 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Scene Cloning:Advancing Zero-Shot Robotic Scene Adaptation in Manipulation via Visual Prompt Editing
Mar 10, 2026Modern robots can perform a wide range of simple tasks and adapt to diverse scenarios in the well-trained environment. However, deploying pre-trained robot models in real-world user scenarios remains challenging due to their limited zero-shot capabilities, often necessitating extensive on-site data collection. To address this issue, we propose Robotic Scene Cloning (RSC), a novel method designed for scene-specific adaptation by editing existing robot operation trajectories. RSC achieves accurate and scene-consistent sample generation by leveraging a visual prompting mechanism and a carefully tuned condition injection module. Not only transferring textures but also performing moderate shape adaptations in response to the visual prompts, RSC demonstrates reliable task performance across a variety of object types. Experiments across various simulated and real-world environments demonstrate that RSC significantly enhances policy generalization in target environments.
DM0: An Embodied-Native Vision-Language-Action Model towards Physical AI
Feb 16, 2026Moving beyond the traditional paradigm of adapting internet-pretrained models to physical tasks, we present DM0, an Embodied-Native Vision-Language-Action (VLA) framework designed for Physical AI. Unlike approaches that treat physical grounding as a fine-tuning afterthought, DM0 unifies embodied manipulation and navigation by learning from heterogeneous data sources from the onset. Our methodology follows a comprehensive three-stage pipeline: Pretraining, Mid-Training, and Post-Training. First, we conduct large-scale unified pretraining on the Vision-Language Model (VLM) using diverse corpora--seamlessly integrating web text, autonomous driving scenarios, and embodied interaction logs-to jointly acquire semantic knowledge and physical priors. Subsequently, we build a flow-matching action expert atop the VLM. To reconcile high-level reasoning with low-level control, DM0 employs a hybrid training strategy: for embodied data, gradients from the action expert are not backpropagated to the VLM to preserve generalized representations, while the VLM remains trainable on non-embodied data. Furthermore, we introduce an Embodied Spatial Scaffolding strategy to construct spatial Chain-of-Thought (CoT) reasoning, effectively constraining the action solution space. Experiments on the RoboChallenge benchmark demonstrate that DM0 achieves state-of-the-art performance in both Specialist and Generalist settings on Table30.
IntentionVLA: Generalizable and Efficient Embodied Intention Reasoning for Human-Robot Interaction
Oct 09, 2025



Vision-Language-Action (VLA) models leverage pretrained vision-language models (VLMs) to couple perception with robotic control, offering a promising path toward general-purpose embodied intelligence. However, current SOTA VLAs are primarily pretrained on multimodal tasks with limited relevance to embodied scenarios, and then finetuned to map explicit instructions to actions. Consequently, due to the lack of reasoning-intensive pretraining and reasoning-guided manipulation, these models are unable to perform implicit human intention reasoning required for complex, real-world interactions. To overcome these limitations, we propose \textbf{IntentionVLA}, a VLA framework with a curriculum training paradigm and an efficient inference mechanism. Our proposed method first leverages carefully designed reasoning data that combine intention inference, spatial grounding, and compact embodied reasoning, endowing the model with both reasoning and perception capabilities. In the following finetuning stage, IntentionVLA employs the compact reasoning outputs as contextual guidance for action generation, enabling fast inference under indirect instructions. Experimental results show that IntentionVLA substantially outperforms $\pi_0$, achieving 18\% higher success rates with direct instructions and 28\% higher than ECoT under intention instructions. On out-of-distribution intention tasks, IntentionVLA achieves over twice the success rate of all baselines, and further enables zero-shot human-robot interaction with 40\% success rate. These results highlight IntentionVLA as a promising paradigm for next-generation human-robot interaction (HRI) systems.
LLaDA-VLA: Vision Language Diffusion Action Models
Sep 10, 2025The rapid progress of auto-regressive vision-language models (VLMs) has inspired growing interest in vision-language-action models (VLA) for robotic manipulation. Recently, masked diffusion models, a paradigm distinct from autoregressive models, have begun to demonstrate competitive performance in text generation and multimodal applications, leading to the development of a series of diffusion-based VLMs (d-VLMs). However, leveraging such models for robot policy learning remains largely unexplored. In this work, we present LLaDA-VLA, the first Vision-Language-Diffusion-Action model built upon pretrained d-VLMs for robotic manipulation. To effectively adapt d-VLMs to robotic domain, we introduce two key designs: (1) a localized special-token classification strategy that replaces full-vocabulary classification with special action token classification, reducing adaptation difficulty; (2) a hierarchical action-structured decoding strategy that decodes action sequences hierarchically considering the dependencies within and across actions. Extensive experiments demonstrate that LLaDA-VLA significantly outperforms state-of-the-art VLAs on both simulation and real-world robots.
Holistic Tokenizer for Autoregressive Image Generation
Jul 03, 2025The vanilla autoregressive image generation model generates visual tokens in a step-by-step fashion, which limits the ability to capture holistic relationships among token sequences. Moreover, most visual tokenizers map local image patches into latent tokens, leading to limited global information. To address this, we introduce \textit{Hita}, a novel image tokenizer for autoregressive (AR) image generation. It introduces a holistic-to-local tokenization scheme with learnable holistic queries and local patch tokens. Besides, Hita incorporates two key strategies for improved alignment with the AR generation process: 1) it arranges a sequential structure with holistic tokens at the beginning followed by patch-level tokens while using causal attention to maintain awareness of previous tokens; and 2) before feeding the de-quantized tokens into the decoder, Hita adopts a lightweight fusion module to control information flow to prioritize holistic tokens. Extensive experiments show that Hita accelerates the training speed of AR generators and outperforms those trained with vanilla tokenizers, achieving \textbf{2.59 FID} and \textbf{281.9 IS} on the ImageNet benchmark. A detailed analysis of the holistic representation highlights its ability to capture global image properties such as textures, materials, and shapes. Additionally, Hita also demonstrates effectiveness in zero-shot style transfer and image in-painting. The code is available at \href{https://github.com/CVMI-Lab/Hita}{https://github.com/CVMI-Lab/Hita}
ROSA: Harnessing Robot States for Vision-Language and Action Alignment
Jun 16, 2025Vision-Language-Action (VLA) models have recently made significant advance in multi-task, end-to-end robotic control, due to the strong generalization capabilities of Vision-Language Models (VLMs). A fundamental challenge in developing such models is effectively aligning the vision-language space with the robotic action space. Existing approaches typically rely on directly fine-tuning VLMs using expert demonstrations. However, this strategy suffers from a spatio-temporal gap, resulting in considerable data inefficiency and heavy reliance on human labor. Spatially, VLMs operate within a high-level semantic space, whereas robotic actions are grounded in low-level 3D physical space; temporally, VLMs primarily interpret the present, while VLA models anticipate future actions. To overcome these challenges, we propose a novel training paradigm, ROSA, which leverages robot state estimation to improve alignment between vision-language and action spaces. By integrating robot state estimation data obtained via an automated process, ROSA enables the VLA model to gain enhanced spatial understanding and self-awareness, thereby boosting performance and generalization. Extensive experiments in both simulated and real-world environments demonstrate the effectiveness of ROSA, particularly in low-data regimes.
PADriver: Towards Personalized Autonomous Driving
May 08, 2025In this paper, we propose PADriver, a novel closed-loop framework for personalized autonomous driving (PAD). Built upon Multi-modal Large Language Model (MLLM), PADriver takes streaming frames and personalized textual prompts as inputs. It autoaggressively performs scene understanding, danger level estimation and action decision. The predicted danger level reflects the risk of the potential action and provides an explicit reference for the final action, which corresponds to the preset personalized prompt. Moreover, we construct a closed-loop benchmark named PAD-Highway based on Highway-Env simulator to comprehensively evaluate the decision performance under traffic rules. The dataset contains 250 hours videos with high-quality annotation to facilitate the development of PAD behavior analysis. Experimental results on the constructed benchmark show that PADriver outperforms state-of-the-art approaches on different evaluation metrics, and enables various driving modes.
Ross3D: Reconstructive Visual Instruction Tuning with 3D-Awareness
Apr 02, 2025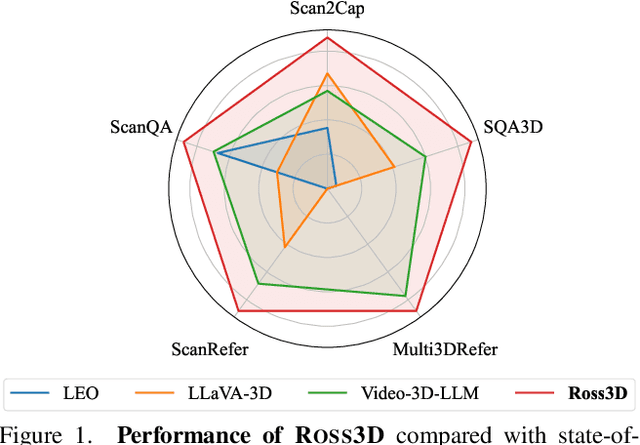
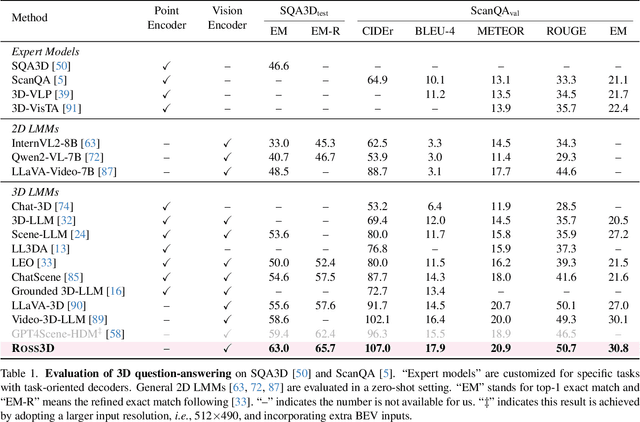
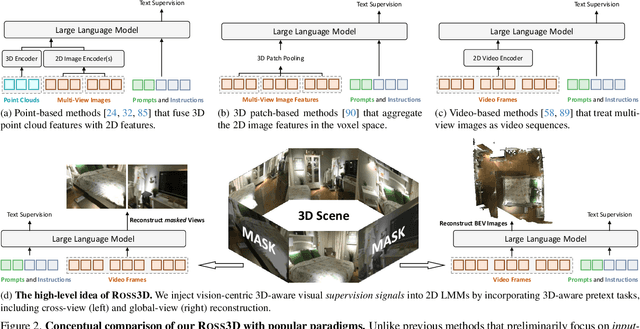
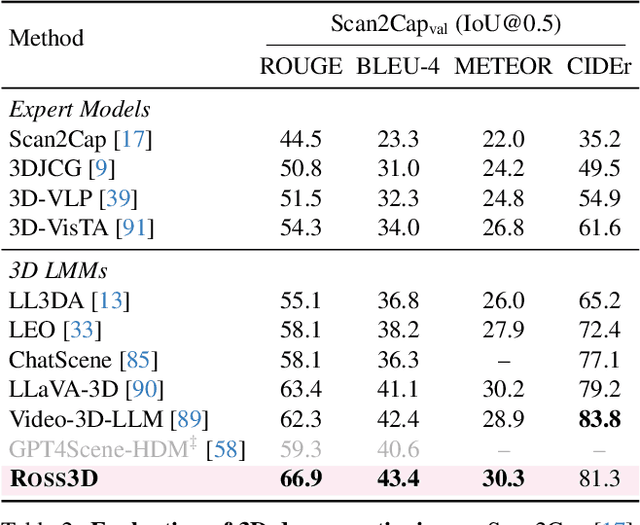
The rapid development of Large Multimodal Models (LMMs) for 2D images and videos has spurred efforts to adapt these models for interpreting 3D scenes. However, the absence of large-scale 3D vision-language datasets has posed a significant obstacle. To address this issue, typical approaches focus on injecting 3D awareness into 2D LMMs by designing 3D input-level scene representations. This work provides a new perspective. We introduce reconstructive visual instruction tuning with 3D-awareness (Ross3D), which integrates 3D-aware visual supervision into the training procedure. Specifically, it incorporates cross-view and global-view reconstruction. The former requires reconstructing masked views by aggregating overlapping information from other views. The latter aims to aggregate information from all available views to recover Bird's-Eye-View images, contributing to a comprehensive overview of the entire scene. Empirically, Ross3D achieves state-of-the-art performance across various 3D scene understanding benchmarks. More importantly, our semi-supervised experiments demonstrate significant potential in leveraging large amounts of unlabeled 3D vision-only data.
Reconstructive Visual Instruction Tuning
Oct 12, 2024This paper introduces reconstructive visual instruction tuning (ROSS), a family of Large Multimodal Models (LMMs) that exploit vision-centric supervision signals. In contrast to conventional visual instruction tuning approaches that exclusively supervise text outputs, ROSS prompts LMMs to supervise visual outputs via reconstructing input images. By doing so, it capitalizes on the inherent richness and detail present within input images themselves, which are often lost in pure text supervision. However, producing meaningful feedback from natural images is challenging due to the heavy spatial redundancy of visual signals. To address this issue, ROSS employs a denoising objective to reconstruct latent representations of input images, avoiding directly regressing exact raw RGB values. This intrinsic activation design inherently encourages LMMs to maintain image detail, thereby enhancing their fine-grained comprehension capabilities and reducing hallucinations. Empirically, ROSS consistently brings significant improvements across different visual encoders and language models. In comparison with extrinsic assistance state-of-the-art alternatives that aggregate multiple visual experts, ROSS delivers competitive performance with a single SigLIP visual encoder, demonstrating the efficacy of our vision-centric supervision tailored for visual outputs.
Is a 3D-Tokenized LLM the Key to Reliable Autonomous Driving?
May 28, 2024Rapid advancements in Autonomous Driving (AD) tasks turned a significant shift toward end-to-end fashion, particularly in the utilization of vision-language models (VLMs) that integrate robust logical reasoning and cognitive abilities to enable comprehensive end-to-end planning. However, these VLM-based approaches tend to integrate 2D vision tokenizers and a large language model (LLM) for ego-car planning, which lack 3D geometric priors as a cornerstone of reliable planning. Naturally, this observation raises a critical concern: Can a 2D-tokenized LLM accurately perceive the 3D environment? Our evaluation of current VLM-based methods across 3D object detection, vectorized map construction, and environmental caption suggests that the answer is, unfortunately, NO. In other words, 2D-tokenized LLM fails to provide reliable autonomous driving. In response, we introduce DETR-style 3D perceptrons as 3D tokenizers, which connect LLM with a one-layer linear projector. This simple yet elegant strategy, termed Atlas, harnesses the inherent priors of the 3D physical world, enabling it to simultaneously process high-resolution multi-view images and employ spatiotemporal modeling. Despite its simplicity, Atlas demonstrates superior performance in both 3D detection and ego planning tasks on nuScenes dataset, proving that 3D-tokenized LLM is the key to reliable autonomous driving. The code and datasets will be released.