 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Remove Wrinkled Transparent Film with Polarized Prior
Mar 07, 2024

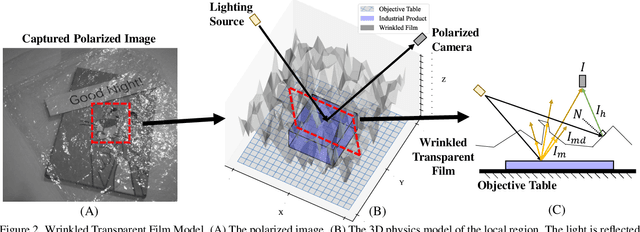

In this paper, we study a new problem, Film Removal (FR), which attempts to remove the interference of wrinkled transparent films and reconstruct the original information under films for industrial recognition systems. We first physically model the imaging of industrial materials covered by the film. Considering the specular highlight from the film can be effectively recorded by the polarized camera, we build a practical dataset with polarization information containing paired data with and without transparent film. We aim to remove interference from the film (specular highlights and other degradations) with an end-to-end framework. To locate the specular highlight, we use an angle estimation network to optimize the polarization angle with the minimized specular highlight. The image with minimized specular highlight is set as a prior for supporting the reconstruction network. Based on the prior and the polarized images, the reconstruction network can decouple all degradations from the film. Extensive experiments show that our framework achieves SOTA performance in both image reconstruction and industrial downstream tasks. Our code will be released at \url{https://github.com/jqtangust/FilmRemoval}.
An Incremental Unified Framework for Small Defect Inspection
Dec 14, 2023

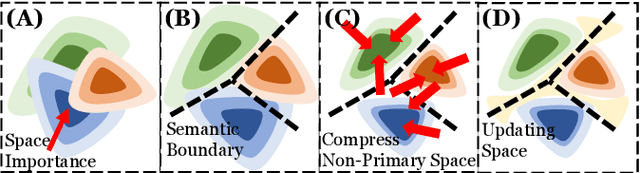
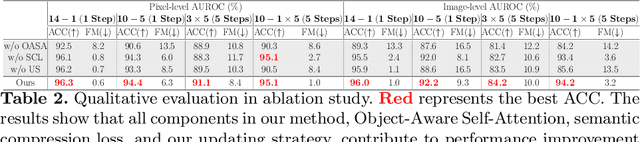
Artificial Intelligence (AI)-driven defect inspection is pivotal in industrial manufacturing. Yet, many methods, tailored to specific pipelines, grapple with diverse product portfolios and evolving processes. Addressing this, we present the Incremental Unified Framework (IUF) that can reduce the feature conflict problem when continuously integrating new objects in the pipeline, making it advantageous in object-incremental learning scenarios. Employing a state-of-the-art transformer, we introduce Object-Aware Self-Attention (OASA) to delineate distinct semantic boundaries. Semantic Compression Loss (SCL) is integrated to optimize non-primary semantic space, enhancing network adaptability for novel objects. Additionally, we prioritize retaining the features of established objects during weight updates. Demonstrating prowess in both image and pixel-level defect inspection, our approach achieves state-of-the-art performance, proving indispensable for dynamic and scalable industrial inspections. Our code will be released at https://github.com/jqtangust/IUF.
High Dynamic Range Image Reconstruction via Deep Explicit Polynomial Curve Estimation
Jul 31, 2023



Due to limited camera capacities, digital images usually have a narrower dynamic illumination range than real-world scene radiance. To resolve this problem, High Dynamic Range (HDR) reconstruction is proposed to recover the dynamic range to better represent real-world scenes. However, due to different physical imaging parameters, the tone-mapping functions between images and real radiance are highly diverse, which makes HDR reconstruction extremely challenging. Existing solutions can not explicitly clarify a corresponding relationship between the tone-mapping function and the generated HDR image, but this relationship is vital when guiding the reconstruction of HDR images. To address this problem, we propose a method to explicitly estimate the tone mapping function and its corresponding HDR image in one network. Firstly, based on the characteristics of the tone mapping function, we construct a model by a polynomial to describe the trend of the tone curve. To fit this curve, we use a learnable network to estimate the coefficients of the polynomial. This curve will be automatically adjusted according to the tone space of the Low Dynamic Range (LDR) image, and reconstruct the real HDR image. Besides, since all current datasets do not provide the corresponding relationship between the tone mapping function and the LDR image, we construct a new dataset with both synthetic and real images. Extensive experiments show that our method generalizes well under different tone-mapping functions and achieves SOTA performance.
2D3D-MatchNet: Learning to Match Keypoints Across 2D Image and 3D Point Cloud
Apr 22, 2019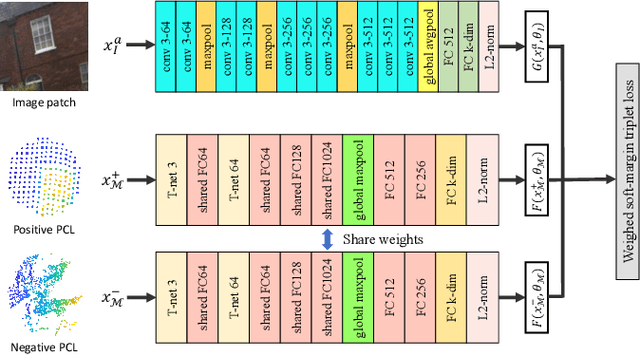
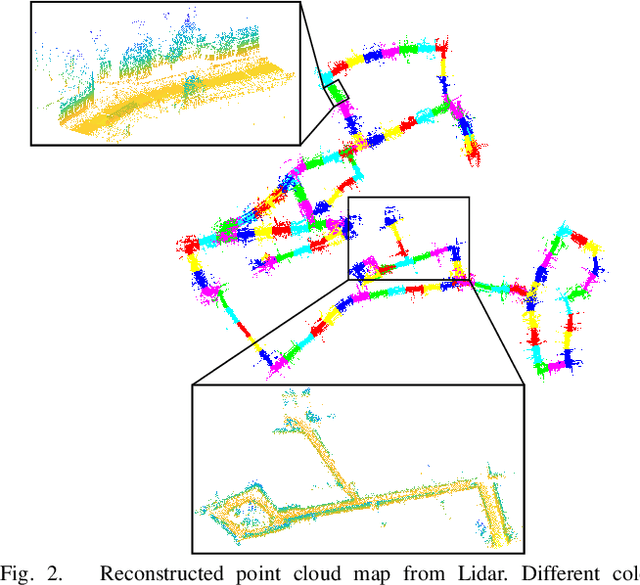

Large-scale point cloud generated from 3D sensors is more accurate than its image-based counterpart. However, it is seldom used in visual pose estimation due to the difficulty in obtaining 2D-3D image to point cloud correspondences. In this paper, we propose the 2D3D-MatchNet - an end-to-end deep network architecture to jointly learn the descriptors for 2D and 3D keypoint from image and point cloud, respectively. As a result, we are able to directly match and establish 2D-3D correspondences from the query image and 3D point cloud reference map for visual pose estimation. We create our Oxford 2D-3D Patches dataset from the Oxford Robotcar dataset with the ground truth camera poses and 2D-3D image to point cloud correspondences for training and testing the deep network. Experimental results verify the feasibility of our approach.
Project AutoVision: Localization and 3D Scene Perception for an Autonomous Vehicle with a Multi-Camera System
Mar 05, 2019


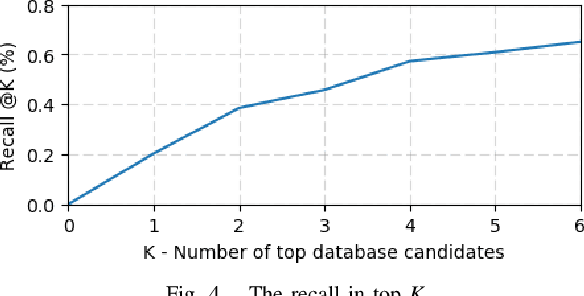
Project AutoVision aims to develop localization and 3D scene perception capabilities for a self-driving vehicle. Such capabilities will enable autonomous navigation in urban and rural environments, in day and night, and with cameras as the only exteroceptive sensors. The sensor suite employs many cameras for both 360-degree coverage and accurate multi-view stereo; the use of low-cost cameras keeps the cost of this sensor suite to a minimum. In addition, the project seeks to extend the operating envelope to include GNSS-less conditions which are typical for environments with tall buildings, foliage, and tunnels. Emphasis is placed on leveraging multi-view geometry and deep learning to enable the vehicle to localize and perceive in 3D space. This paper presents an overview of the project, and describes the sensor suite and current progress in the areas of calibration, localization, and perception.
Image-Based Geo-Localization Using Satellite Imagery
Mar 04, 2019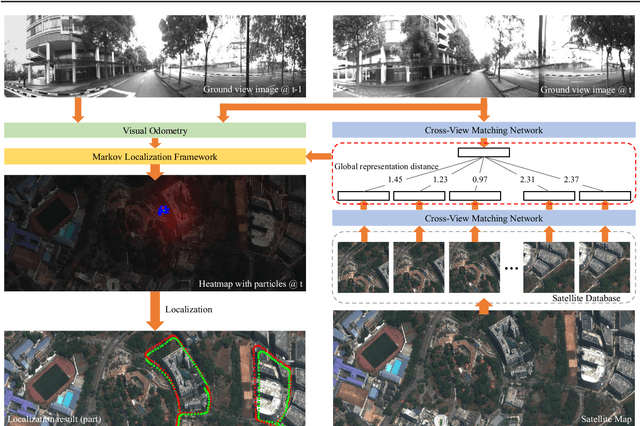

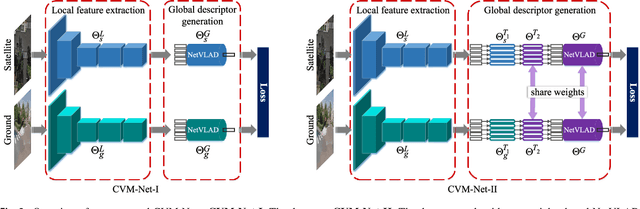

The problem of localization on a geo-referenced satellite map given a query ground view image is useful yet remains challenging due to the drastic change in viewpoint. To this end, in this paper we work on the extension of our earlier work on the Cross-View Matching Network (CVM-Net) for the ground-to-aerial image matching task since the traditional image descriptors fail due to the drastic viewpoint change. In particular, we show more extensive experimental results and analyses of the network architecture on our CVM-Net. Furthermore, we propose a Markov localization framework that enforces the temporal consistency between image frames to enhance the geo-localization results in the case where a video stream of ground view images is available. Experimental results show that our proposed Markov localization framework can continuously localize the vehicle within a small error on our Singapore dataset.