 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Lightweight Salient Object Detection via Network Depth-Width Tradeoff
Jan 17, 2023Existing salient object detection methods often adopt deeper and wider networks for better performance, resulting in heavy computational burden and slow inference speed. This inspires us to rethink saliency detection to achieve a favorable balance between efficiency and accuracy. To this end, we design a lightweight framework while maintaining satisfying competitive accuracy. Specifically, we propose a novel trilateral decoder framework by decoupling the U-shape structure into three complementary branches, which are devised to confront the dilution of semantic context, loss of spatial structure and absence of boundary detail, respectively. Along with the fusion of three branches, the coarse segmentation results are gradually refined in structure details and boundary quality. Without adding additional learnable parameters, we further propose Scale-Adaptive Pooling Module to obtain multi-scale receptive filed. In particular, on the premise of inheriting this framework, we rethink the relationship among accuracy, parameters and speed via network depth-width tradeoff. With these insightful considerations, we comprehensively design shallower and narrower models to explore the maximum potential of lightweight SOD. Our models are purposed for different application environments: 1) a tiny version CTD-S (1.7M, 125FPS) for resource constrained devices, 2) a fast version CTD-M (12.6M, 158FPS) for speed-demanding scenarios, 3) a standard version CTD-L (26.5M, 84FPS) for high-performance platforms. Extensive experiments validate the superiority of our method, which achieves better efficiency-accuracy balance across five benchmarks.
Pyramid Grafting Network for One-Stage High Resolution Saliency Detection
Apr 12, 2022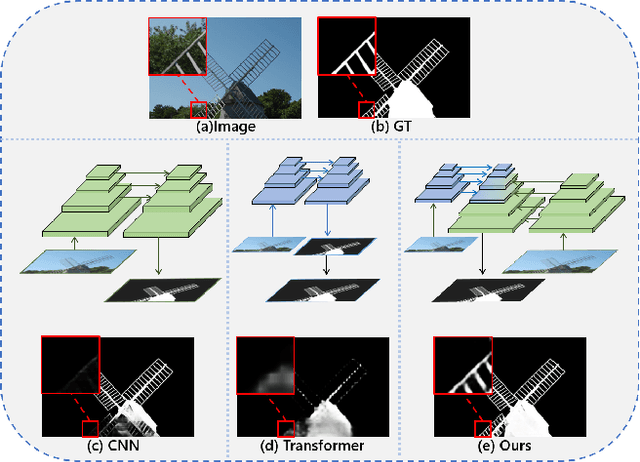


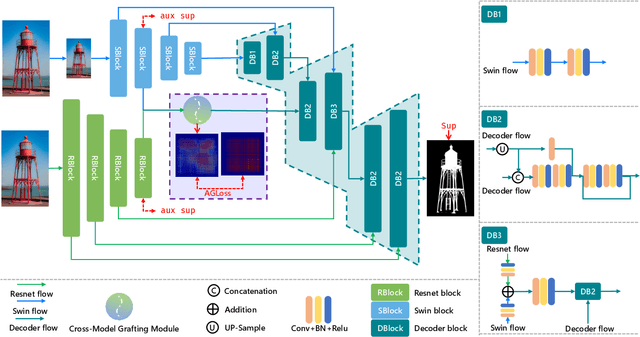
Recent salient object detection (SOD) methods based on deep neural network have achieved remarkable performance. However, most of existing SOD models designed for low-resolution input perform poorly on high-resolution images due to the contradiction between the sampling depth and the receptive field size. Aiming at resolving this contradiction, we propose a novel one-stage framework called Pyramid Grafting Network (PGNet), using transformer and CNN backbone to extract features from different resolution images independently and then graft the features from transformer branch to CNN branch. An attention-based Cross-Model Grafting Module (CMGM) is proposed to enable CNN branch to combine broken detailed information more holistically, guided by different source feature during decoding process. Moreover, we design an Attention Guided Loss (AGL) to explicitly supervise the attention matrix generated by CMGM to help the network better interact with the attention from different models. We contribute a new Ultra-High-Resolution Saliency Detection dataset UHRSD, containing 5,920 images at 4K-8K resolutions. To our knowledge, it is the largest dataset in both quantity and resolution for high-resolution SOD task, which can be used for training and testing in future research. Sufficient experiments on UHRSD and widely-used SOD datasets demonstrate that our method achieves superior performance compared to the state-of-the-art methods.