 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSurvey: Enhancing Analytical Depth and Citation Reliability in Automated Survey Generation
May 28, 2026As scientific literature grows rapidly, automated survey generation has become a key capability for AI scientists and human researchers. However, existing systems suffer from limited analytical depth due to reliance on abstracts and isolated paper processing, and unreliable citations from imprecise retrieval and post-hoc grounding, producing superficial surveys and may mislead researchers. We present DeepSurvey, an agentic system that addresses both. To enhance depth, DeepSurvey extracts structured keynotes from full-text papers, models cross-paper relationships through clustering and comparative analysis, and integrates code-repository analysis to recover implementation-level details. To fortify reliability, it combines citation-graph expansion with hybrid filtering for topic-focussed retrieval, enforces evidence-constrained citation assignment, and deploys multi-granularity agentic refinement to validate citation-claim alignment. Experiments show that DeepSurvey achieves the highest content score (8.644/10) and citation quality (12.3% and 9.3% recall and precision gains over the strongest baseline), generalizes more robustly across domains (0.14 vs 0.22 to 0.69 CS-to-non-CS drop), and is preferred over human-written surveys by domain experts (83.3% overall quality, 100% content depth).
AcademiClaw: When Students Set Challenges for AI Agents
May 04, 2026Benchmarks within the OpenClaw ecosystem have thus far evaluated exclusively assistant-level tasks, leaving the academic-level capabilities of OpenClaw largely unexamined. We introduce AcademiClaw, a bilingual benchmark of 80 complex, long-horizon tasks sourced directly from university students' real academic workflows -- homework, research projects, competitions, and personal projects -- that they found current AI agents unable to solve effectively. Curated from 230 student-submitted candidates through rigorous expert review, the final task set spans 25+ professional domains, ranging from olympiad-level mathematics and linguistics problems to GPU-intensive reinforcement learning and full-stack system debugging, with 16 tasks requiring CUDA GPU execution. Each task executes in an isolated Docker sandbox and is scored on task completion by multi-dimensional rubrics combining six complementary techniques, with an independent five-category safety audit providing additional behavioral analysis. Experiments on six frontier models show that even the best achieves only a 55\% pass rate. Further analysis uncovers sharp capability boundaries across task domains, divergent behavioral strategies among models, and a disconnect between token consumption and output quality, providing fine-grained diagnostic signals beyond what aggregate metrics reveal. We hope that AcademiClaw and its open-sourced data and code can serve as a useful resource for the OpenClaw community, driving progress toward agents that are more capable and versatile across the full breadth of real-world academic demands. All data and code are available at https://github.com/GAIR-NLP/AcademiClaw.
NTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
CodePercept: Code-Grounded Visual STEM Perception for MLLMs
Mar 11, 2026When MLLMs fail at Science, Technology, Engineering, and Mathematics (STEM) visual reasoning, a fundamental question arises: is it due to perceptual deficiencies or reasoning limitations? Through systematic scaling analysis that independently scales perception and reasoning components, we uncover a critical insight: scaling perception consistently outperforms scaling reasoning. This reveals perception as the true lever limiting current STEM visual reasoning. Motivated by this insight, our work focuses on systematically enhancing the perception capabilities of MLLMs by establishing code as a powerful perceptual medium--executable code provides precise semantics that naturally align with the structured nature of STEM visuals. Specifically, we construct ICC-1M, a large-scale dataset comprising 1M Image-Caption-Code triplets that materializes this code-as-perception paradigm through two complementary approaches: (1) Code-Grounded Caption Generation treats executable code as ground truth for image captions, eliminating the hallucinations inherent in existing knowledge distillation methods; (2) STEM Image-to-Code Translation prompts models to generate reconstruction code, mitigating the ambiguity of natural language for perception enhancement. To validate this paradigm, we further introduce STEM2Code-Eval, a novel benchmark that directly evaluates visual perception in STEM domains. Unlike existing work relying on problem-solving accuracy as a proxy that only measures problem-relevant understanding, our benchmark requires comprehensive visual comprehension through executable code generation for image reconstruction, providing deterministic and verifiable assessment. Code is available at https://github.com/TongkunGuan/Qwen-CodePercept.
RealX3D: A Physically-Degraded 3D Benchmark for Multi-view Visual Restoration and Reconstruction
Dec 29, 2025We introduce RealX3D, a real-capture benchmark for multi-view visual restoration and 3D reconstruction under diverse physical degradations. RealX3D groups corruptions into four families, including illumination, scattering, occlusion, and blurring, and captures each at multiple severity levels using a unified acquisition protocol that yields pixel-aligned LQ/GT views. Each scene includes high-resolution capture, RAW images, and dense laser scans, from which we derive world-scale meshes and metric depth. Benchmarking a broad range of optimization-based and feed-forward methods shows substantial degradation in reconstruction quality under physical corruptions, underscoring the fragility of current multi-view pipelines in real-world challenging environments.
Network-Wide Traffic Flow Estimation Across Multiple Cities with Global Open Multi-Source Data: A Large-Scale Case Study in Europe and North America
Feb 06, 2025Network-wide traffic flow, which captures dynamic traffic volume on each link of a general network, is fundamental to smart mobility applications. However, the observed traffic flow from sensors is usually limited across the entire network due to the associated high installation and maintenance costs. To address this issue, existing research uses various supplementary data sources to compensate for insufficient sensor coverage and estimate the unobserved traffic flow. Although these studies have shown promising results, the inconsistent availability and quality of supplementary data across cities make their methods typically face a trade-off challenge between accuracy and generality. In this research, we first time advocate using the Global Open Multi-Source (GOMS) data within an advanced deep learning framework to break the trade-off. The GOMS data primarily encompass geographical and demographic information, including road topology, building footprints, and population density, which can be consistently collected across cities. More importantly, these GOMS data are either causes or consequences of transportation activities, thereby creating opportunities for accurate network-wide flow estimation. Furthermore, we use map images to represent GOMS data, instead of traditional tabular formats, to capture richer and more comprehensive geographical and demographic information. To address multi-source data fusion, we develop an attention-based graph neural network that effectively extracts and synthesizes information from GOMS maps while simultaneously capturing spatiotemporal traffic dynamics from observed traffic data. A large-scale case study across 15 cities in Europe and North America was conducted. The results demonstrate stable and satisfactory estimation accuracy across these cities, which suggests that the trade-off challenge can be successfully addressed using our approach.
Fox-1 Technical Report
Nov 08, 2024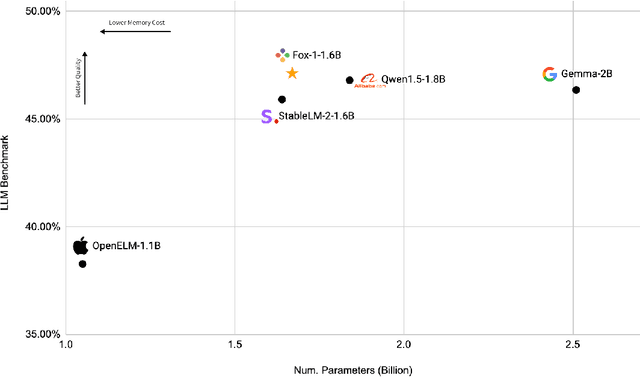

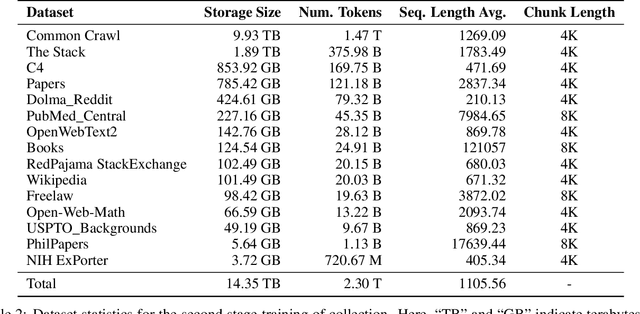
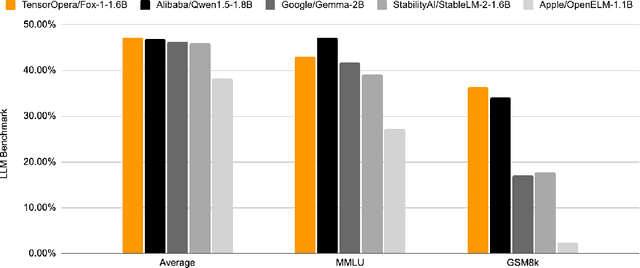
We present Fox-1, a series of small language models (SLMs) consisting of Fox-1-1.6B and Fox-1-1.6B-Instruct-v0.1. These models are pre-trained on 3 trillion tokens of web-scraped document data and fine-tuned with 5 billion tokens of instruction-following and multi-turn conversation data. Aiming to improve the pre-training efficiency, Fox-1-1.6B model introduces a novel 3-stage data curriculum across all the training data with 2K-8K sequence length. In architecture design, Fox-1 features a deeper layer structure, an expanded vocabulary, and utilizes Grouped Query Attention (GQA), offering a performant and efficient architecture compared to other SLMs. Fox-1 achieves better or on-par performance in various benchmarks compared to StableLM-2-1.6B, Gemma-2B, Qwen1.5-1.8B, and OpenELM1.1B, with competitive inference speed and throughput. The model weights have been released under the Apache 2.0 license, where we aim to promote the democratization of LLMs and make them fully accessible to the whole open-source community.
Alopex: A Computational Framework for Enabling On-Device Function Calls with LLMs
Nov 07, 2024



The rapid advancement of Large Language Models (LLMs) has led to their increased integration into mobile devices for personalized assistance, which enables LLMs to call external API functions to enhance their performance. However, challenges such as data scarcity, ineffective question formatting, and catastrophic forgetting hinder the development of on-device LLM agents. To tackle these issues, we propose Alopex, a framework that enables precise on-device function calls using the Fox LLM. Alopex introduces a logic-based method for generating high-quality training data and a novel ``description-question-output'' format for fine-tuning, reducing risks of function information leakage. Additionally, a data mixing strategy is used to mitigate catastrophic forgetting, combining function call data with textbook datasets to enhance performance in various tasks. Experimental results show that Alopex improves function call accuracy and significantly reduces catastrophic forgetting, providing a robust solution for integrating function call capabilities into LLMs without manual intervention.
PolyRouter: A Multi-LLM Querying System
Aug 26, 2024



With the rapid growth of Large Language Models (LLMs) across various domains, numerous new LLMs have emerged, each possessing domain-specific expertise. This proliferation has highlighted the need for quick, high-quality, and cost-effective LLM query response methods. Yet, no single LLM exists to efficiently balance this trilemma. Some models are powerful but extremely costly, while others are fast and inexpensive but qualitatively inferior. To address this challenge, we present PolyRouter, a non-monolithic LLM querying system that seamlessly integrates various LLM experts into a single query interface and dynamically routes incoming queries to the most high-performant expert based on query's requirements. Through extensive experiments, we demonstrate that when compared to standalone expert models, PolyRouter improves query efficiency by up to 40%, and leads to significant cost reductions of up to 30%, while maintaining or enhancing model performance by up to 10%.
ScaleLLM: A Resource-Frugal LLM Serving Framework by Optimizing End-to-End Efficiency
Jul 23, 2024Large language models (LLMs) have surged in popularity and are extensively used in commercial applications, where the efficiency of model serving is crucial for the user experience. Most current research focuses on optimizing individual sub-procedures, e.g. local inference and communication, however, there is no comprehensive framework that provides a holistic system view for optimizing LLM serving in an end-to-end manner. In this work, we conduct a detailed analysis to identify major bottlenecks that impact end-to-end latency in LLM serving systems. Our analysis reveals that a comprehensive LLM serving endpoint must address a series of efficiency bottlenecks that extend beyond LLM inference. We then propose ScaleLLM, an optimized system for resource-efficient LLM serving. Our extensive experiments reveal that with 64 concurrent requests, ScaleLLM achieves a 4.3x speed up over vLLM and outperforms state-of-the-arts with 1.5x higher throughput.