 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolistic Tokenizer for Autoregressive Image Generation
Jul 03, 2025The vanilla autoregressive image generation model generates visual tokens in a step-by-step fashion, which limits the ability to capture holistic relationships among token sequences. Moreover, most visual tokenizers map local image patches into latent tokens, leading to limited global information. To address this, we introduce \textit{Hita}, a novel image tokenizer for autoregressive (AR) image generation. It introduces a holistic-to-local tokenization scheme with learnable holistic queries and local patch tokens. Besides, Hita incorporates two key strategies for improved alignment with the AR generation process: 1) it arranges a sequential structure with holistic tokens at the beginning followed by patch-level tokens while using causal attention to maintain awareness of previous tokens; and 2) before feeding the de-quantized tokens into the decoder, Hita adopts a lightweight fusion module to control information flow to prioritize holistic tokens. Extensive experiments show that Hita accelerates the training speed of AR generators and outperforms those trained with vanilla tokenizers, achieving \textbf{2.59 FID} and \textbf{281.9 IS} on the ImageNet benchmark. A detailed analysis of the holistic representation highlights its ability to capture global image properties such as textures, materials, and shapes. Additionally, Hita also demonstrates effectiveness in zero-shot style transfer and image in-painting. The code is available at \href{https://github.com/CVMI-Lab/Hita}{https://github.com/CVMI-Lab/Hita}
Reconstructive Visual Instruction Tuning
Oct 12, 2024This paper introduces reconstructive visual instruction tuning (ROSS), a family of Large Multimodal Models (LMMs) that exploit vision-centric supervision signals. In contrast to conventional visual instruction tuning approaches that exclusively supervise text outputs, ROSS prompts LMMs to supervise visual outputs via reconstructing input images. By doing so, it capitalizes on the inherent richness and detail present within input images themselves, which are often lost in pure text supervision. However, producing meaningful feedback from natural images is challenging due to the heavy spatial redundancy of visual signals. To address this issue, ROSS employs a denoising objective to reconstruct latent representations of input images, avoiding directly regressing exact raw RGB values. This intrinsic activation design inherently encourages LMMs to maintain image detail, thereby enhancing their fine-grained comprehension capabilities and reducing hallucinations. Empirically, ROSS consistently brings significant improvements across different visual encoders and language models. In comparison with extrinsic assistance state-of-the-art alternatives that aggregate multiple visual experts, ROSS delivers competitive performance with a single SigLIP visual encoder, demonstrating the efficacy of our vision-centric supervision tailored for visual outputs.
Self-Supervised Visual Representation Learning with Semantic Grouping
May 30, 2022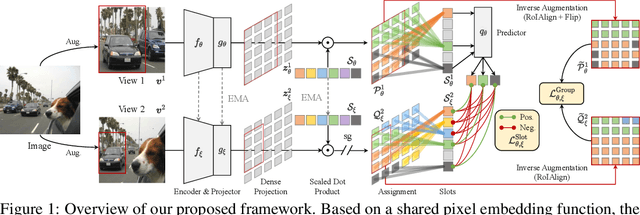


In this paper, we tackle the problem of learning visual representations from unlabeled scene-centric data. Existing works have demonstrated the potential of utilizing the underlying complex structure within scene-centric data; still, they commonly rely on hand-crafted objectness priors or specialized pretext tasks to build a learning framework, which may harm generalizability. Instead, we propose contrastive learning from data-driven semantic slots, namely SlotCon, for joint semantic grouping and representation learning. The semantic grouping is performed by assigning pixels to a set of learnable prototypes, which can adapt to each sample by attentive pooling over the feature and form new slots. Based on the learned data-dependent slots, a contrastive objective is employed for representation learning, which enhances the discriminability of features, and conversely facilitates grouping semantically coherent pixels together. Compared with previous efforts, by simultaneously optimizing the two coupled objectives of semantic grouping and contrastive learning, our approach bypasses the disadvantages of hand-crafted priors and is able to learn object/group-level representations from scene-centric images. Experiments show our approach effectively decomposes complex scenes into semantic groups for feature learning and significantly benefits downstream tasks, including object detection, instance segmentation, and semantic segmentation. The code will be made publicly available.
Progressive End-to-End Object Detection in Crowded Scenes
Mar 19, 2022
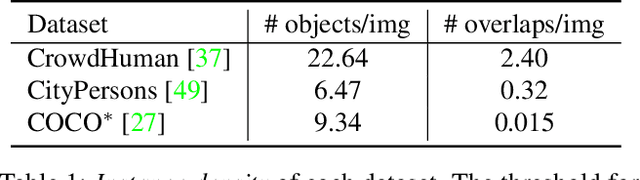
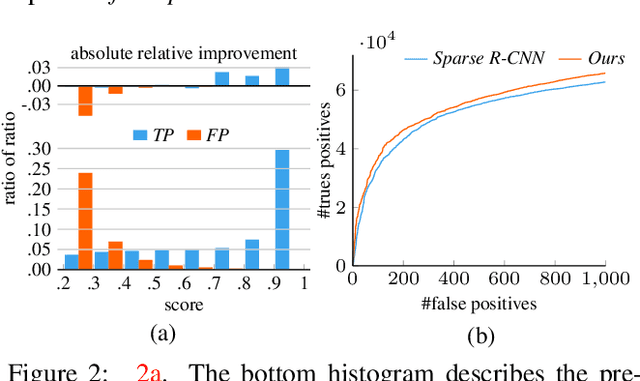
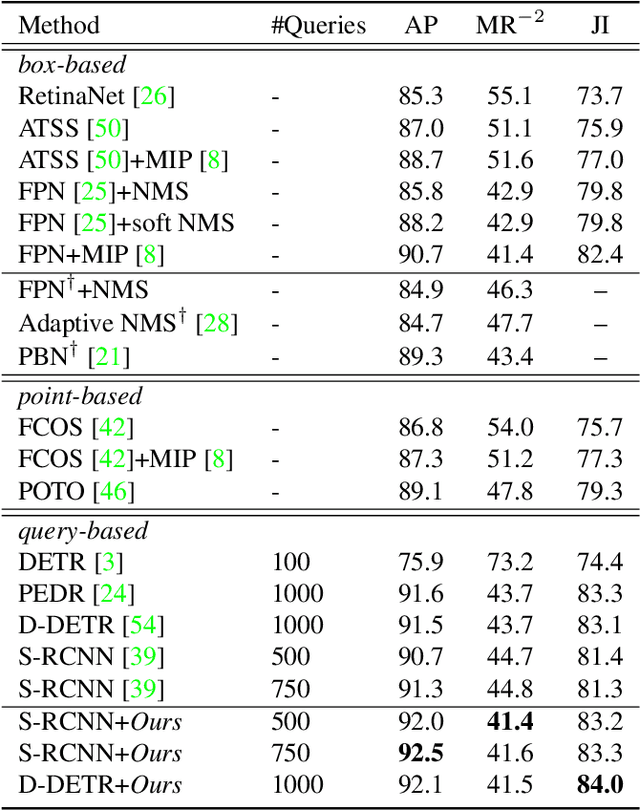
In this paper, we propose a new query-based detection framework for crowd detection. Previous query-based detectors suffer from two drawbacks: first, multiple predictions will be inferred for a single object, typically in crowded scenes; second, the performance saturates as the depth of the decoding stage increases. Benefiting from the nature of the one-to-one label assignment rule, we propose a progressive predicting method to address the above issues. Specifically, we first select accepted queries prone to generate true positive predictions, then refine the rest noisy queries according to the previously accepted predictions. Experiments show that our method can significantly boost the performance of query-based detectors in crowded scenes. Equipped with our approach, Sparse RCNN achieves 92.0\% $\text{AP}$, 41.4\% $\text{MR}^{-2}$ and 83.2\% $\text{JI}$ on the challenging CrowdHuman \cite{shao2018crowdhuman} dataset, outperforming the box-based method MIP \cite{chu2020detection} that specifies in handling crowded scenarios. Moreover, the proposed method, robust to crowdedness, can still obtain consistent improvements on moderately and slightly crowded datasets like CityPersons \cite{zhang2017citypersons} and COCO \cite{lin2014microsoft}. Code will be made publicly available at https://github.com/megvii-model/Iter-E2EDET.
Detection in Crowded Scenes: One Proposal, Multiple Predictions
Mar 20, 2020
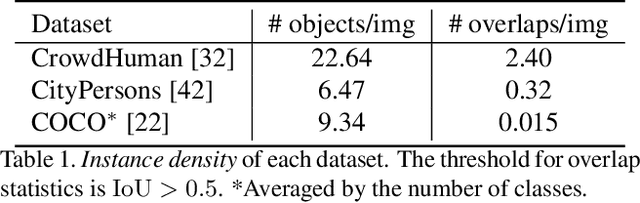

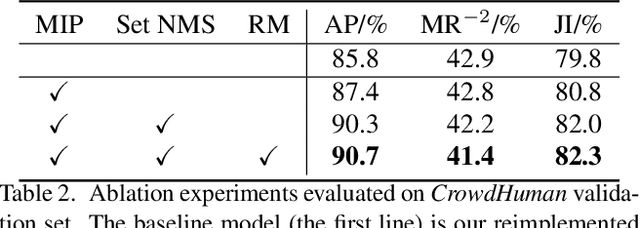
We propose a simple yet effective proposal-based object detector, aiming at detecting highly-overlapped instances in crowded scenes. The key of our approach is to let each proposal predict a set of correlated instances rather than a single one in previous proposal-based frameworks. Equipped with new techniques such as EMD Loss and Set NMS, our detector can effectively handle the difficulty of detecting highly overlapped objects. On a FPN-Res50 baseline, our detector can obtain 4.9\% AP gains on challenging CrowdHuman dataset and 1.0\% $\text{MR}^{-2}$ improvements on CityPersons dataset, without bells and whistles. Moreover, on less crowed datasets like COCO, our approach can still achieve moderate improvement, suggesting the proposed method is robust to crowdedness. Code and pre-trained models will be released at https://github.com/megvii-model/CrowdDetection.
Complementary Segmentation of Primary Video Objects with Reversible Flows
Nov 23, 2018
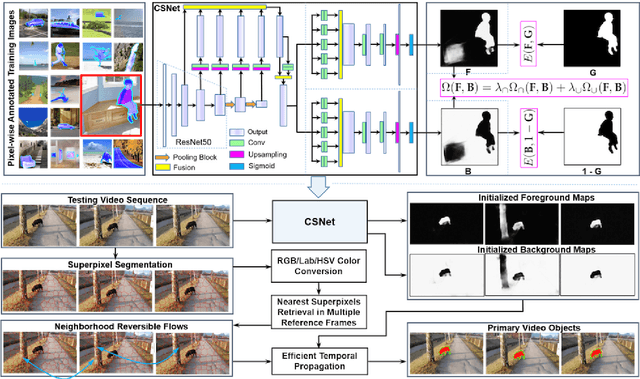
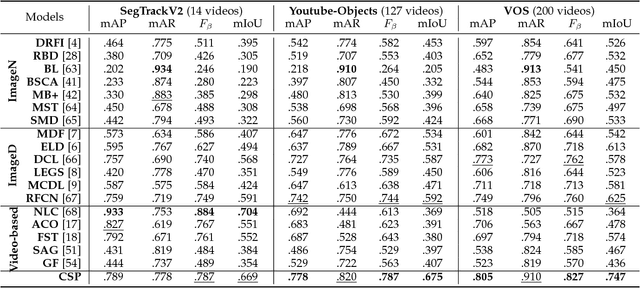
Segmenting primary objects in a video is an important yet challenging problem in computer vision, as it exhibits various levels of foreground/background ambiguities. To reduce such ambiguities, we propose a novel formulation via exploiting foreground and background context as well as their complementary constraint. Under this formulation, a unified objective function is further defined to encode each cue. For implementation, we design a Complementary Segmentation Network (CSNet) with two separate branches, which can simultaneously encode the foreground and background information along with joint spatial constraints. The CSNet is trained on massive images with manually annotated salient objects in an end-to-end manner. By applying CSNet on each video frame, the spatial foreground and background maps can be initialized. To enforce temporal consistency effectively and efficiently, we divide each frame into superpixels and construct neighborhood reversible flow that reflects the most reliable temporal correspondences between superpixels in far-away frames. With such flow, the initialized foregroundness and backgroundness can be propagated along the temporal dimension so that primary video objects gradually pop-out and distractors are well suppressed. Extensive experimental results on three video datasets show that the proposed approach achieves impressive performance in comparisons with 18 state-of-the-art models.