 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramid Grafting Network for One-Stage High Resolution Saliency Detection
Paper and Code
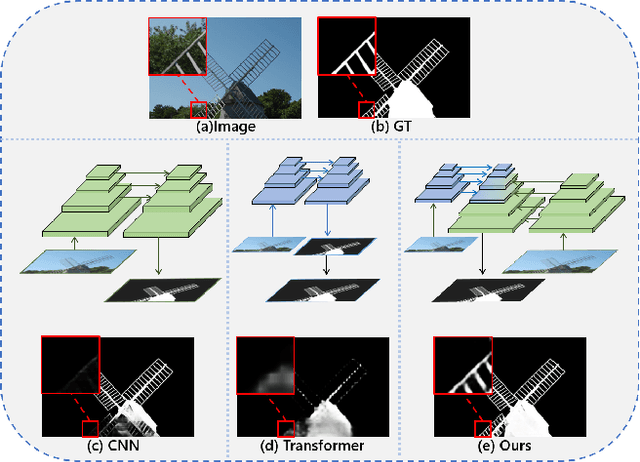


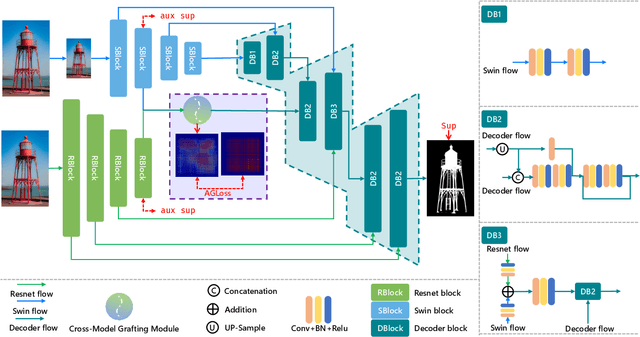
Recent salient object detection (SOD) methods based on deep neural network have achieved remarkable performance. However, most of existing SOD models designed for low-resolution input perform poorly on high-resolution images due to the contradiction between the sampling depth and the receptive field size. Aiming at resolving this contradiction, we propose a novel one-stage framework called Pyramid Grafting Network (PGNet), using transformer and CNN backbone to extract features from different resolution images independently and then graft the features from transformer branch to CNN branch. An attention-based Cross-Model Grafting Module (CMGM) is proposed to enable CNN branch to combine broken detailed information more holistically, guided by different source feature during decoding process. Moreover, we design an Attention Guided Loss (AGL) to explicitly supervise the attention matrix generated by CMGM to help the network better interact with the attention from different models. We contribute a new Ultra-High-Resolution Saliency Detection dataset UHRSD, containing 5,920 images at 4K-8K resolutions. To our knowledge, it is the largest dataset in both quantity and resolution for high-resolution SOD task, which can be used for training and testing in future research. Sufficient experiments on UHRSD and widely-used SOD datasets demonstrate that our method achieves superior performance compared to the state-of-the-art methods.