 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Vision Co-Instructed Image Editing
Jun 15, 2026Existing image editing methods can be generally categorized into textual instruction-based and visual prompt-based ones. Textual instructions are semantically expressive, but are limited by the coarse granularity of spatial control of the editing results. In contrast, visual prompts such as drag and point can provide precise spatial guidance, but are limited by the inherent ambiguity in semantic intent. To unify the strength of textual and visual prompts, we present Text-Vision Co-Instructed Image Editing, which jointly models textual instructions as semantic intent and sparse visual instructions as spatial guidance, aiming to achieve precise and intent-faithful image manipulation. To this end, we first construct a textual-visual instruction paired dataset with more than 23K samples derived from dynamic videos, enabling aligned supervision for cross-modal instruction. We then propose TV-Edit, a Textual-Visual instruction unified Editing framework to contextualize drag or point-based visual instructions with image-text semantics and lift them into semantic-aware control representations for pretrained editing backbones. By integrating semantic intent and spatial constraints, TV-Edit leads to more precise spatial control, less instruction ambiguity, and stronger structural consistency than text-only or drag-based alternatives. Finally, we establish TV-Edit-Bench, a deliberately designed benchmark to evaluate semantic faithfulness, spatial alignment, and visual consistency with ground-truth references and controlled textual-visual variations for reliable assessment. Our experiments across multiple editing backbones demonstrate that TV-Edit consistently yields more precise and intent-faithful edits, significantly outperforming state-of-the-art instruction-based and drag-based baselines.
CoCoEdit: Content-Consistent Image Editing via Region Regularized Reinforcement Learning
Feb 15, 2026Image editing has achieved impressive results with the development of large-scale generative models. However, existing models mainly focus on the editing effects of intended objects and regions, often leading to unwanted changes in unintended regions. We present a post-training framework for Content-Consistent Editing (CoCoEdit) via region regularized reinforcement learning. We first augment existing editing datasets with refined instructions and masks, from which 40K diverse and high quality samples are curated as training set. We then introduce a pixel-level similarity reward to complement MLLM-based rewards, enabling models to ensure both editing quality and content consistency during the editing process. To overcome the spatial-agnostic nature of the rewards, we propose a region-based regularizer, aiming to preserve non-edited regions for high-reward samples while encouraging editing effects for low-reward samples. For evaluation, we annotate editing masks for GEdit-Bench and ImgEdit-Bench, introducing pixel-level similarity metrics to measure content consistency and editing quality. Applying CoCoEdit to Qwen-Image-Edit and FLUX-Kontext, we achieve not only competitive editing scores with state-of-the-art models, but also significantly better content consistency, measured by PSNR/SSIM metrics and human subjective ratings.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
InsViE-1M: Effective Instruction-based Video Editing with Elaborate Dataset Construction
Mar 26, 2025

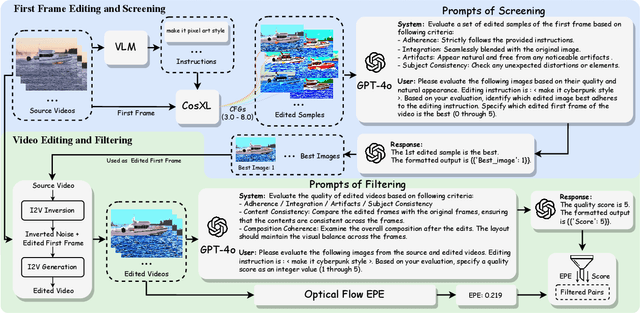

Instruction-based video editing allows effective and interactive editing of videos using only instructions without extra inputs such as masks or attributes. However, collecting high-quality training triplets (source video, edited video, instruction) is a challenging task. Existing datasets mostly consist of low-resolution, short duration, and limited amount of source videos with unsatisfactory editing quality, limiting the performance of trained editing models. In this work, we present a high-quality Instruction-based Video Editing dataset with 1M triplets, namely InsViE-1M. We first curate high-resolution and high-quality source videos and images, then design an effective editing-filtering pipeline to construct high-quality editing triplets for model training. For a source video, we generate multiple edited samples of its first frame with different intensities of classifier-free guidance, which are automatically filtered by GPT-4o with carefully crafted guidelines. The edited first frame is propagated to subsequent frames to produce the edited video, followed by another round of filtering for frame quality and motion evaluation. We also generate and filter a variety of video editing triplets from high-quality images. With the InsViE-1M dataset, we propose a multi-stage learning strategy to train our InsViE model, progressively enhancing its instruction following and editing ability. Extensive experiments demonstrate the advantages of our InsViE-1M dataset and the trained model over state-of-the-art works. Codes are available at InsViE.
FiVE: A Fine-grained Video Editing Benchmark for Evaluating Emerging Diffusion and Rectified Flow Models
Mar 17, 2025Numerous text-to-video (T2V) editing methods have emerged recently, but the lack of a standardized benchmark for fair evaluation has led to inconsistent claims and an inability to assess model sensitivity to hyperparameters. Fine-grained video editing is crucial for enabling precise, object-level modifications while maintaining context and temporal consistency. To address this, we introduce FiVE, a Fine-grained Video Editing Benchmark for evaluating emerging diffusion and rectified flow models. Our benchmark includes 74 real-world videos and 26 generated videos, featuring 6 fine-grained editing types, 420 object-level editing prompt pairs, and their corresponding masks. Additionally, we adapt the latest rectified flow (RF) T2V generation models, Pyramid-Flow and Wan2.1, by introducing FlowEdit, resulting in training-free and inversion-free video editing models Pyramid-Edit and Wan-Edit. We evaluate five diffusion-based and two RF-based editing methods on our FiVE benchmark using 15 metrics, covering background preservation, text-video similarity, temporal consistency, video quality, and runtime. To further enhance object-level evaluation, we introduce FiVE-Acc, a novel metric leveraging Vision-Language Models (VLMs) to assess the success of fine-grained video editing. Experimental results demonstrate that RF-based editing significantly outperforms diffusion-based methods, with Wan-Edit achieving the best overall performance and exhibiting the least sensitivity to hyperparameters. More video demo available on the anonymous website: https://sites.google.com/view/five-benchmark
PGNeXt: High-Resolution Salient Object Detection via Pyramid Grafting Network
Aug 02, 2024



We present an advanced study on more challenging high-resolution salient object detection (HRSOD) from both dataset and network framework perspectives. To compensate for the lack of HRSOD dataset, we thoughtfully collect a large-scale high resolution salient object detection dataset, called UHRSD, containing 5,920 images from real-world complex scenarios at 4K-8K resolutions. All the images are finely annotated in pixel-level, far exceeding previous low-resolution SOD datasets. Aiming at overcoming the contradiction between the sampling depth and the receptive field size in the past methods, we propose a novel one-stage framework for HR-SOD task using pyramid grafting mechanism. In general, transformer-based and CNN-based backbones are adopted to extract features from different resolution images independently and then these features are grafted from transformer branch to CNN branch. An attention-based Cross-Model Grafting Module (CMGM) is proposed to enable CNN branch to combine broken detailed information more holistically, guided by different source feature during decoding process. Moreover, we design an Attention Guided Loss (AGL) to explicitly supervise the attention matrix generated by CMGM to help the network better interact with the attention from different branches. Comprehensive experiments on UHRSD and widely-used SOD datasets demonstrate that our method can simultaneously locate salient object and preserve rich details, outperforming state-of-the-art methods. To verify the generalization ability of the proposed framework, we apply it to the camouflaged object detection (COD) task. Notably, our method performs superior to most state-of-the-art COD methods without bells and whistles.
Rethinking Lightweight Salient Object Detection via Network Depth-Width Tradeoff
Jan 17, 2023Existing salient object detection methods often adopt deeper and wider networks for better performance, resulting in heavy computational burden and slow inference speed. This inspires us to rethink saliency detection to achieve a favorable balance between efficiency and accuracy. To this end, we design a lightweight framework while maintaining satisfying competitive accuracy. Specifically, we propose a novel trilateral decoder framework by decoupling the U-shape structure into three complementary branches, which are devised to confront the dilution of semantic context, loss of spatial structure and absence of boundary detail, respectively. Along with the fusion of three branches, the coarse segmentation results are gradually refined in structure details and boundary quality. Without adding additional learnable parameters, we further propose Scale-Adaptive Pooling Module to obtain multi-scale receptive filed. In particular, on the premise of inheriting this framework, we rethink the relationship among accuracy, parameters and speed via network depth-width tradeoff. With these insightful considerations, we comprehensively design shallower and narrower models to explore the maximum potential of lightweight SOD. Our models are purposed for different application environments: 1) a tiny version CTD-S (1.7M, 125FPS) for resource constrained devices, 2) a fast version CTD-M (12.6M, 158FPS) for speed-demanding scenarios, 3) a standard version CTD-L (26.5M, 84FPS) for high-performance platforms. Extensive experiments validate the superiority of our method, which achieves better efficiency-accuracy balance across five benchmarks.
Pyramid Grafting Network for One-Stage High Resolution Saliency Detection
Apr 12, 2022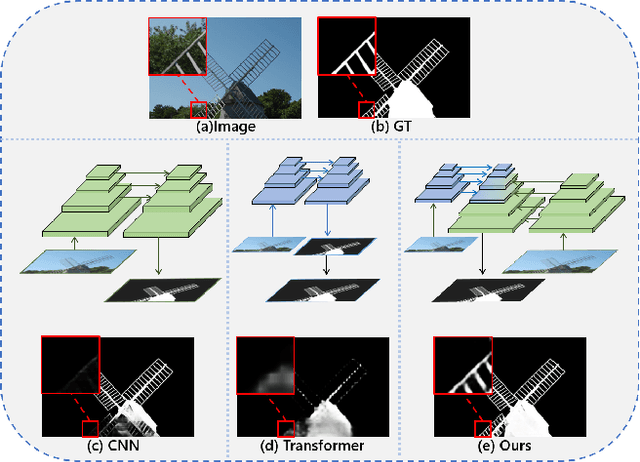


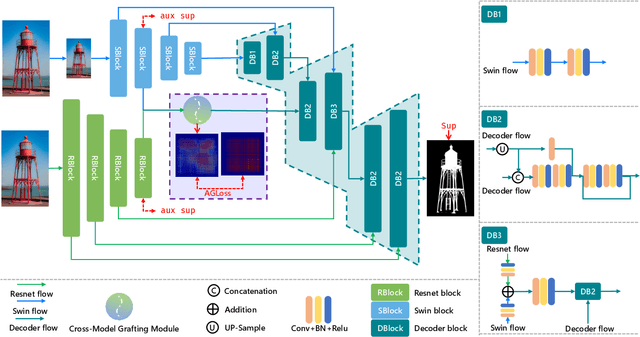
Recent salient object detection (SOD) methods based on deep neural network have achieved remarkable performance. However, most of existing SOD models designed for low-resolution input perform poorly on high-resolution images due to the contradiction between the sampling depth and the receptive field size. Aiming at resolving this contradiction, we propose a novel one-stage framework called Pyramid Grafting Network (PGNet), using transformer and CNN backbone to extract features from different resolution images independently and then graft the features from transformer branch to CNN branch. An attention-based Cross-Model Grafting Module (CMGM) is proposed to enable CNN branch to combine broken detailed information more holistically, guided by different source feature during decoding process. Moreover, we design an Attention Guided Loss (AGL) to explicitly supervise the attention matrix generated by CMGM to help the network better interact with the attention from different models. We contribute a new Ultra-High-Resolution Saliency Detection dataset UHRSD, containing 5,920 images at 4K-8K resolutions. To our knowledge, it is the largest dataset in both quantity and resolution for high-resolution SOD task, which can be used for training and testing in future research. Sufficient experiments on UHRSD and widely-used SOD datasets demonstrate that our method achieves superior performance compared to the state-of-the-art methods.
Receptive Field Broadening and Boosting for Salient Object Detection
Oct 15, 2021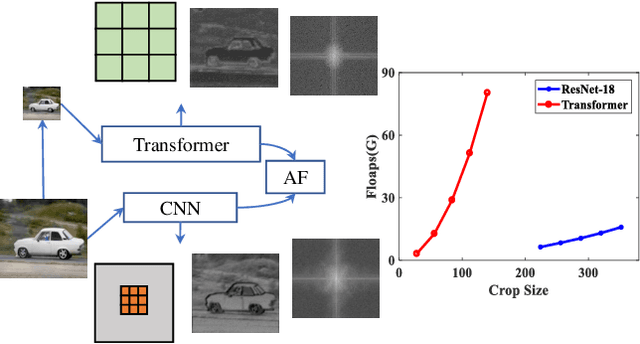
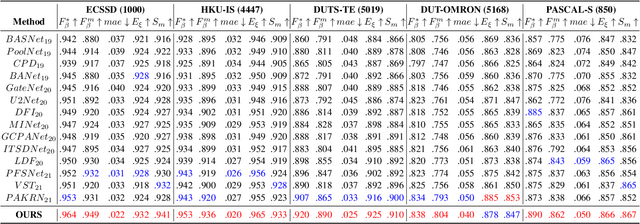
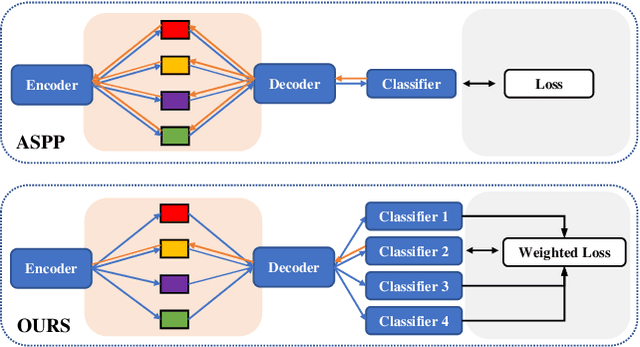
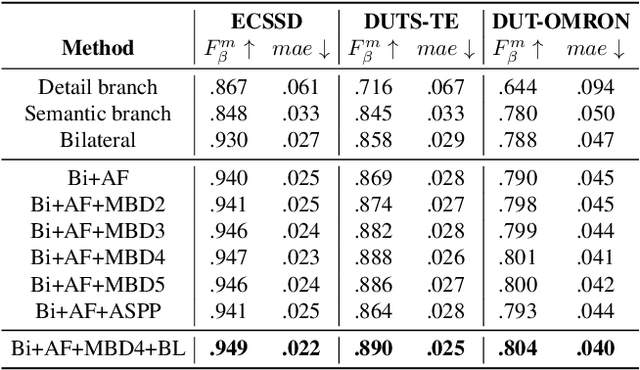
Salient object detection requires a comprehensive and scalable receptive field to locate the visually significant objects in the image. Recently, the emergence of visual transformers and multi-branch modules has significantly enhanced the ability of neural networks to perceive objects at different scales. However, compared to the traditional backbone, the calculation process of transformers is time-consuming. Moreover, different branches of the multi-branch modules could cause the same error back propagation in each training iteration, which is not conducive to extracting discriminative features. To solve these problems, we propose a bilateral network based on transformer and CNN to efficiently broaden local details and global semantic information simultaneously. Besides, a Multi-Head Boosting (MHB) strategy is proposed to enhance the specificity of different network branches. By calculating the errors of different prediction heads, each branch can separately pay more attention to the pixels that other branches predict incorrectly. Moreover, Unlike multi-path parallel training, MHB randomly selects one branch each time for gradient back propagation in a boosting way. Additionally, an Attention Feature Fusion Module (AF) is proposed to fuse two types of features according to respective characteristics. Comprehensive experiments on five benchmark datasets demonstrate that the proposed method can achieve a significant performance improvement compared with the state-of-the-art methods.