 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Lightweight Salient Object Detection via Network Depth-Width Tradeoff
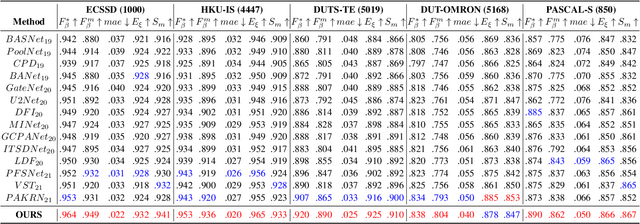
Jan 17, 2023Existing salient object detection methods often adopt deeper and wider networks for better performance, resulting in heavy computational burden and slow inference speed. This inspires us to rethink saliency detection to achieve a favorable balance between efficiency and accuracy. To this end, we design a lightweight framework while maintaining satisfying competitive accuracy. Specifically, we propose a novel trilateral decoder framework by decoupling the U-shape structure into three complementary branches, which are devised to confront the dilution of semantic context, loss of spatial structure and absence of boundary detail, respectively. Along with the fusion of three branches, the coarse segmentation results are gradually refined in structure details and boundary quality. Without adding additional learnable parameters, we further propose Scale-Adaptive Pooling Module to obtain multi-scale receptive filed. In particular, on the premise of inheriting this framework, we rethink the relationship among accuracy, parameters and speed via network depth-width tradeoff. With these insightful considerations, we comprehensively design shallower and narrower models to explore the maximum potential of lightweight SOD. Our models are purposed for different application environments: 1) a tiny version CTD-S (1.7M, 125FPS) for resource constrained devices, 2) a fast version CTD-M (12.6M, 158FPS) for speed-demanding scenarios, 3) a standard version CTD-L (26.5M, 84FPS) for high-performance platforms. Extensive experiments validate the superiority of our method, which achieves better efficiency-accuracy balance across five benchmarks.
Part-guided Relational Transformers for Fine-grained Visual Recognition
Dec 28, 2022Fine-grained visual recognition is to classify objects with visually similar appearances into subcategories, which has made great progress with the development of deep CNNs. However, handling subtle differences between different subcategories still remains a challenge. In this paper, we propose to solve this issue in one unified framework from two aspects, i.e., constructing feature-level interrelationships, and capturing part-level discriminative features. This framework, namely PArt-guided Relational Transformers (PART), is proposed to learn the discriminative part features with an automatic part discovery module, and to explore the intrinsic correlations with a feature transformation module by adapting the Transformer models from the field of natural language processing. The part discovery module efficiently discovers the discriminative regions which are highly-corresponded to the gradient descent procedure. Then the second feature transformation module builds correlations within the global embedding and multiple part embedding, enhancing spatial interactions among semantic pixels. Moreover, our proposed approach does not rely on additional part branches in the inference time and reaches state-of-the-art performance on 3 widely-used fine-grained object recognition benchmarks. Experimental results and explainable visualizations demonstrate the effectiveness of our proposed approach. The code can be found at https://github.com/iCVTEAM/PART.
Pyramid Grafting Network for One-Stage High Resolution Saliency Detection
Apr 12, 2022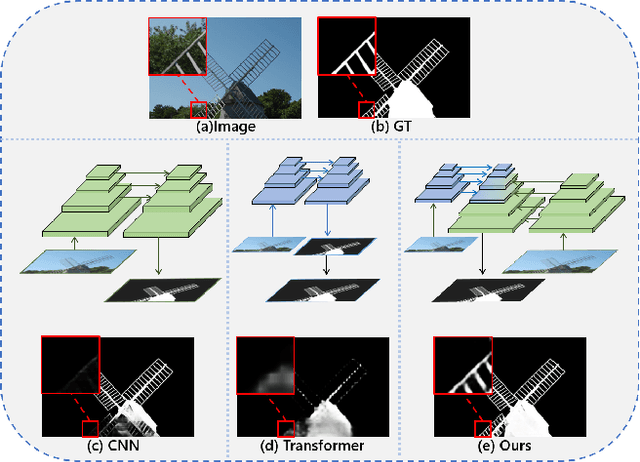


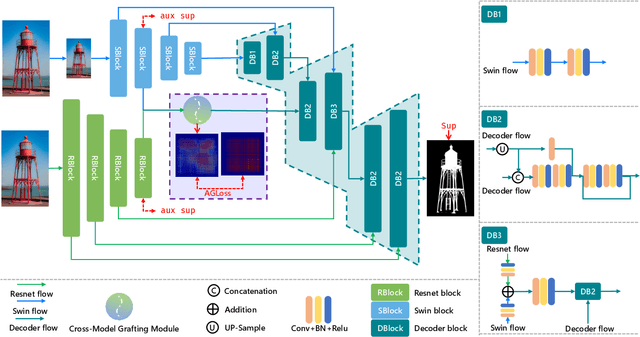
Recent salient object detection (SOD) methods based on deep neural network have achieved remarkable performance. However, most of existing SOD models designed for low-resolution input perform poorly on high-resolution images due to the contradiction between the sampling depth and the receptive field size. Aiming at resolving this contradiction, we propose a novel one-stage framework called Pyramid Grafting Network (PGNet), using transformer and CNN backbone to extract features from different resolution images independently and then graft the features from transformer branch to CNN branch. An attention-based Cross-Model Grafting Module (CMGM) is proposed to enable CNN branch to combine broken detailed information more holistically, guided by different source feature during decoding process. Moreover, we design an Attention Guided Loss (AGL) to explicitly supervise the attention matrix generated by CMGM to help the network better interact with the attention from different models. We contribute a new Ultra-High-Resolution Saliency Detection dataset UHRSD, containing 5,920 images at 4K-8K resolutions. To our knowledge, it is the largest dataset in both quantity and resolution for high-resolution SOD task, which can be used for training and testing in future research. Sufficient experiments on UHRSD and widely-used SOD datasets demonstrate that our method achieves superior performance compared to the state-of-the-art methods.
Receptive Field Broadening and Boosting for Salient Object Detection
Oct 15, 2021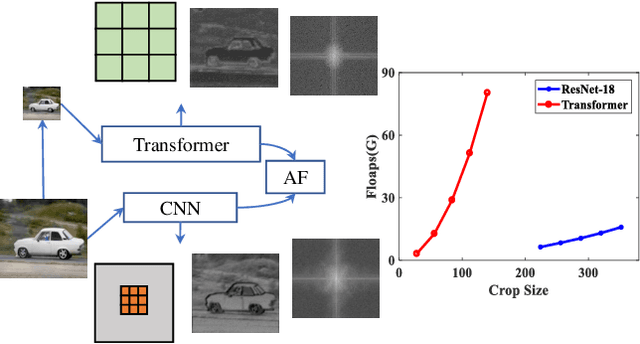
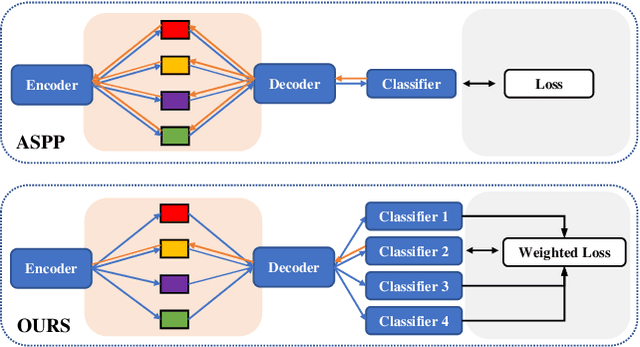
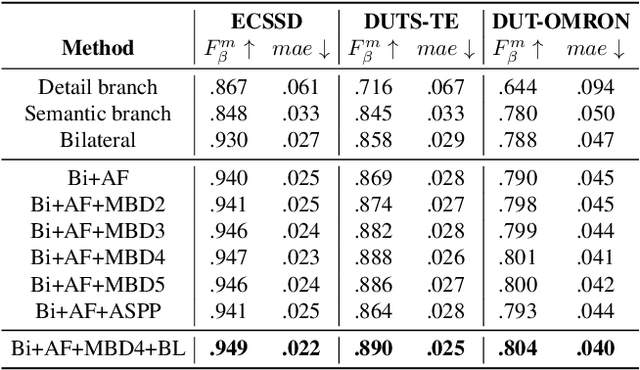
Salient object detection requires a comprehensive and scalable receptive field to locate the visually significant objects in the image. Recently, the emergence of visual transformers and multi-branch modules has significantly enhanced the ability of neural networks to perceive objects at different scales. However, compared to the traditional backbone, the calculation process of transformers is time-consuming. Moreover, different branches of the multi-branch modules could cause the same error back propagation in each training iteration, which is not conducive to extracting discriminative features. To solve these problems, we propose a bilateral network based on transformer and CNN to efficiently broaden local details and global semantic information simultaneously. Besides, a Multi-Head Boosting (MHB) strategy is proposed to enhance the specificity of different network branches. By calculating the errors of different prediction heads, each branch can separately pay more attention to the pixels that other branches predict incorrectly. Moreover, Unlike multi-path parallel training, MHB randomly selects one branch each time for gradient back propagation in a boosting way. Additionally, an Attention Feature Fusion Module (AF) is proposed to fuse two types of features according to respective characteristics. Comprehensive experiments on five benchmark datasets demonstrate that the proposed method can achieve a significant performance improvement compared with the state-of-the-art methods.
RGB-D Salient Object Detection with Ubiquitous Target Awareness
Sep 08, 2021

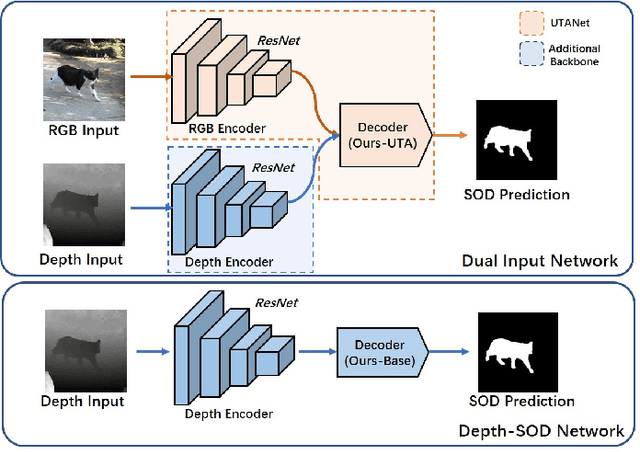

Conventional RGB-D salient object detection methods aim to leverage depth as complementary information to find the salient regions in both modalities. However, the salient object detection results heavily rely on the quality of captured depth data which sometimes are unavailable. In this work, we make the first attempt to solve the RGB-D salient object detection problem with a novel depth-awareness framework. This framework only relies on RGB data in the testing phase, utilizing captured depth data as supervision for representation learning. To construct our framework as well as achieving accurate salient detection results, we propose a Ubiquitous Target Awareness (UTA) network to solve three important challenges in RGB-D SOD task: 1) a depth awareness module to excavate depth information and to mine ambiguous regions via adaptive depth-error weights, 2) a spatial-aware cross-modal interaction and a channel-aware cross-level interaction, exploiting the low-level boundary cues and amplifying high-level salient channels, and 3) a gated multi-scale predictor module to perceive the object saliency in different contextual scales. Besides its high performance, our proposed UTA network is depth-free for inference and runs in real-time with 43 FPS. Experimental evidence demonstrates that our proposed network not only surpasses the state-of-the-art methods on five public RGB-D SOD benchmarks by a large margin, but also verifies its extensibility on five public RGB SOD benchmarks.
Is Depth Really Necessary for Salient Object Detection?
Jun 02, 2020
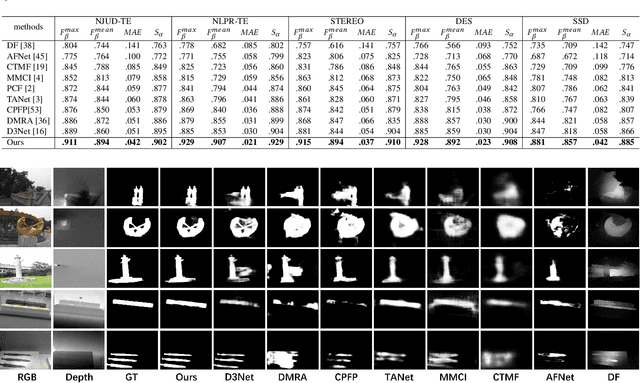
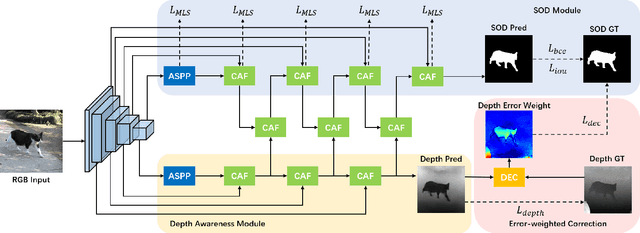
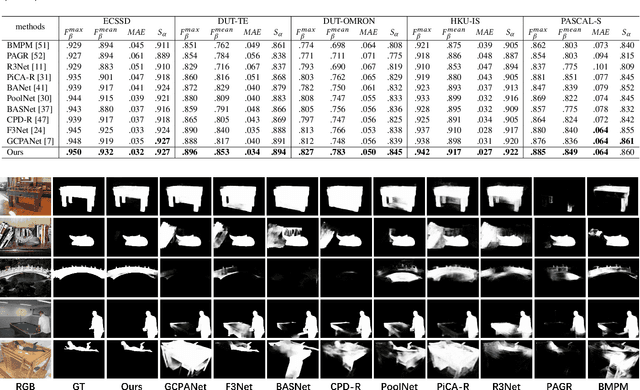
Salient object detection (SOD) is a crucial and preliminary task for many computer vision applications, which have made progress with deep CNNs. Most of the existing methods mainly rely on the RGB information to distinguish the salient objects, which faces difficulties in some complex scenarios. To solve this, many recent RGBD-based networks are proposed by adopting the depth map as an independent input and fuse the features with RGB information. Taking the advantages of RGB and RGBD methods, we propose a novel depth-aware salient object detection framework, which has following superior designs: 1) It only takes the depth information as training data while only relies on RGB information in the testing phase. 2) It comprehensively optimizes SOD features with multi-level depth-aware regularizations. 3) The depth information also serves as error-weighted map to correct the segmentation process. With these insightful designs combined, we make the first attempt in realizing an unified depth-aware framework with only RGB information as input for inference, which not only surpasses the state-of-the-art performances on five public RGB SOD benchmarks, but also surpasses the RGBD-based methods on five benchmarks by a large margin, while adopting less information and implementation light-weighted. The code and model will be publicly available.
Single Image Dehazing Using Ranking Convolutional Neural Network
Jan 15, 2020
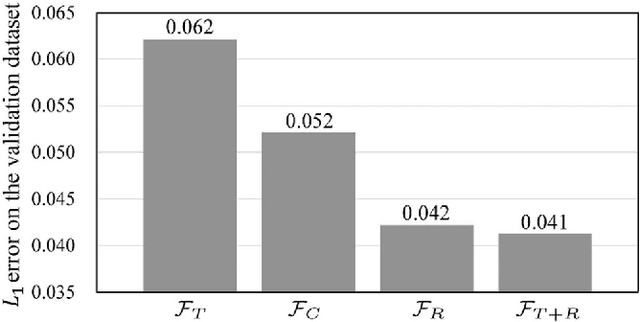
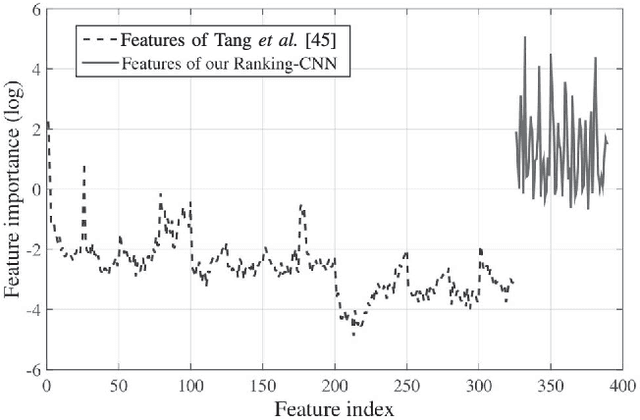
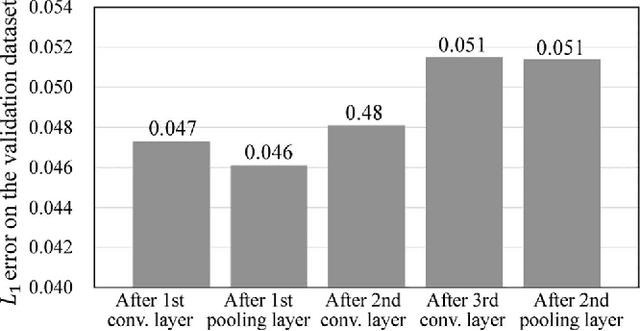
Single image dehazing, which aims to recover the clear image solely from an input hazy or foggy image, is a challenging ill-posed problem. Analysing existing approaches, the common key step is to estimate the haze density of each pixel. To this end, various approaches often heuristically designed haze-relevant features. Several recent works also automatically learn the features via directly exploiting Convolutional Neural Networks (CNN). However, it may be insufficient to fully capture the intrinsic attributes of hazy images. To obtain effective features for single image dehazing, this paper presents a novel Ranking Convolutional Neural Network (Ranking-CNN). In Ranking-CNN, a novel ranking layer is proposed to extend the structure of CNN so that the statistical and structural attributes of hazy images can be simultaneously captured. By training Ranking-CNN in a well-designed manner, powerful haze-relevant features can be automatically learned from massive hazy image patches. Based on these features, haze can be effectively removed by using a haze density prediction model trained through the random forest regression. Experimental results show that our approach outperforms several previous dehazing approaches on synthetic and real-world benchmark images. Comprehensive analyses are also conducted to interpret the proposed Ranking-CNN from both the theoretical and experimental aspects.
Shape2Motion: Joint Analysis of Motion Parts and Attributes from 3D Shapes
Mar 12, 2019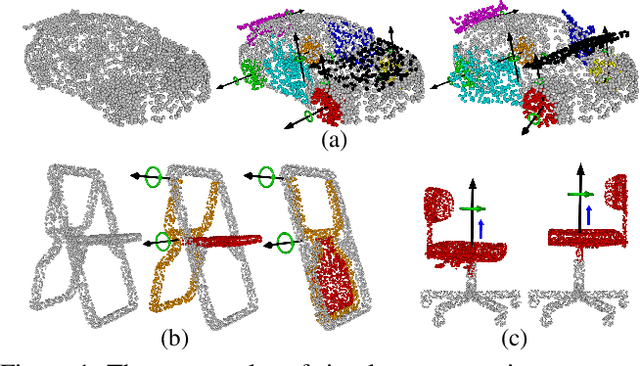
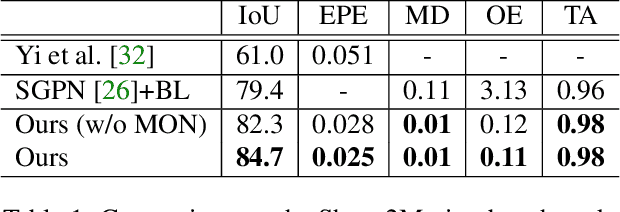
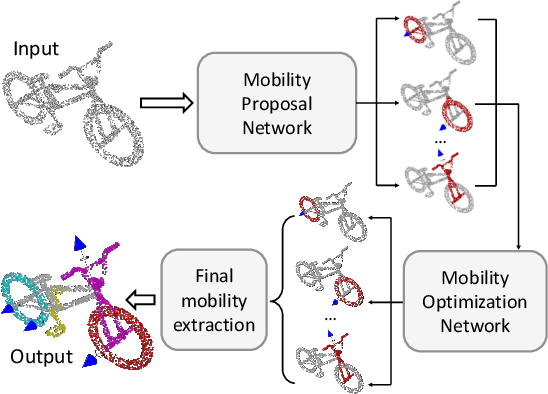
For the task of mobility analysis of 3D shapes, we propose joint analysis for simultaneous motion part segmentation and motion attribute estimation, taking a single 3D model as input. The problem is significantly different from those tackled in the existing works which assume the availability of either a pre-existing shape segmentation or multiple 3D models in different motion states. To that end, we develop Shape2Motion which takes a single 3D point cloud as input, and jointly computes a mobility-oriented segmentation and the associated motion attributes. Shape2Motion is comprised of two deep neural networks designed for mobility proposal generation and mobility optimization, respectively. The key contribution of these networks is the novel motion-driven features and losses used in both motion part segmentation and motion attribute estimation. This is based on the observation that the movement of a functional part preserves the shape structure. We evaluate Shape2Motion with a newly proposed benchmark for mobility analysis of 3D shapes. Results demonstrate that our method achieves the state-of-the-art performance both in terms of motion part segmentation and motion attribute estimation.
Complementary Segmentation of Primary Video Objects with Reversible Flows
Nov 23, 2018
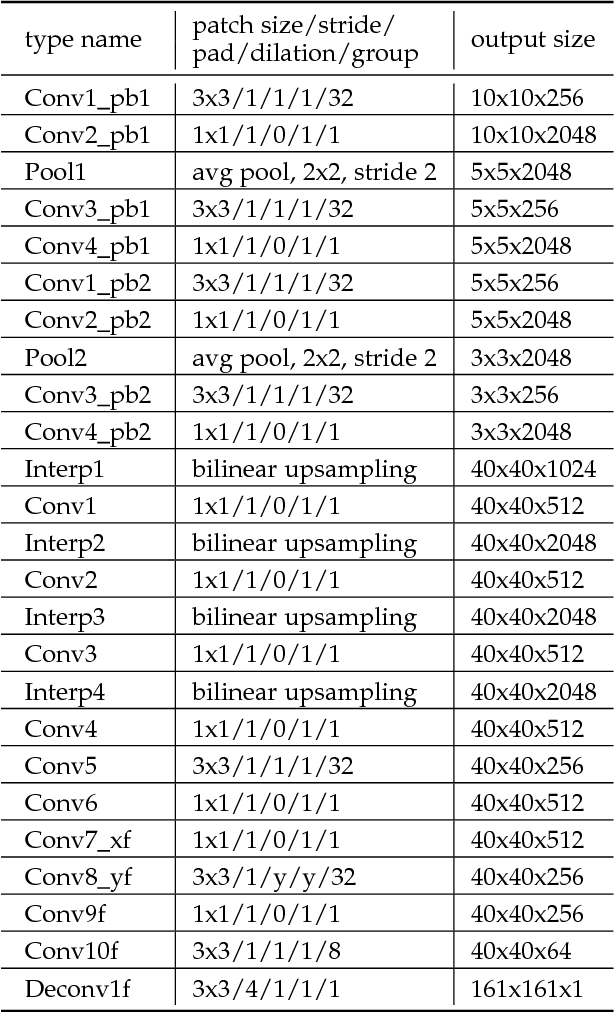
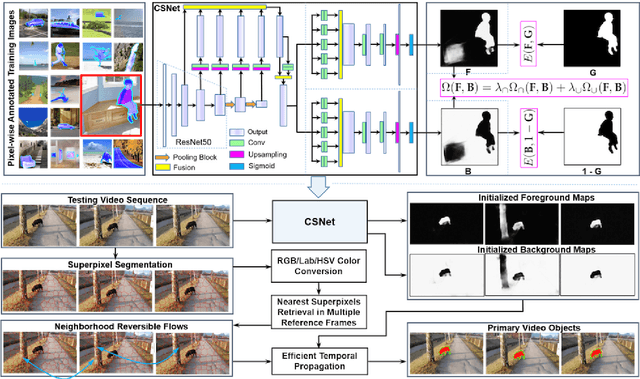
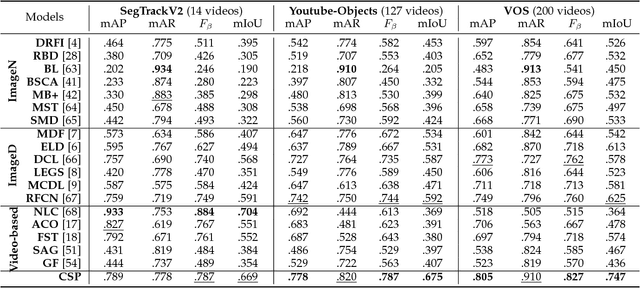
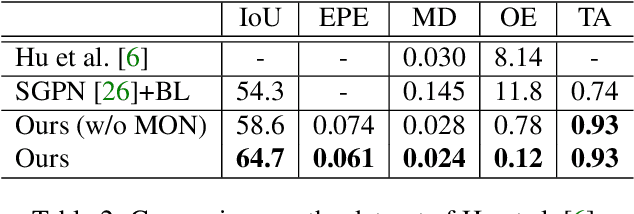
Segmenting primary objects in a video is an important yet challenging problem in computer vision, as it exhibits various levels of foreground/background ambiguities. To reduce such ambiguities, we propose a novel formulation via exploiting foreground and background context as well as their complementary constraint. Under this formulation, a unified objective function is further defined to encode each cue. For implementation, we design a Complementary Segmentation Network (CSNet) with two separate branches, which can simultaneously encode the foreground and background information along with joint spatial constraints. The CSNet is trained on massive images with manually annotated salient objects in an end-to-end manner. By applying CSNet on each video frame, the spatial foreground and background maps can be initialized. To enforce temporal consistency effectively and efficiently, we divide each frame into superpixels and construct neighborhood reversible flow that reflects the most reliable temporal correspondences between superpixels in far-away frames. With such flow, the initialized foregroundness and backgroundness can be propagated along the temporal dimension so that primary video objects gradually pop-out and distractors are well suppressed. Extensive experimental results on three video datasets show that the proposed approach achieves impressive performance in comparisons with 18 state-of-the-art models.
Learning to Group and Label Fine-Grained Shape Components
Sep 13, 2018
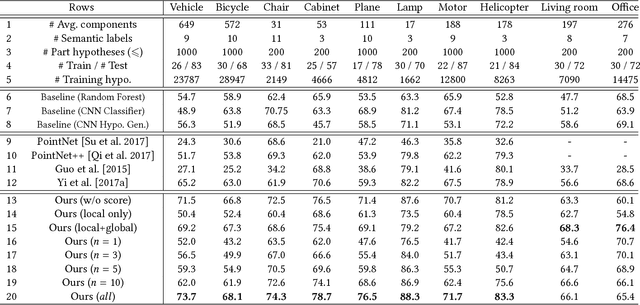


A majority of stock 3D models in modern shape repositories are assembled with many fine-grained components. The main cause of such data form is the component-wise modeling process widely practiced by human modelers. These modeling components thus inherently reflect some function-based shape decomposition the artist had in mind during modeling. On the other hand, modeling components represent an over-segmentation since a functional part is usually modeled as a multi-component assembly. Based on these observations, we advocate that labeled segmentation of stock 3D models should not overlook the modeling components and propose a learning solution to grouping and labeling of the fine-grained components. However, directly characterizing the shape of individual components for the purpose of labeling is unreliable, since they can be arbitrarily tiny and semantically meaningless. We propose to generate part hypotheses from the components based on a hierarchical grouping strategy, and perform labeling on those part groups instead of directly on the components. Part hypotheses are mid-level elements which are more probable to carry semantic information. A multiscale 3D convolutional neural network is trained to extract context-aware features for the hypotheses. To accomplish a labeled segmentation of the whole shape, we formulate higher-order conditional random fields (CRFs) to infer an optimal label assignment for all components. Extensive experiments demonstrate that our method achieves significantly robust labeling results on raw 3D models from public shape repositories. Our work also contributes the first benchmark for component-wise labeling.
* Accepted to SIGGRAPH Asia 2018. Corresponding Author: Kai Xu (kevin.kai.xu@gmail.com)