 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlopex: A Computational Framework for Enabling On-Device Function Calls with LLMs
Nov 07, 2024



The rapid advancement of Large Language Models (LLMs) has led to their increased integration into mobile devices for personalized assistance, which enables LLMs to call external API functions to enhance their performance. However, challenges such as data scarcity, ineffective question formatting, and catastrophic forgetting hinder the development of on-device LLM agents. To tackle these issues, we propose Alopex, a framework that enables precise on-device function calls using the Fox LLM. Alopex introduces a logic-based method for generating high-quality training data and a novel ``description-question-output'' format for fine-tuning, reducing risks of function information leakage. Additionally, a data mixing strategy is used to mitigate catastrophic forgetting, combining function call data with textbook datasets to enhance performance in various tasks. Experimental results show that Alopex improves function call accuracy and significantly reduces catastrophic forgetting, providing a robust solution for integrating function call capabilities into LLMs without manual intervention.
PolyRouter: A Multi-LLM Querying System
Aug 26, 2024



With the rapid growth of Large Language Models (LLMs) across various domains, numerous new LLMs have emerged, each possessing domain-specific expertise. This proliferation has highlighted the need for quick, high-quality, and cost-effective LLM query response methods. Yet, no single LLM exists to efficiently balance this trilemma. Some models are powerful but extremely costly, while others are fast and inexpensive but qualitatively inferior. To address this challenge, we present PolyRouter, a non-monolithic LLM querying system that seamlessly integrates various LLM experts into a single query interface and dynamically routes incoming queries to the most high-performant expert based on query's requirements. Through extensive experiments, we demonstrate that when compared to standalone expert models, PolyRouter improves query efficiency by up to 40%, and leads to significant cost reductions of up to 30%, while maintaining or enhancing model performance by up to 10%.
ScaleLLM: A Resource-Frugal LLM Serving Framework by Optimizing End-to-End Efficiency
Jul 23, 2024Large language models (LLMs) have surged in popularity and are extensively used in commercial applications, where the efficiency of model serving is crucial for the user experience. Most current research focuses on optimizing individual sub-procedures, e.g. local inference and communication, however, there is no comprehensive framework that provides a holistic system view for optimizing LLM serving in an end-to-end manner. In this work, we conduct a detailed analysis to identify major bottlenecks that impact end-to-end latency in LLM serving systems. Our analysis reveals that a comprehensive LLM serving endpoint must address a series of efficiency bottlenecks that extend beyond LLM inference. We then propose ScaleLLM, an optimized system for resource-efficient LLM serving. Our extensive experiments reveal that with 64 concurrent requests, ScaleLLM achieves a 4.3x speed up over vLLM and outperforms state-of-the-arts with 1.5x higher throughput.
FedMLSecurity: A Benchmark for Attacks and Defenses in Federated Learning and LLMs
Jun 08, 2023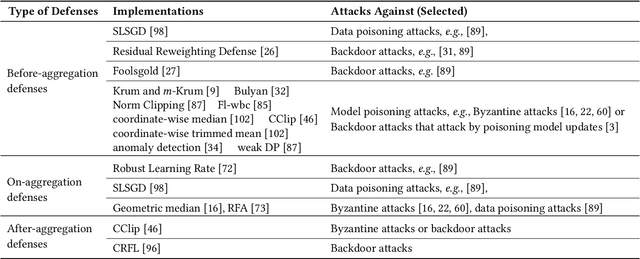

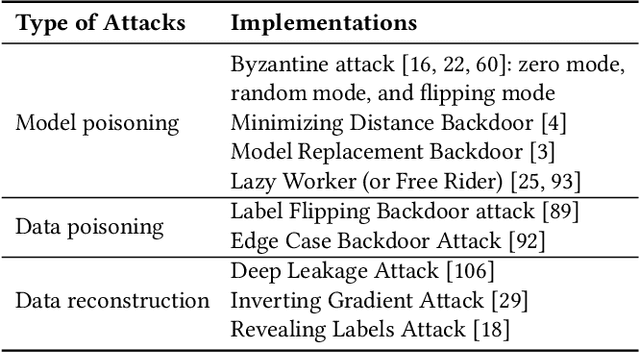
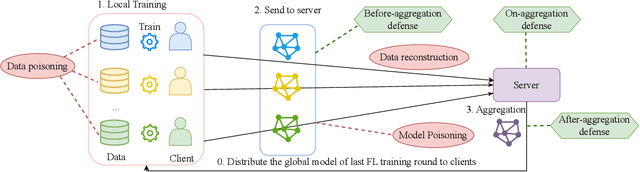
This paper introduces FedMLSecurity, a benchmark that simulates adversarial attacks and corresponding defense mechanisms in Federated Learning (FL). As an integral module of the open-sourced library FedML that facilitates FL algorithm development and performance comparison, FedMLSecurity enhances the security assessment capacity of FedML. FedMLSecurity comprises two principal components: FedMLAttacker, which simulates attacks injected into FL training, and FedMLDefender, which emulates defensive strategies designed to mitigate the impacts of the attacks. FedMLSecurity is open-sourced 1 and is customizable to a wide range of machine learning models (e.g., Logistic Regression, ResNet, GAN, etc.) and federated optimizers (e.g., FedAVG, FedOPT, FedNOVA, etc.). Experimental evaluations in this paper also demonstrate the ease of application of FedMLSecurity to Large Language Models (LLMs), further reinforcing its versatility and practical utility in various scenarios.