 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Synthesis for Low-Light Image Denoising with Diffusion Models
Mar 14, 2025

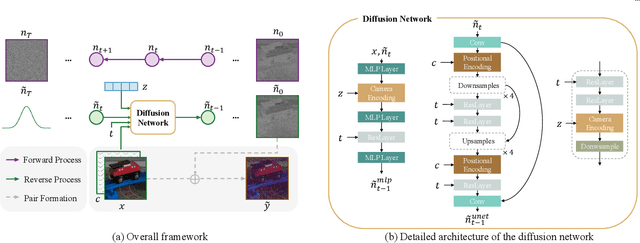

Low-light photography produces images with low signal-to-noise ratios due to limited photons. In such conditions, common approximations like the Gaussian noise model fall short, and many denoising techniques fail to remove noise effectively. Although deep-learning methods perform well, they require large datasets of paired images that are impractical to acquire. As a remedy, synthesizing realistic low-light noise has gained significant attention. In this paper, we investigate the ability of diffusion models to capture the complex distribution of low-light noise. We show that a naive application of conventional diffusion models is inadequate for this task and propose three key adaptations that enable high-precision noise generation without calibration or post-processing: a two-branch architecture to better model signal-dependent and signal-independent noise, the incorporation of positional information to capture fixed-pattern noise, and a tailored diffusion noise schedule. Consequently, our model enables the generation of large datasets for training low-light denoising networks, leading to state-of-the-art performance. Through comprehensive analysis, including statistical evaluation and noise decomposition, we provide deeper insights into the characteristics of the generated data.
Audio-Driven 3D Facial Animation from In-the-Wild Videos
Jun 20, 2023
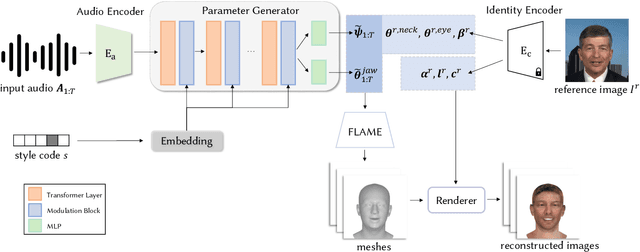
Given an arbitrary audio clip, audio-driven 3D facial animation aims to generate lifelike lip motions and facial expressions for a 3D head. Existing methods typically rely on training their models using limited public 3D datasets that contain a restricted number of audio-3D scan pairs. Consequently, their generalization capability remains limited. In this paper, we propose a novel method that leverages in-the-wild 2D talking-head videos to train our 3D facial animation model. The abundance of easily accessible 2D talking-head videos equips our model with a robust generalization capability. By combining these videos with existing 3D face reconstruction methods, our model excels in generating consistent and high-fidelity lip synchronization. Additionally, our model proficiently captures the speaking styles of different individuals, allowing it to generate 3D talking-heads with distinct personal styles. Extensive qualitative and quantitative experimental results demonstrate the superiority of our method.
Video Frame Interpolation with Transformer
May 15, 2022
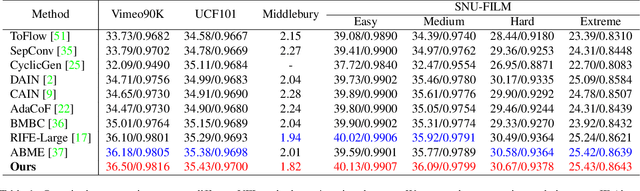
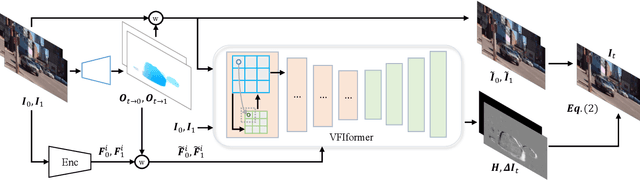

Video frame interpolation (VFI), which aims to synthesize intermediate frames of a video, has made remarkable progress with development of deep convolutional networks over past years. Existing methods built upon convolutional networks generally face challenges of handling large motion due to the locality of convolution operations. To overcome this limitation, we introduce a novel framework, which takes advantage of Transformer to model long-range pixel correlation among video frames. Further, our network is equipped with a novel cross-scale window-based attention mechanism, where cross-scale windows interact with each other. This design effectively enlarges the receptive field and aggregates multi-scale information. Extensive quantitative and qualitative experiments demonstrate that our method achieves new state-of-the-art results on various benchmarks.
Revisiting Temporal Alignment for Video Restoration
Dec 01, 2021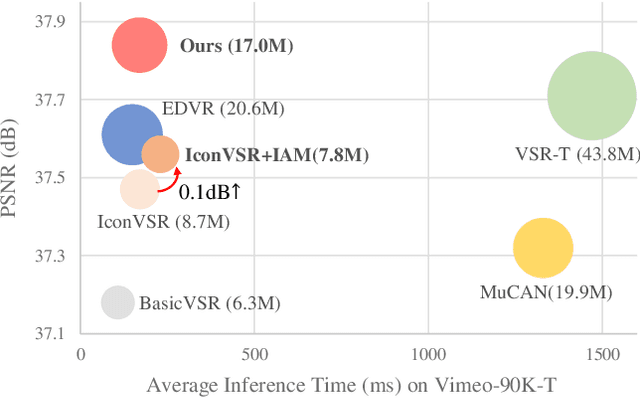

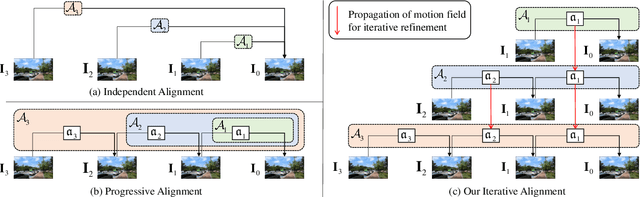
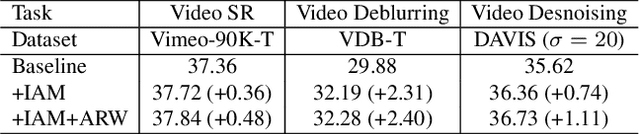
Long-range temporal alignment is critical yet challenging for video restoration tasks. Recently, some works attempt to divide the long-range alignment into several sub-alignments and handle them progressively. Although this operation is helpful in modeling distant correspondences, error accumulation is inevitable due to the propagation mechanism. In this work, we present a novel, generic iterative alignment module which employs a gradual refinement scheme for sub-alignments, yielding more accurate motion compensation. To further enhance the alignment accuracy and temporal consistency, we develop a non-parametric re-weighting method, where the importance of each neighboring frame is adaptively evaluated in a spatial-wise way for aggregation. By virtue of the proposed strategies, our model achieves state-of-the-art performance on multiple benchmarks across a range of video restoration tasks including video super-resolution, denoising and deblurring. Our project is available in \url{https://github.com/redrock303/Revisiting-Temporal-Alignment-for-Video-Restoration.git}.
MASA-SR: Matching Acceleration and Spatial Adaptation for Reference-Based Image Super-Resolution
Jun 04, 2021
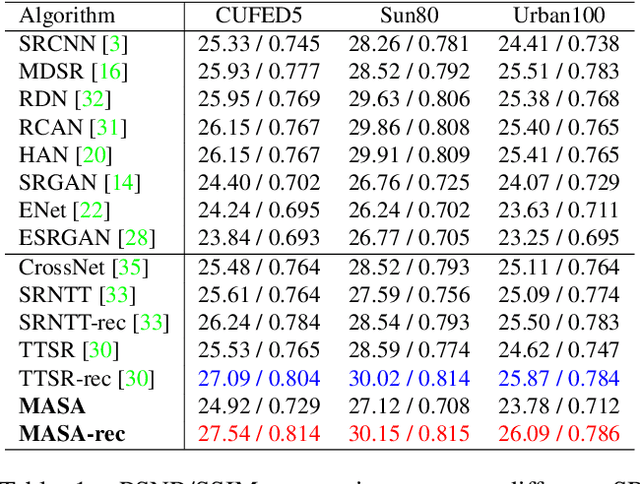
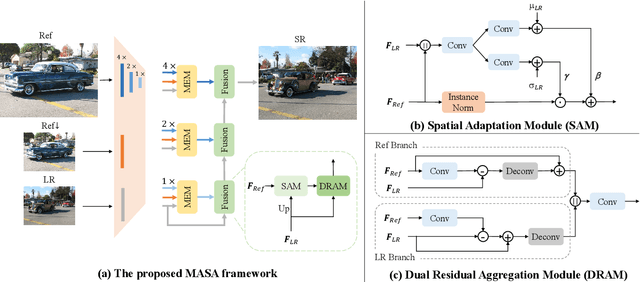

Reference-based image super-resolution (RefSR) has shown promising success in recovering high-frequency details by utilizing an external reference image (Ref). In this task, texture details are transferred from the Ref image to the low-resolution (LR) image according to their point- or patch-wise correspondence. Therefore, high-quality correspondence matching is critical. It is also desired to be computationally efficient. Besides, existing RefSR methods tend to ignore the potential large disparity in distributions between the LR and Ref images, which hurts the effectiveness of the information utilization. In this paper, we propose the MASA network for RefSR, where two novel modules are designed to address these problems. The proposed Match & Extraction Module significantly reduces the computational cost by a coarse-to-fine correspondence matching scheme. The Spatial Adaptation Module learns the difference of distribution between the LR and Ref images, and remaps the distribution of Ref features to that of LR features in a spatially adaptive way. This scheme makes the network robust to handle different reference images. Extensive quantitative and qualitative experiments validate the effectiveness of our proposed model.
Best-Buddy GANs for Highly Detailed Image Super-Resolution
Mar 29, 2021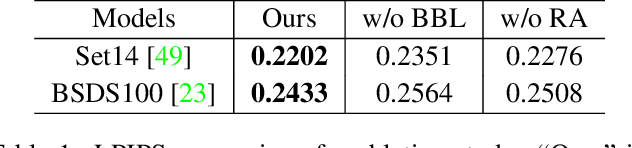


We consider the single image super-resolution (SISR) problem, where a high-resolution (HR) image is generated based on a low-resolution (LR) input. Recently, generative adversarial networks (GANs) become popular to hallucinate details. Most methods along this line rely on a predefined single-LR-single-HR mapping, which is not flexible enough for the SISR task. Also, GAN-generated fake details may often undermine the realism of the whole image. We address these issues by proposing best-buddy GANs (Beby-GAN) for rich-detail SISR. Relaxing the immutable one-to-one constraint, we allow the estimated patches to dynamically seek the best supervision during training, which is beneficial to producing more reasonable details. Besides, we propose a region-aware adversarial learning strategy that directs our model to focus on generating details for textured areas adaptively. Extensive experiments justify the effectiveness of our method. An ultra-high-resolution 4K dataset is also constructed to facilitate future super-resolution research.