 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Driven 3D Facial Animation from In-the-Wild Videos
Paper and Code

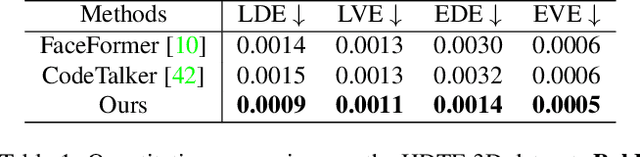
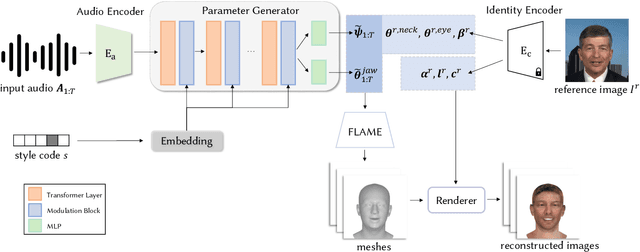
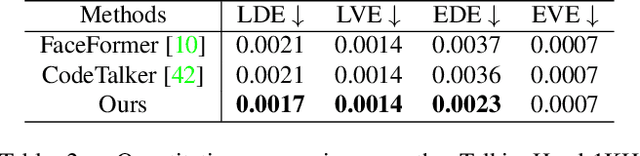
Given an arbitrary audio clip, audio-driven 3D facial animation aims to generate lifelike lip motions and facial expressions for a 3D head. Existing methods typically rely on training their models using limited public 3D datasets that contain a restricted number of audio-3D scan pairs. Consequently, their generalization capability remains limited. In this paper, we propose a novel method that leverages in-the-wild 2D talking-head videos to train our 3D facial animation model. The abundance of easily accessible 2D talking-head videos equips our model with a robust generalization capability. By combining these videos with existing 3D face reconstruction methods, our model excels in generating consistent and high-fidelity lip synchronization. Additionally, our model proficiently captures the speaking styles of different individuals, allowing it to generate 3D talking-heads with distinct personal styles. Extensive qualitative and quantitative experimental results demonstrate the superiority of our method.