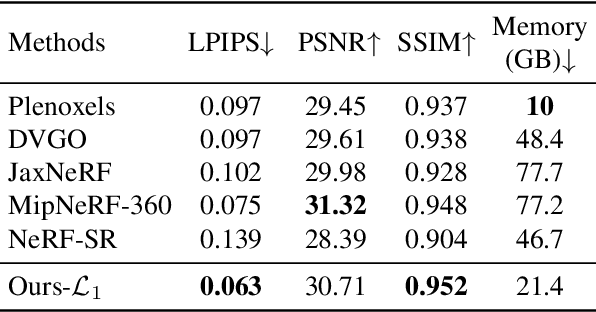

In this paper, we present a novel and effective framework, named 4K-NeRF, to pursue high fidelity view synthesis on the challenging scenarios of ultra high resolutions, building on the methodology of neural radiance fields (NeRF). The rendering procedure of NeRF-based methods typically relies on a pixel wise manner in which rays (or pixels) are treated independently on both training and inference phases, limiting its representational ability on describing subtle details especially when lifting to a extremely high resolution. We address the issue by better exploring ray correlation for enhancing high-frequency details benefiting from the use of geometry-aware local context. Particularly, we use the view-consistent encoder to model geometric information effectively in a lower resolution space and recover fine details through the view-consistent decoder, conditioned on ray features and depths estimated by the encoder. Joint training with patch-based sampling further facilitates our method incorporating the supervision from perception oriented regularization beyond pixel wise loss. Quantitative and qualitative comparisons with modern NeRF methods demonstrate that our method can significantly boost rendering quality for retaining high-frequency details, achieving the state-of-the-art visual quality on 4K ultra-high-resolution scenario. Code Available at \url{https://github.com/frozoul/4K-NeRF}
Compressing Volumetric Radiance Fields to 1 MB
Nov 29, 2022Approximating radiance fields with volumetric grids is one of promising directions for improving NeRF, represented by methods like Plenoxels and DVGO, which achieve super-fast training convergence and real-time rendering. However, these methods typically require a tremendous storage overhead, costing up to hundreds of megabytes of disk space and runtime memory for a single scene. We address this issue in this paper by introducing a simple yet effective framework, called vector quantized radiance fields (VQRF), for compressing these volume-grid-based radiance fields. We first present a robust and adaptive metric for estimating redundancy in grid models and performing voxel pruning by better exploring intermediate outputs of volumetric rendering. A trainable vector quantization is further proposed to improve the compactness of grid models. In combination with an efficient joint tuning strategy and post-processing, our method can achieve a compression ratio of 100$\times$ by reducing the overall model size to 1 MB with negligible loss on visual quality. Extensive experiments demonstrate that the proposed framework is capable of achieving unrivaled performance and well generalization across multiple methods with distinct volumetric structures, facilitating the wide use of volumetric radiance fields methods in real-world applications. Code Available at \url{https://github.com/AlgoHunt/VQRF}
Streaming Radiance Fields for 3D Video Synthesis
Oct 26, 2022We present an explicit-grid based method for efficiently reconstructing streaming radiance fields for novel view synthesis of real world dynamic scenes. Instead of training a single model that combines all the frames, we formulate the dynamic modeling problem with an incremental learning paradigm in which per-frame model difference is trained to complement the adaption of a base model on the current frame. By exploiting the simple yet effective tuning strategy with narrow bands, the proposed method realizes a feasible framework for handling video sequences on-the-fly with high training efficiency. The storage overhead induced by using explicit grid representations can be significantly reduced through the use of model difference based compression. We also introduce an efficient strategy to further accelerate model optimization for each frame. Experiments on challenging video sequences demonstrate that our approach is capable of achieving a training speed of 15 seconds per-frame with competitive rendering quality, which attains $1000 \times$ speedup over the state-of-the-art implicit methods. Code is available at https://github.com/AlgoHunt/StreamRF.