 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGB-D Salient Object Detection with Ubiquitous Target Awareness
Paper and Code
Sep 08, 2021

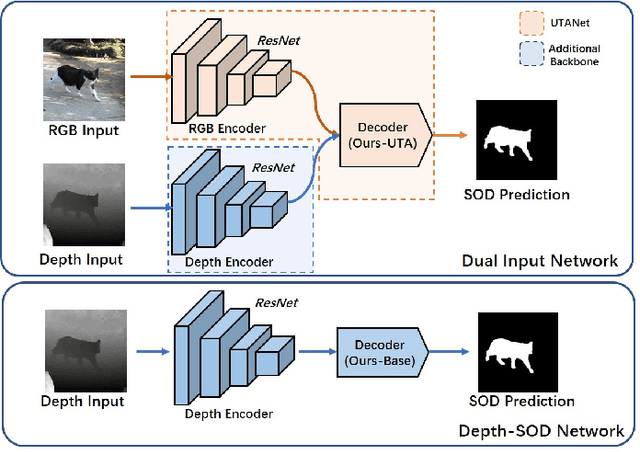

Conventional RGB-D salient object detection methods aim to leverage depth as complementary information to find the salient regions in both modalities. However, the salient object detection results heavily rely on the quality of captured depth data which sometimes are unavailable. In this work, we make the first attempt to solve the RGB-D salient object detection problem with a novel depth-awareness framework. This framework only relies on RGB data in the testing phase, utilizing captured depth data as supervision for representation learning. To construct our framework as well as achieving accurate salient detection results, we propose a Ubiquitous Target Awareness (UTA) network to solve three important challenges in RGB-D SOD task: 1) a depth awareness module to excavate depth information and to mine ambiguous regions via adaptive depth-error weights, 2) a spatial-aware cross-modal interaction and a channel-aware cross-level interaction, exploiting the low-level boundary cues and amplifying high-level salient channels, and 3) a gated multi-scale predictor module to perceive the object saliency in different contextual scales. Besides its high performance, our proposed UTA network is depth-free for inference and runs in real-time with 43 FPS. Experimental evidence demonstrates that our proposed network not only surpasses the state-of-the-art methods on five public RGB-D SOD benchmarks by a large margin, but also verifies its extensibility on five public RGB SOD benchmarks.