 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Pretrained Depth Estimation Models Help With Image Dehazing?
Aug 01, 2025Image dehazing remains a challenging problem due to the spatially varying nature of haze in real-world scenes. While existing methods have demonstrated the promise of large-scale pretrained models for image dehazing, their architecture-specific designs hinder adaptability across diverse scenarios with different accuracy and efficiency requirements. In this work, we systematically investigate the generalization capability of pretrained depth representations-learned from millions of diverse images-for image dehazing. Our empirical analysis reveals that the learned deep depth features maintain remarkable consistency across varying haze levels. Building on this insight, we propose a plug-and-play RGB-D fusion module that seamlessly integrates with diverse dehazing architectures. Extensive experiments across multiple benchmarks validate both the effectiveness and broad applicability of our approach.
Hawk: Learning to Understand Open-World Video Anomalies
May 27, 2024



Video Anomaly Detection (VAD) systems can autonomously monitor and identify disturbances, reducing the need for manual labor and associated costs. However, current VAD systems are often limited by their superficial semantic understanding of scenes and minimal user interaction. Additionally, the prevalent data scarcity in existing datasets restricts their applicability in open-world scenarios. In this paper, we introduce Hawk, a novel framework that leverages interactive large Visual Language Models (VLM) to interpret video anomalies precisely. Recognizing the difference in motion information between abnormal and normal videos, Hawk explicitly integrates motion modality to enhance anomaly identification. To reinforce motion attention, we construct an auxiliary consistency loss within the motion and video space, guiding the video branch to focus on the motion modality. Moreover, to improve the interpretation of motion-to-language, we establish a clear supervisory relationship between motion and its linguistic representation. Furthermore, we have annotated over 8,000 anomaly videos with language descriptions, enabling effective training across diverse open-world scenarios, and also created 8,000 question-answering pairs for users' open-world questions. The final results demonstrate that Hawk achieves SOTA performance, surpassing existing baselines in both video description generation and question-answering. Our codes/dataset/demo will be released at https://github.com/jqtangust/hawk.
Learning to Remove Wrinkled Transparent Film with Polarized Prior
Mar 07, 2024

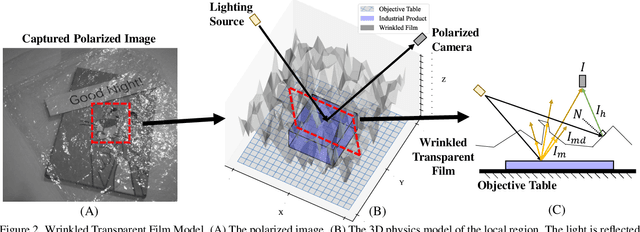

In this paper, we study a new problem, Film Removal (FR), which attempts to remove the interference of wrinkled transparent films and reconstruct the original information under films for industrial recognition systems. We first physically model the imaging of industrial materials covered by the film. Considering the specular highlight from the film can be effectively recorded by the polarized camera, we build a practical dataset with polarization information containing paired data with and without transparent film. We aim to remove interference from the film (specular highlights and other degradations) with an end-to-end framework. To locate the specular highlight, we use an angle estimation network to optimize the polarization angle with the minimized specular highlight. The image with minimized specular highlight is set as a prior for supporting the reconstruction network. Based on the prior and the polarized images, the reconstruction network can decouple all degradations from the film. Extensive experiments show that our framework achieves SOTA performance in both image reconstruction and industrial downstream tasks. Our code will be released at \url{https://github.com/jqtangust/FilmRemoval}.
An Incremental Unified Framework for Small Defect Inspection
Dec 14, 2023

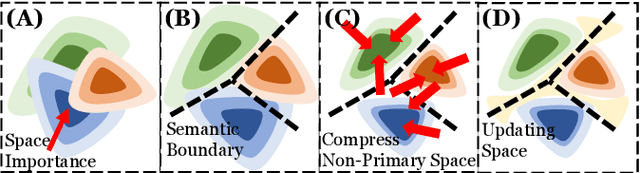
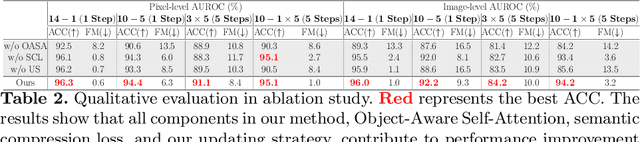
Artificial Intelligence (AI)-driven defect inspection is pivotal in industrial manufacturing. Yet, many methods, tailored to specific pipelines, grapple with diverse product portfolios and evolving processes. Addressing this, we present the Incremental Unified Framework (IUF) that can reduce the feature conflict problem when continuously integrating new objects in the pipeline, making it advantageous in object-incremental learning scenarios. Employing a state-of-the-art transformer, we introduce Object-Aware Self-Attention (OASA) to delineate distinct semantic boundaries. Semantic Compression Loss (SCL) is integrated to optimize non-primary semantic space, enhancing network adaptability for novel objects. Additionally, we prioritize retaining the features of established objects during weight updates. Demonstrating prowess in both image and pixel-level defect inspection, our approach achieves state-of-the-art performance, proving indispensable for dynamic and scalable industrial inspections. Our code will be released at https://github.com/jqtangust/IUF.
Video Frame Interpolation with Transformer
May 15, 2022
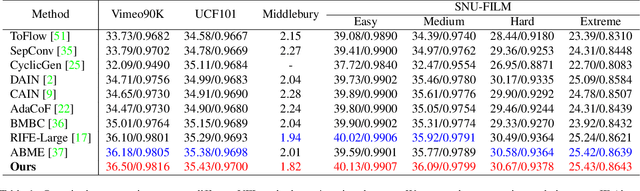
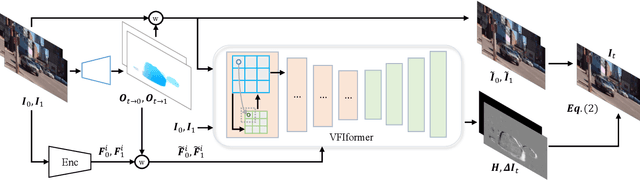

Video frame interpolation (VFI), which aims to synthesize intermediate frames of a video, has made remarkable progress with development of deep convolutional networks over past years. Existing methods built upon convolutional networks generally face challenges of handling large motion due to the locality of convolution operations. To overcome this limitation, we introduce a novel framework, which takes advantage of Transformer to model long-range pixel correlation among video frames. Further, our network is equipped with a novel cross-scale window-based attention mechanism, where cross-scale windows interact with each other. This design effectively enlarges the receptive field and aggregates multi-scale information. Extensive quantitative and qualitative experiments demonstrate that our method achieves new state-of-the-art results on various benchmarks.
Video Instance Segmentation with a Propose-Reduce Paradigm
Mar 25, 2021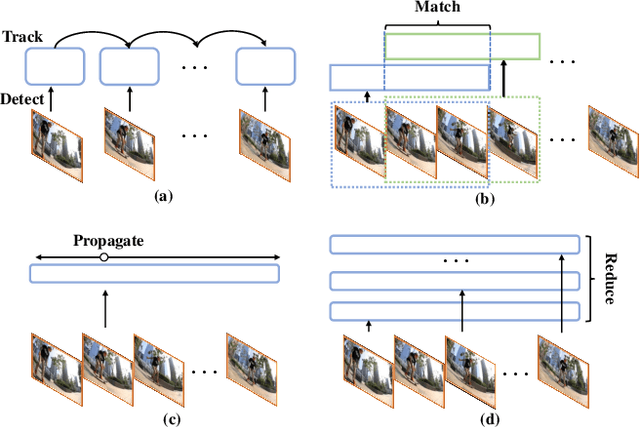
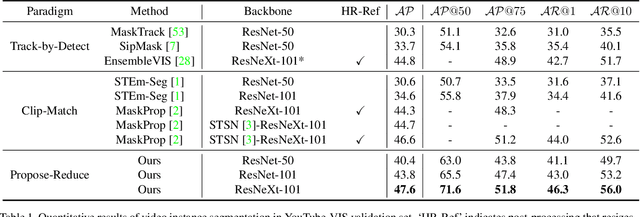
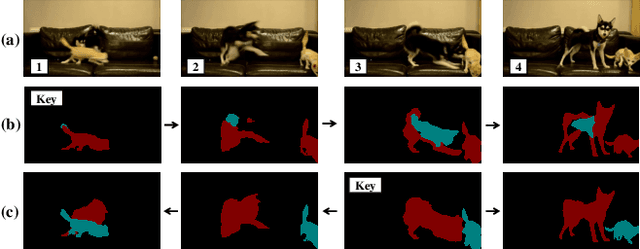
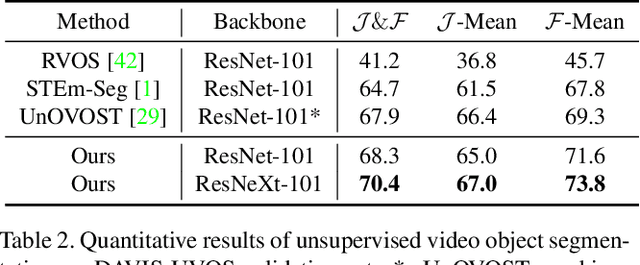
Video instance segmentation (VIS) aims to segment and associate all instances of predefined classes for each frame in videos. Prior methods usually obtain segmentation for a frame or clip first, and then merge the incomplete results by tracking or matching. These methods may cause error accumulation in the merging step. Contrarily, we propose a new paradigm -- Propose-Reduce, to generate complete sequences for input videos by a single step. We further build a sequence propagation head on the existing image-level instance segmentation network for long-term propagation. To ensure robustness and high recall of our proposed framework, multiple sequences are proposed where redundant sequences of the same instance are reduced. We achieve state-of-the-art performance on two representative benchmark datasets -- we obtain 47.6% in terms of AP on YouTube-VIS validation set and 70.4% for J&F on DAVIS-UVOS validation set.
Attribute-Driven Spontaneous Motion in Unpaired Image Translation
Jul 02, 2019
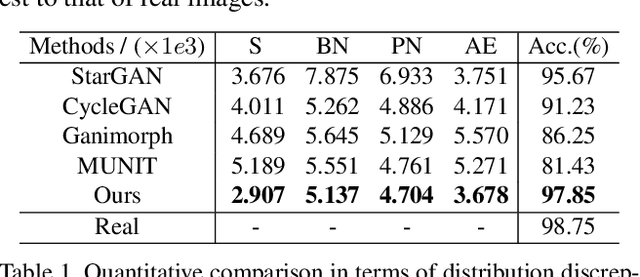
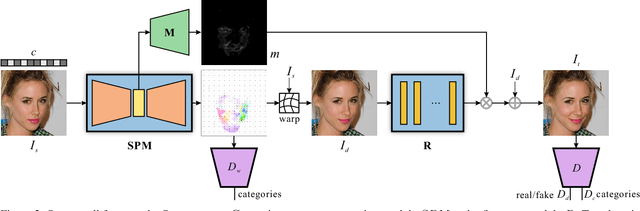
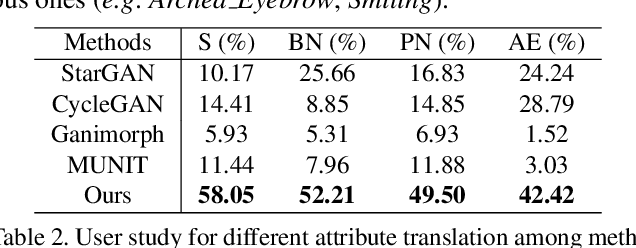
Current image translation methods, albeit effective to produce high-quality results on various applications, still do not consider much geometric transforms. We in this paper propose spontaneous motion estimation module, along with a refinement module, to learn attribute-driven deformation between source and target domains. Extensive experiments and visualization demonstrate effectiveness of these modules. We achieve promising results in unpaired image translation tasks, and enable interesting applications with spontaneous motion basis.
Landmark Assisted CycleGAN for Cartoon Face Generation
Jul 02, 2019

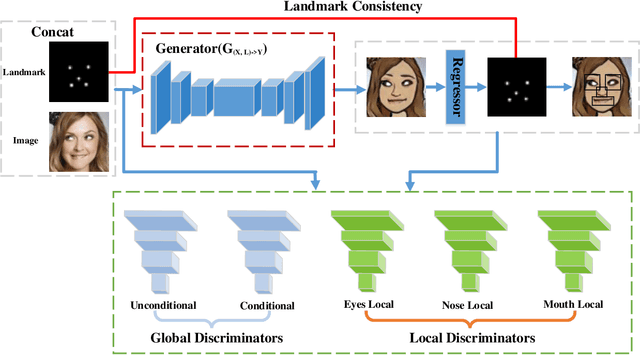
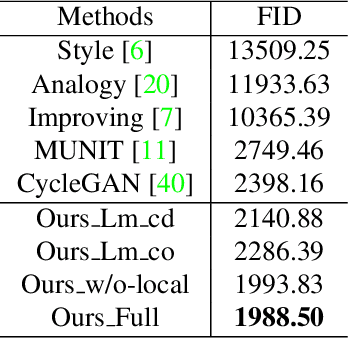
In this paper, we are interested in generating an cartoon face of a person by using unpaired training data between real faces and cartoon ones. A major challenge of this task is that the structures of real and cartoon faces are in two different domains, whose appearance differs greatly from each other. Without explicit correspondence, it is difficult to generate a high quality cartoon face that captures the essential facial features of a person. In order to solve this problem, we propose landmark assisted CycleGAN, which utilizes face landmarks to define landmark consistency loss and to guide the training of local discriminator in CycleGAN. To enforce structural consistency in landmarks, we utilize the conditional generator and discriminator. Our approach is capable to generate high-quality cartoon faces even indistinguishable from those drawn by artists and largely improves state-of-the-art.