 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising the Deep Sky: Physics-Based CCD Noise Formation for Astronomical Imaging
Jan 30, 2026Astronomical imaging remains noise-limited under practical observing constraints, while standard calibration pipelines mainly remove structured artifacts and leave stochastic noise largely unresolved. Learning-based denoising is promising, yet progress is hindered by scarce paired training data and the need for physically interpretable and reproducible models in scientific workflows. We propose a physics-based noise synthesis framework tailored to CCD noise formation. The pipeline models photon shot noise, photo-response non-uniformity, dark-current noise, readout effects, and localized outliers arising from cosmic-ray hits and hot pixels. To obtain low-noise inputs for synthesis, we average multiple unregistered exposures to produce high-SNR bases. Realistic noisy counterparts synthesized from these bases using our noise model enable the construction of abundant paired datasets for supervised learning. We further introduce a real-world dataset across multi-bands acquired with two twin ground-based telescopes, providing paired raw frames and instrument-pipeline calibrated frames, together with calibration data and stacked high-SNR bases for real-world evaluation.
RealX3D: A Physically-Degraded 3D Benchmark for Multi-view Visual Restoration and Reconstruction
Dec 29, 2025We introduce RealX3D, a real-capture benchmark for multi-view visual restoration and 3D reconstruction under diverse physical degradations. RealX3D groups corruptions into four families, including illumination, scattering, occlusion, and blurring, and captures each at multiple severity levels using a unified acquisition protocol that yields pixel-aligned LQ/GT views. Each scene includes high-resolution capture, RAW images, and dense laser scans, from which we derive world-scale meshes and metric depth. Benchmarking a broad range of optimization-based and feed-forward methods shows substantial degradation in reconstruction quality under physical corruptions, underscoring the fragility of current multi-view pipelines in real-world challenging environments.
Towards Interactive Intelligence for Digital Humans
Dec 15, 2025We introduce Interactive Intelligence, a novel paradigm of digital human that is capable of personality-aligned expression, adaptive interaction, and self-evolution. To realize this, we present Mio (Multimodal Interactive Omni-Avatar), an end-to-end framework composed of five specialized modules: Thinker, Talker, Face Animator, Body Animator, and Renderer. This unified architecture integrates cognitive reasoning with real-time multimodal embodiment to enable fluid, consistent interaction. Furthermore, we establish a new benchmark to rigorously evaluate the capabilities of interactive intelligence. Extensive experiments demonstrate that our framework achieves superior performance compared to state-of-the-art methods across all evaluated dimensions. Together, these contributions move digital humans beyond superficial imitation toward intelligent interaction.
UniLS: End-to-End Audio-Driven Avatars for Unified Listening and Speaking
Dec 10, 2025Generating lifelike conversational avatars requires modeling not just isolated speakers, but the dynamic, reciprocal interaction of speaking and listening. However, modeling the listener is exceptionally challenging: direct audio-driven training fails, producing stiff, static listening motions. This failure stems from a fundamental imbalance: the speaker's motion is strongly driven by speech audio, while the listener's motion primarily follows an internal motion prior and is only loosely guided by external speech. This challenge has led most methods to focus on speak-only generation. The only prior attempt at joint generation relies on extra speaker's motion to produce the listener. This design is not end-to-end, thereby hindering the real-time applicability. To address this limitation, we present UniLS, the first end-to-end framework for generating unified speak-listen expressions, driven by only dual-track audio. Our method introduces a novel two-stage training paradigm. Stage 1 first learns the internal motion prior by training an audio-free autoregressive generator, capturing the spontaneous dynamics of natural facial motion. Stage 2 then introduces the dual-track audio, fine-tuning the generator to modulate the learned motion prior based on external speech cues. Extensive evaluations show UniLS achieves state-of-the-art speaking accuracy. More importantly, it delivers up to 44.1\% improvement in listening metrics, generating significantly more diverse and natural listening expressions. This effectively mitigates the stiffness problem and provides a practical, high-fidelity audio-driven solution for interactive digital humans.
Luminance-GS: Adapting 3D Gaussian Splatting to Challenging Lighting Conditions with View-Adaptive Curve Adjustment
Apr 02, 2025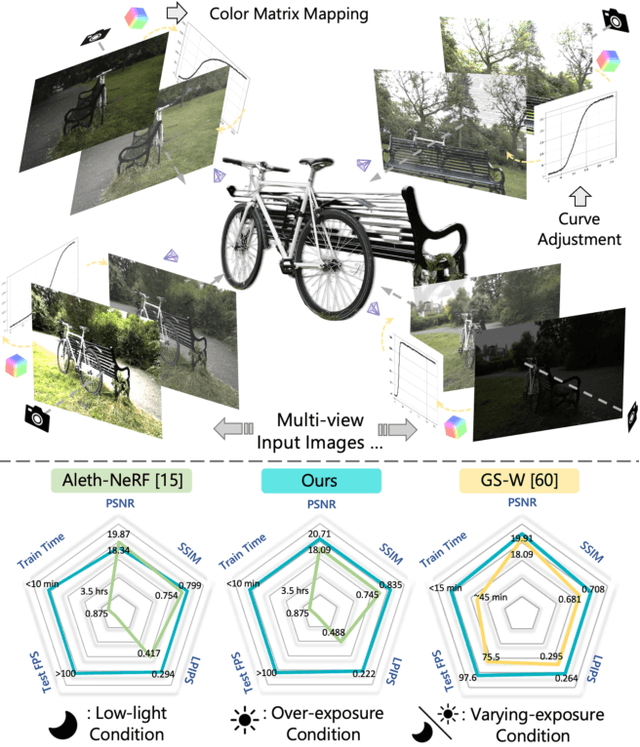
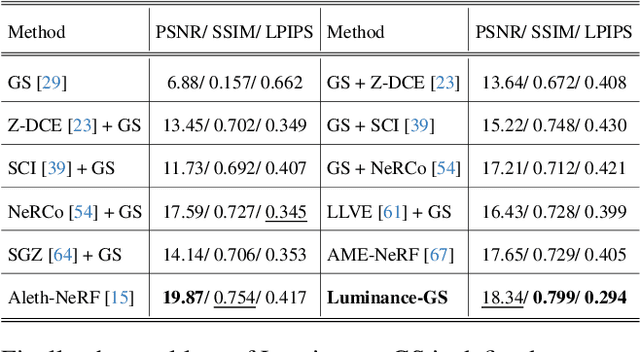
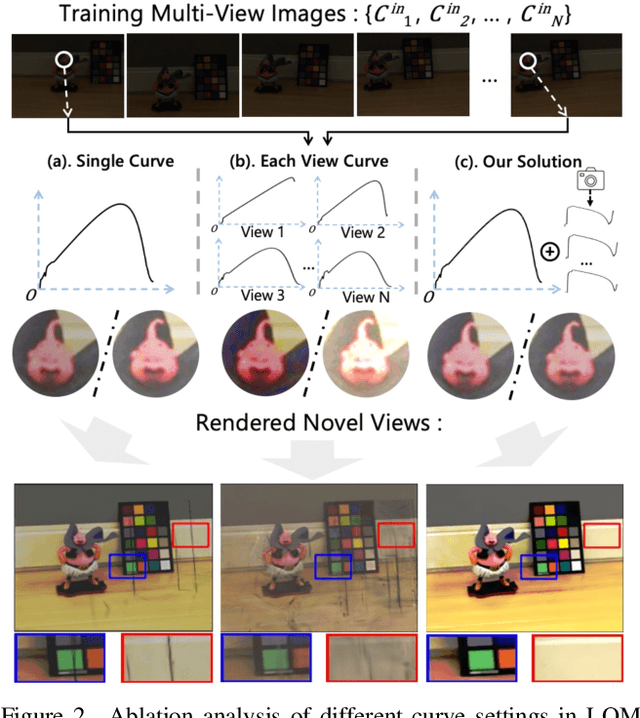
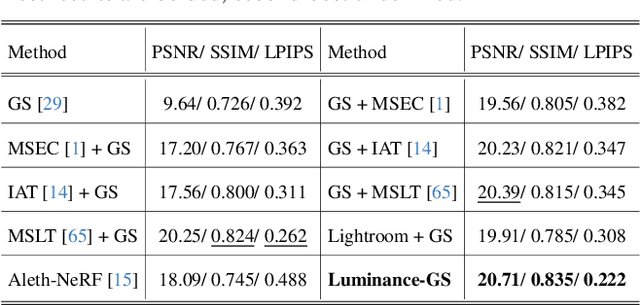
Capturing high-quality photographs under diverse real-world lighting conditions is challenging, as both natural lighting (e.g., low-light) and camera exposure settings (e.g., exposure time) significantly impact image quality. This challenge becomes more pronounced in multi-view scenarios, where variations in lighting and image signal processor (ISP) settings across viewpoints introduce photometric inconsistencies. Such lighting degradations and view-dependent variations pose substantial challenges to novel view synthesis (NVS) frameworks based on Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). To address this, we introduce Luminance-GS, a novel approach to achieving high-quality novel view synthesis results under diverse challenging lighting conditions using 3DGS. By adopting per-view color matrix mapping and view-adaptive curve adjustments, Luminance-GS achieves state-of-the-art (SOTA) results across various lighting conditions -- including low-light, overexposure, and varying exposure -- while not altering the original 3DGS explicit representation. Compared to previous NeRF- and 3DGS-based baselines, Luminance-GS provides real-time rendering speed with improved reconstruction quality.
ARTalk: Speech-Driven 3D Head Animation via Autoregressive Model
Feb 28, 2025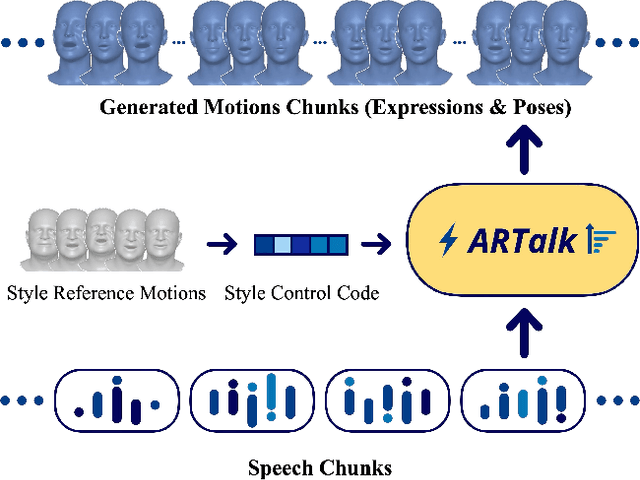
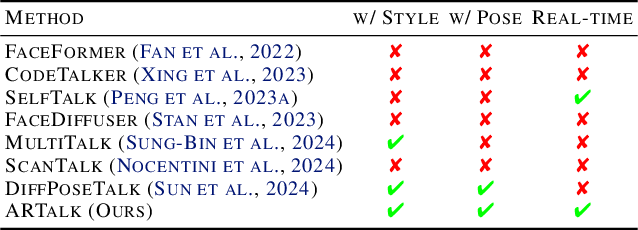
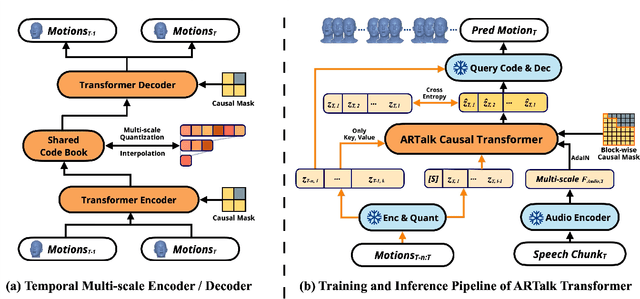
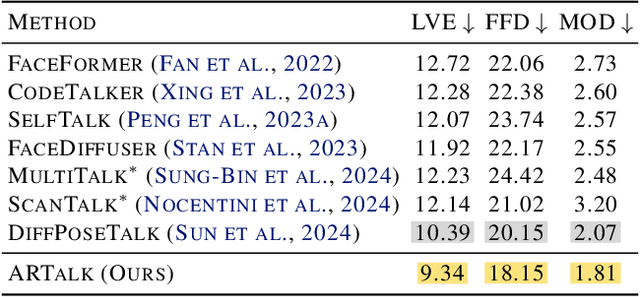
Speech-driven 3D facial animation aims to generate realistic lip movements and facial expressions for 3D head models from arbitrary audio clips. Although existing diffusion-based methods are capable of producing natural motions, their slow generation speed limits their application potential. In this paper, we introduce a novel autoregressive model that achieves real-time generation of highly synchronized lip movements and realistic head poses and eye blinks by learning a mapping from speech to a multi-scale motion codebook. Furthermore, our model can adapt to unseen speaking styles using sample motion sequences, enabling the creation of 3D talking avatars with unique personal styles beyond the identities seen during training. Extensive evaluations and user studies demonstrate that our method outperforms existing approaches in lip synchronization accuracy and perceived quality.
Generalizable and Animatable Gaussian Head Avatar
Oct 10, 2024



In this paper, we propose Generalizable and Animatable Gaussian head Avatar (GAGAvatar) for one-shot animatable head avatar reconstruction. Existing methods rely on neural radiance fields, leading to heavy rendering consumption and low reenactment speeds. To address these limitations, we generate the parameters of 3D Gaussians from a single image in a single forward pass. The key innovation of our work is the proposed dual-lifting method, which produces high-fidelity 3D Gaussians that capture identity and facial details. Additionally, we leverage global image features and the 3D morphable model to construct 3D Gaussians for controlling expressions. After training, our model can reconstruct unseen identities without specific optimizations and perform reenactment rendering at real-time speeds. Experiments show that our method exhibits superior performance compared to previous methods in terms of reconstruction quality and expression accuracy. We believe our method can establish new benchmarks for future research and advance applications of digital avatars. Code and demos are available https://github.com/xg-chu/GAGAvatar.
GPAvatar: Generalizable and Precise Head Avatar from Image(s)
Jan 18, 2024
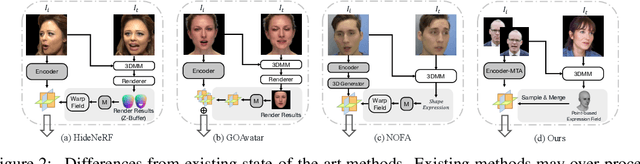


Head avatar reconstruction, crucial for applications in virtual reality, online meetings, gaming, and film industries, has garnered substantial attention within the computer vision community. The fundamental objective of this field is to faithfully recreate the head avatar and precisely control expressions and postures. Existing methods, categorized into 2D-based warping, mesh-based, and neural rendering approaches, present challenges in maintaining multi-view consistency, incorporating non-facial information, and generalizing to new identities. In this paper, we propose a framework named GPAvatar that reconstructs 3D head avatars from one or several images in a single forward pass. The key idea of this work is to introduce a dynamic point-based expression field driven by a point cloud to precisely and effectively capture expressions. Furthermore, we use a Multi Tri-planes Attention (MTA) fusion module in the tri-planes canonical field to leverage information from multiple input images. The proposed method achieves faithful identity reconstruction, precise expression control, and multi-view consistency, demonstrating promising results for free-viewpoint rendering and novel view synthesis.
Audio-Driven 3D Facial Animation from In-the-Wild Videos
Jun 20, 2023
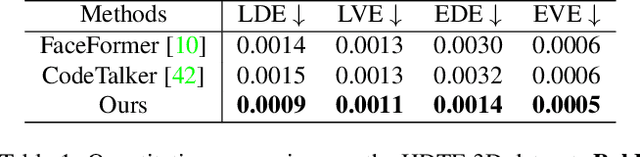
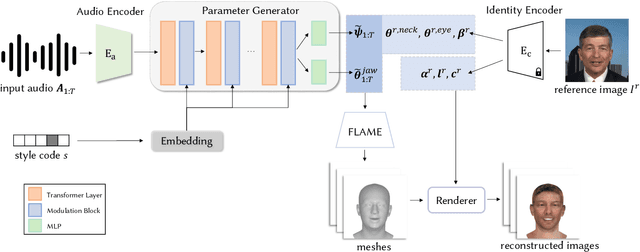
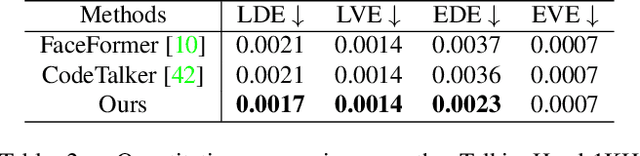
Given an arbitrary audio clip, audio-driven 3D facial animation aims to generate lifelike lip motions and facial expressions for a 3D head. Existing methods typically rely on training their models using limited public 3D datasets that contain a restricted number of audio-3D scan pairs. Consequently, their generalization capability remains limited. In this paper, we propose a novel method that leverages in-the-wild 2D talking-head videos to train our 3D facial animation model. The abundance of easily accessible 2D talking-head videos equips our model with a robust generalization capability. By combining these videos with existing 3D face reconstruction methods, our model excels in generating consistent and high-fidelity lip synchronization. Additionally, our model proficiently captures the speaking styles of different individuals, allowing it to generate 3D talking-heads with distinct personal styles. Extensive qualitative and quantitative experimental results demonstrate the superiority of our method.
Detection in Crowded Scenes: One Proposal, Multiple Predictions
Mar 20, 2020
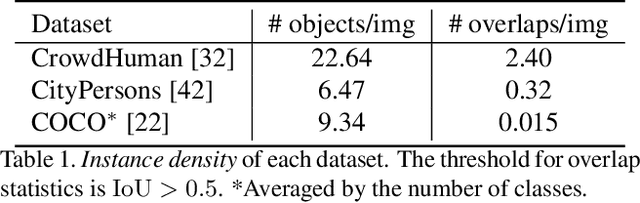

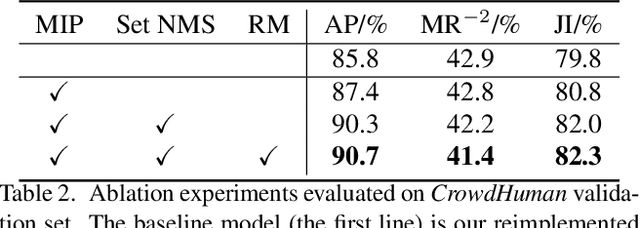
We propose a simple yet effective proposal-based object detector, aiming at detecting highly-overlapped instances in crowded scenes. The key of our approach is to let each proposal predict a set of correlated instances rather than a single one in previous proposal-based frameworks. Equipped with new techniques such as EMD Loss and Set NMS, our detector can effectively handle the difficulty of detecting highly overlapped objects. On a FPN-Res50 baseline, our detector can obtain 4.9\% AP gains on challenging CrowdHuman dataset and 1.0\% $\text{MR}^{-2}$ improvements on CityPersons dataset, without bells and whistles. Moreover, on less crowed datasets like COCO, our approach can still achieve moderate improvement, suggesting the proposed method is robust to crowdedness. Code and pre-trained models will be released at https://github.com/megvii-model/CrowdDetection.