 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Synthesis for Low-Light Image Denoising with Diffusion Models
Paper and Code


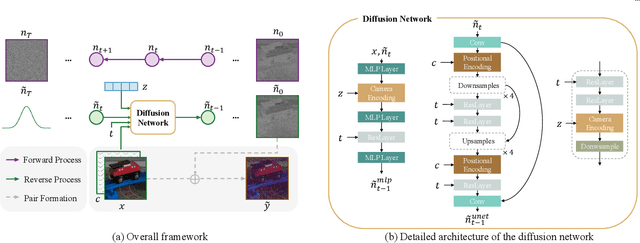

Low-light photography produces images with low signal-to-noise ratios due to limited photons. In such conditions, common approximations like the Gaussian noise model fall short, and many denoising techniques fail to remove noise effectively. Although deep-learning methods perform well, they require large datasets of paired images that are impractical to acquire. As a remedy, synthesizing realistic low-light noise has gained significant attention. In this paper, we investigate the ability of diffusion models to capture the complex distribution of low-light noise. We show that a naive application of conventional diffusion models is inadequate for this task and propose three key adaptations that enable high-precision noise generation without calibration or post-processing: a two-branch architecture to better model signal-dependent and signal-independent noise, the incorporation of positional information to capture fixed-pattern noise, and a tailored diffusion noise schedule. Consequently, our model enables the generation of large datasets for training low-light denoising networks, leading to state-of-the-art performance. Through comprehensive analysis, including statistical evaluation and noise decomposition, we provide deeper insights into the characteristics of the generated data.