 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReceptive Field Broadening and Boosting for Salient Object Detection
Paper and Code
Oct 15, 2021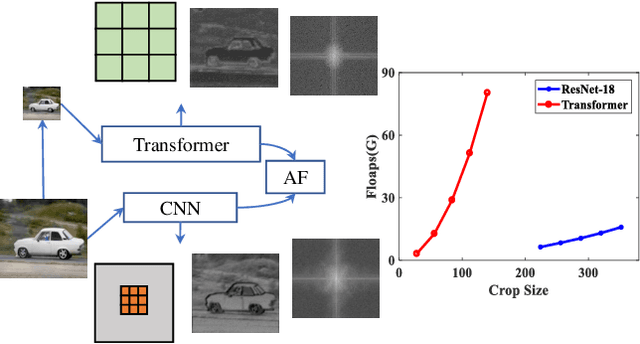
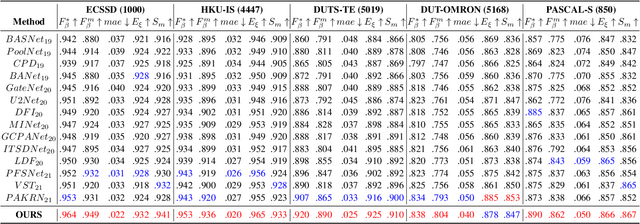
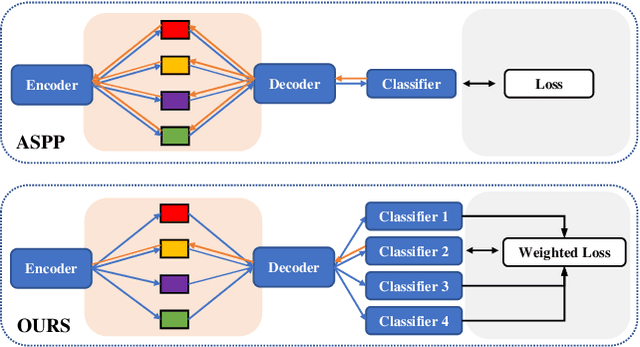
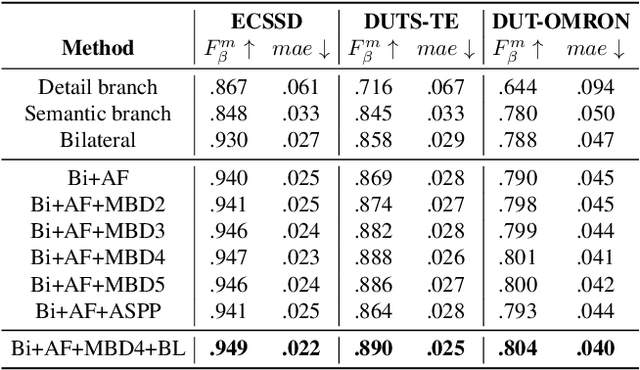
Salient object detection requires a comprehensive and scalable receptive field to locate the visually significant objects in the image. Recently, the emergence of visual transformers and multi-branch modules has significantly enhanced the ability of neural networks to perceive objects at different scales. However, compared to the traditional backbone, the calculation process of transformers is time-consuming. Moreover, different branches of the multi-branch modules could cause the same error back propagation in each training iteration, which is not conducive to extracting discriminative features. To solve these problems, we propose a bilateral network based on transformer and CNN to efficiently broaden local details and global semantic information simultaneously. Besides, a Multi-Head Boosting (MHB) strategy is proposed to enhance the specificity of different network branches. By calculating the errors of different prediction heads, each branch can separately pay more attention to the pixels that other branches predict incorrectly. Moreover, Unlike multi-path parallel training, MHB randomly selects one branch each time for gradient back propagation in a boosting way. Additionally, an Attention Feature Fusion Module (AF) is proposed to fuse two types of features according to respective characteristics. Comprehensive experiments on five benchmark datasets demonstrate that the proposed method can achieve a significant performance improvement compared with the state-of-the-art methods.