 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal2Sim or Sim2Real: Robotics Visual Insertion using Deep Reinforcement Learning and Real2Sim Policy Adaptation
Jun 06, 2022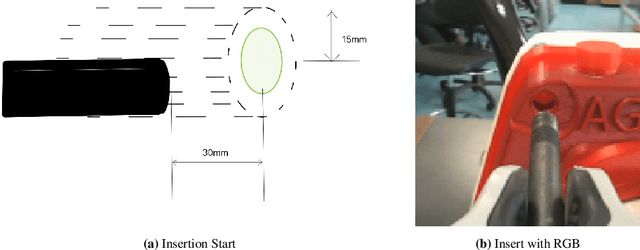
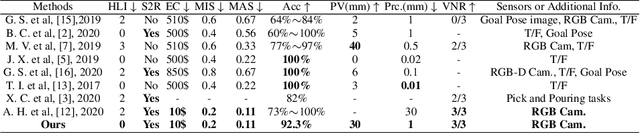
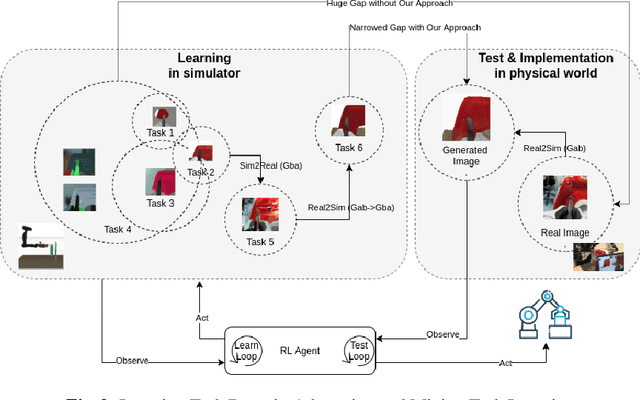

Reinforcement learning has shown a wide usage in robotics tasks, such as insertion and grasping. However, without a practical sim2real strategy, the policy trained in simulation could fail on the real task. There are also wide researches in the sim2real strategies, but most of those methods rely on heavy image rendering, domain randomization training, or tuning. In this work, we solve the insertion task using a pure visual reinforcement learning solution with minimum infrastructure requirement. We also propose a novel sim2real strategy, Real2Sim, which provides a novel and easier solution in policy adaptation. We discuss the advantage of Real2Sim compared with Sim2Real.
FIRL: Fast Imitation and Policy Reuse Learning
Mar 01, 2022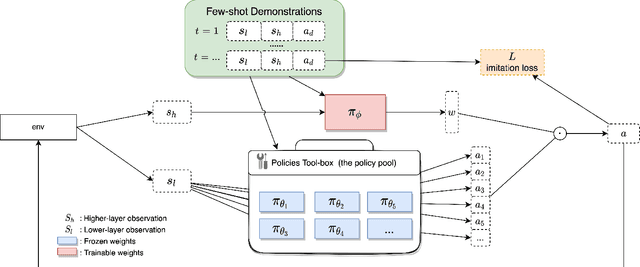
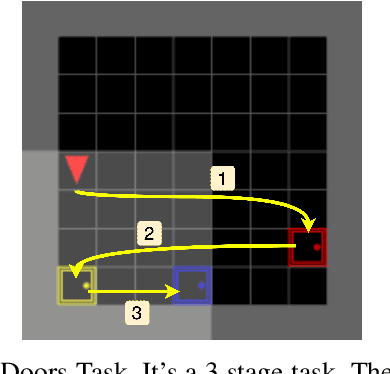
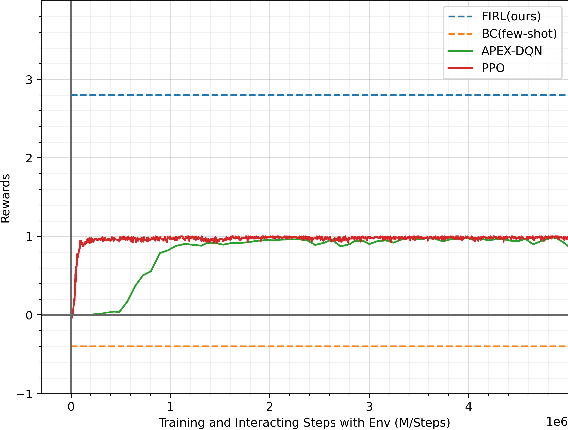
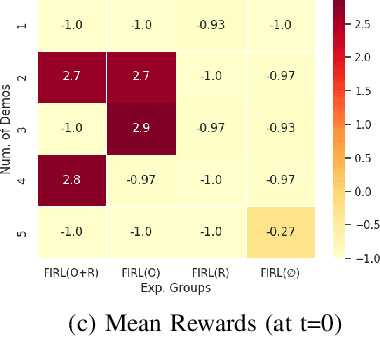
Intelligent robotics policies have been widely researched for challenging applications such as opening doors, washing dishes, and table organization. We refer to a "Policy Pool", containing skills that be easily accessed and reused. There are researches to leverage the pool, such as policy reuse, modular learning, assembly learning, transfer learning, hierarchical reinforcement learning (HRL), etc. However, most methods generally do not perform well in learning efficiency and require large datasets for training. This work focuses on enabling fast learning based on the policy pool. It should learn fast enough in one-shot or few-shot by avoiding learning from scratch. We also allow it to interact and learn from humans, but the training period should be within minutes. We propose FIRL, Fast (one-shot) Imitation, and Policy Reuse Learning. Instead of learning a new skill from scratch, it performs the one-shot imitation learning on the higher layer under a 2-layer hierarchical mechanism. Our method reduces a complex task learning to a simple regression problem that it could solve in a few offline iterations. The agent could have a good command of a new task given a one-shot demonstration. We demonstrate this method on the OpenDoors mini-grid environment, and the code is available on http://www.github.com/yiwc/firl.
Self-supervised Motion Learning from Static Images
Apr 01, 2021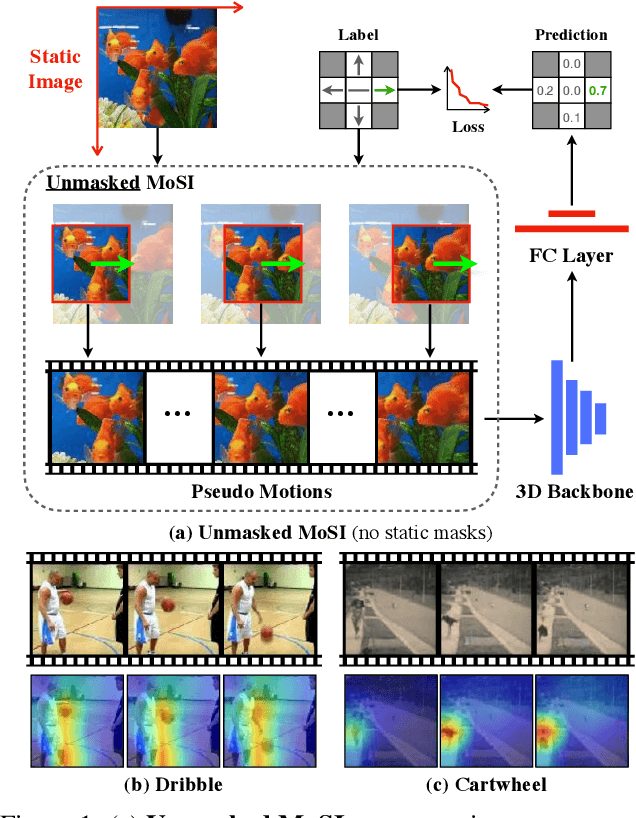
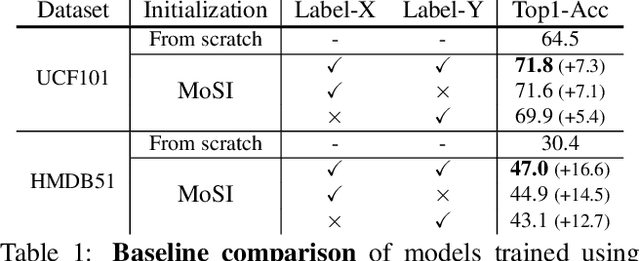
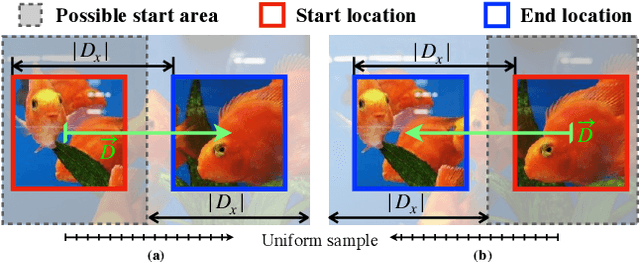
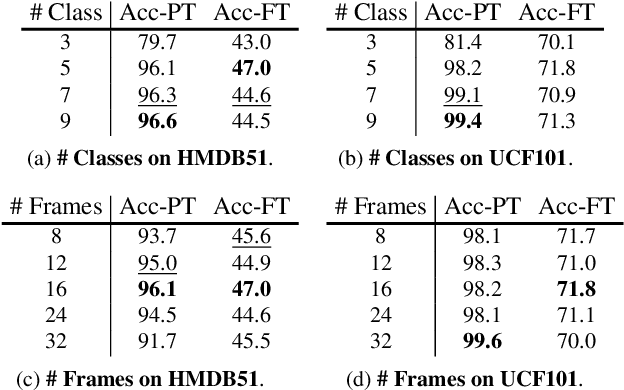
Motions are reflected in videos as the movement of pixels, and actions are essentially patterns of inconsistent motions between the foreground and the background. To well distinguish the actions, especially those with complicated spatio-temporal interactions, correctly locating the prominent motion areas is of crucial importance. However, most motion information in existing videos are difficult to label and training a model with good motion representations with supervision will thus require a large amount of human labour for annotation. In this paper, we address this problem by self-supervised learning. Specifically, we propose to learn Motion from Static Images (MoSI). The model learns to encode motion information by classifying pseudo motions generated by MoSI. We furthermore introduce a static mask in pseudo motions to create local motion patterns, which forces the model to additionally locate notable motion areas for the correct classification.We demonstrate that MoSI can discover regions with large motion even without fine-tuning on the downstream datasets. As a result, the learned motion representations boost the performance of tasks requiring understanding of complex scenes and motions, i.e., action recognition. Extensive experiments show the consistent and transferable improvements achieved by MoSI. Codes will be soon released.
2D3D-MatchNet: Learning to Match Keypoints Across 2D Image and 3D Point Cloud
Apr 22, 2019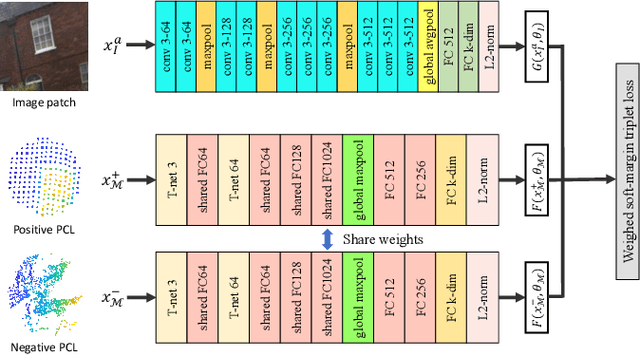
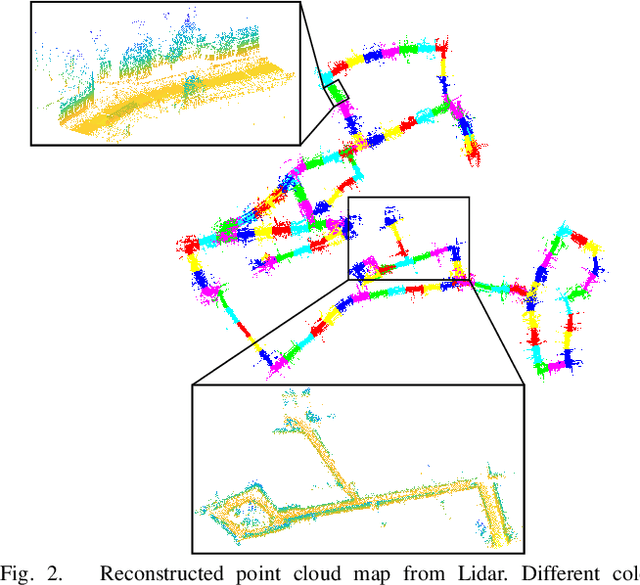

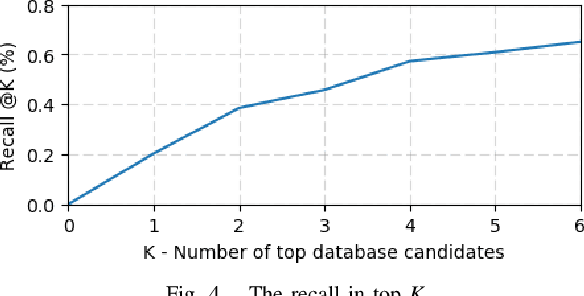
Large-scale point cloud generated from 3D sensors is more accurate than its image-based counterpart. However, it is seldom used in visual pose estimation due to the difficulty in obtaining 2D-3D image to point cloud correspondences. In this paper, we propose the 2D3D-MatchNet - an end-to-end deep network architecture to jointly learn the descriptors for 2D and 3D keypoint from image and point cloud, respectively. As a result, we are able to directly match and establish 2D-3D correspondences from the query image and 3D point cloud reference map for visual pose estimation. We create our Oxford 2D-3D Patches dataset from the Oxford Robotcar dataset with the ground truth camera poses and 2D-3D image to point cloud correspondences for training and testing the deep network. Experimental results verify the feasibility of our approach.